[논문리뷰] FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
링크: 논문 PDF로 바로 열기
메타데이터
저자: Thuan Hoang Nguyen, Jiahao Luo, Yinyu Nie, Hao Li, Gordon Guocheng Qian, Jian Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- FFAvatar: Few-shot, Feed-Forward, Generalizable Avatar Reconstruction의 약자로, 다수의 비포즈(unposed) portrait 이미지로부터 animatable 3D Gaussian head avatar를 실시간으로 재구성하는 프레임워크입니다.
- Multi-View Query-Former: 여러 시점의 이미지 정보를 통합하여 일관된 canonical Gaussian representation을 생성하는 핵심 아키텍처 모듈입니다.
- FLAME Estimator: 외부의 사전 처리(preprocessing) 없이 raw pixel로부터 FLAME expression, articulation, head pose를 직접 예측하는 학습 가능한 모듈입니다.
- Few-to-Many Objective: 적은 수의 conditioning view로부터 입력받아 다양한 타겟 시점과 표현을 생성하도록 모델을 학습시키는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 3D avatar 재구성 기법들이 요구하는 과도한 연산 시간과 복잡한 사전 처리의 한계를 극복하기 위해 FFAvatar를 제안한다. 기존의 Optimization-based 기법들은 개별 대상(subject)마다 수 시간의 최적화가 필요하여 실용성이 낮으며, 최신 Feed-forward 기법인 LAM은 단일 시점 입력에 의존하여 기하학적 일관성이 부족하고 외부의 FLAME 매개변수 추정 파이프라인에 의존하는 제약이 있다 [Figure 1]. 이러한 문제들은 확장 가능한 대규모 데이터 학습을 방해하고, 보이지 않는 시점이나 피사체에 대한 일반화 성능을 저하시키는 원인이 된다. 저자들은 이러한 한계를 극복하기 위해 다중 시점 입력을 활용하고 End-to-End로 학습 가능한 아키텍처를 구축하고자 한다.

Figure 1 — FFAvatar 전체 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 3단계 학습 커리큘럼(Scalable Pretraining, Multi-view Fine-tuning, Optional Personalization)을 통해 일반화와 고충실도 재구성을 동시에 달성하는 FFAvatar를 제안한다 [Figure 2]. 제안 모델은 Multi-view Query-Former를 통해 다수의 unposed 이미지에서 정보를 집계하고, FLAME Estimator를 통해 외부 파이프라인 없이 즉각적으로 애니메이션 매개변수를 추출한다 [Figure 3]. NeRSemble 벤치마크 실험 결과, FFAvatar는 LAM 대비 PSNR에서 5.5의 상당한 성능 향상을 기록하였다 [Table 1]. 특히, 4개 시점을 입력으로 사용할 경우 1개 시점 대비 PSNR이 추가적으로 개선되며, 단 500 steps의 선택적 Personalization을 통해 매우 높은 수준의 ID 보존 성능(CSIM 향상)을 확보한다. 이는 최신 방법론들과 비교하여 기하학적 일관성과 텍스처 디테일에서 압도적인 우위를 점함을 보여준다 [Figure 4, 5].

Figure 2 — 3단계 학습 커리큘럼
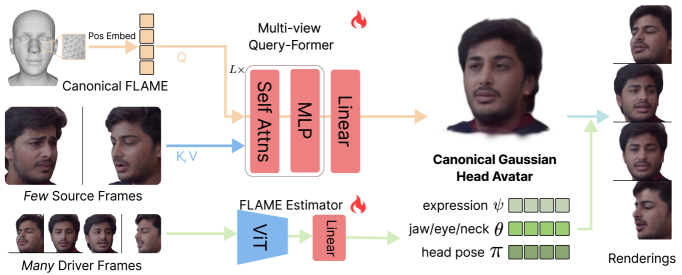
Figure 3 — FFAvatar의 아키텍처 세부 구성
4. Conclusion & Impact (결론 및 시사점)
본 논문은 적은 수의 이미지로부터 신속하게 고품질의 애니메이션 가능한 3D head avatar를 생성하는 FFAvatar를 제안하여 실시간 아바타 재구성의 새로운 기준을 제시한다. 저자들이 제안한 End-to-End 학습 방식과 효율적인 3단계 학습 전략은 향후 디지털 휴먼 생성 및 텔레프레젠스 분야의 확장성에 크게 기여할 것으로 기대된다. 또한, 초당 49 FPS의 애니메이션 속도를 실현함으로써 실시간 배포가 가능한 강력한 아바타 솔루션으로서의 가능성을 입증하였다. 이 연구는 복잡한 전처리 없이도 일반화된 3D 모델 생성이 가능함을 보여줌으로써, 관련 학계와 산업계의 디지털 휴먼 제작 프로세스를 대폭 간소화하는 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
- [논문리뷰] F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
- [논문리뷰] Frequency-Adaptive Sharpness Regularization for Improving 3D Gaussian Splatting Generalization
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Image2Sim: Scaling Embodied Navigation via Generative Neural Simulator
Review 의 다른글
- 이전글 [논문리뷰] Efficient Image Synthesis with Sphere Latent Encoder
- 현재글 : [논문리뷰] FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
- 다음글 [논문리뷰] FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
댓글