[논문리뷰] Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ming Qian, Zimin Xia, Changkun Liu, Shuailei Ma, Wen Wang, Zeran Ke, Bin Tan, Hang Zhang, Gui-Song Xia
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sat3DGen: 본 연구에서 제안하는 단일 위성 이미지 기반의 3D 스트리트 뷰 장면 생성 프레임워크입니다.
- Feed-Forward: 별도의 최적화 과정 없이 단일 패스(pass)만으로 3D 자산을 재구성하는 모델 구조를 의미합니다.
- Tri-plane NeRF: 3D 공간을 효율적으로 표현하기 위해 3개의 직교 평면(X-Y, X-Z, Y-Z)에 특징을 투영하여 볼륨 렌더링을 수행하는 기법입니다.
- Gravity-based Density Variation Loss: 중력 방향(연직 하향)으로 밀도가 증가하고 상향으로 감소해야 한다는 물리적 직관을 이용하여 3D 모델의 구조적 결함을 보정하는 손실 함수입니다.
- Spatial Token: 위성 이미지의 경계면 밖까지 포함하는 3D 영역을 생성하기 위해 도입된 패딩 토큰입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 단일 위성 이미지만으로 고품질의 3D 스트리트 뷰 장면을 생성하는 데 따르는 기하학적 정밀도 문제를 해결하는 것을 목표로 합니다. 기존 연구들은 건물 위주의 기하학적 형상만 생성하거나, 프록시 기반 모델을 통해 holistic한 장면을 구현하더라도 지면 경계와 옥상 등에서 기하학적 왜곡과 노이즈(floating artifacts)가 심각하게 발생하는 한계가 있습니다. 이러한 기하학적 실패는 위성 이미지와 스트리트 뷰 간의 극단적인 시점 차이(viewpoint gap)와 부족한 지도 학습 데이터로 인한 정보의 희소성(sparse supervision)에서 기인합니다. 따라서 저자들은 기존 피드포워드(feed-forward) 구조의 한계를 극복하기 위해 기하학적 제약 조건을 강화한 새로운 방법론을 제안합니다 [Figure 1].

Figure 1 — 기존 방법론과 제안 모델 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 geometry-first 방법론을 도입하여, Gravity-based Density Variation Loss를 통해 수직 구조물의 붕괴를 방지하고, Monocular Relative-Depth Prior를 사용하여 옥상의 입체적 모호성을 해결합니다 [Figure 2]. 또한, Spatial Token을 적용하여 위성 뷰의 경계를 넘어선 영역의 기하학적 안정성을 확보했으며, 파노라마 이미지를 다양한 시점으로 투영하여 학습하는 Perspective View Training 전략을 통해 시점 커버리지를 densify하였습니다. 제안하는 방법론은 VIGOR-OOD 데이터셋에서 기존 최첨단 기법인 Sat2Density++ 대비 기하학적 RMSE(Root Mean Square Error)를 6.76m에서 5.20m로 크게 개선하였습니다. 또한, FID(Fréchet Inception Distance) 점수는 기존 ∼40에서 19로 감소하여, 별도의 이미지 품질 모듈 없이도 실사적인 렌더링 성능을 입증하였습니다 [Table 1], [Figure 3]. 이러한 결과는 본 모델이 대규모 3D 메쉬 생성, 의미론적 지도(semantic map) 기반의 3D 합성, 다중 카메라 동영상 생성 등 다양한 Downstream Application에서 우수한 성능을 발휘함을 보여줍니다 [Figure 4].
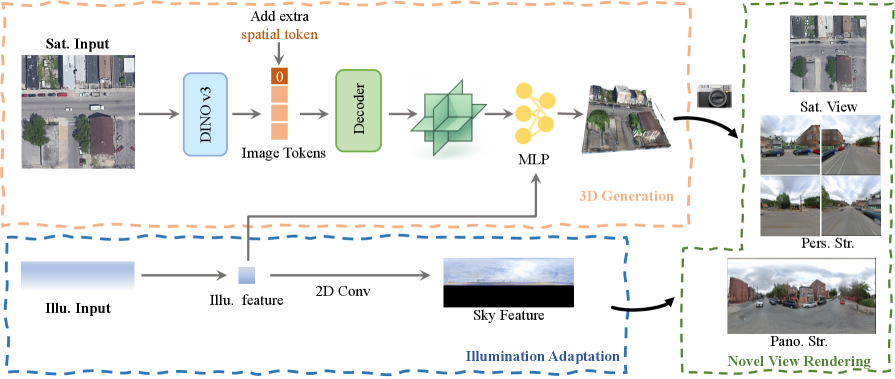
Figure 2 — Sat3DGen 아키텍처

Figure 4 — 생성 결과 및 시각화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 단일 위성 이미지로부터 기하학적으로 정교한 3D 스트리트 뷰 장면을 생성하는 Sat3DGen을 제안하였습니다. 논문에서 제안한 핵심 기하학적 손실 함수와 학습 전략은 데이터셋이 부족한 outdoor 환경에서도 높은 구조적 일관성과 photorealism을 달성함을 증명했습니다. 이 연구는 자율 주행 시뮬레이션, 디지털 트윈(Digital Earth), 도시 계획 등 다양한 지리 공간 정보 분야에 강력한 3D 기반 프레임워크를 제공하여 해당 산업계의 효율성을 크게 증대시킬 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CGGS: Consistency-Augmented Geometric Gaussian Splatting for Ego-centric 3D Scene Generation
- [논문리뷰] SynCity 3000: Bootstrapping Scene-Scale 3D Diffusion
- [논문리뷰] PixWorld: Unifying 3D Scene Generation and Reconstruction in Pixel Space
- [논문리뷰] TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
- [논문리뷰] FLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation
Review 의 다른글
- 이전글 [논문리뷰] STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?
- 현재글 : [논문리뷰] Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
- 다음글 [논문리뷰] Self-Distilled Agentic Reinforcement Learning
댓글