[논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sharareh Younesian, Wenwen Ouyang, Sina Rafati, Mehdi Rezagholizadeh, Sharon Zhou, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- AgentKernelArena: GPU 커널 최적화 에이전트의 성능과 범용성을 평가하기 위해 설계된 오픈 소스 벤치마크 프레임워크입니다.
- Unseen-configuration Generalization: 최적화 과정에서 에이전트가 학습하지 못한 입력 구성(input shapes)에서도 커널 최적화가 올바르게 작동하고 성능 향상을 유지하는지 평가하는 프로토콜입니다.
- Gated Compilation Pipeline: 커널을 Compile, Correctness 검사, Performance 프로파일링 순으로 평가하는 엄격한 파이프라인으로, 각 단계가 통과되어야 다음 단계가 진행됩니다 [Figure 1].
- Speedup Ratio ($s_k$): 기준 커널($t_{\text{baseline}}$) 대비 최적화된 커널($t_{\text{optimized}}$)의 실행 시간 비율($t_{\text{baseline}}/t_{\text{optimized}}$)을 의미합니다.
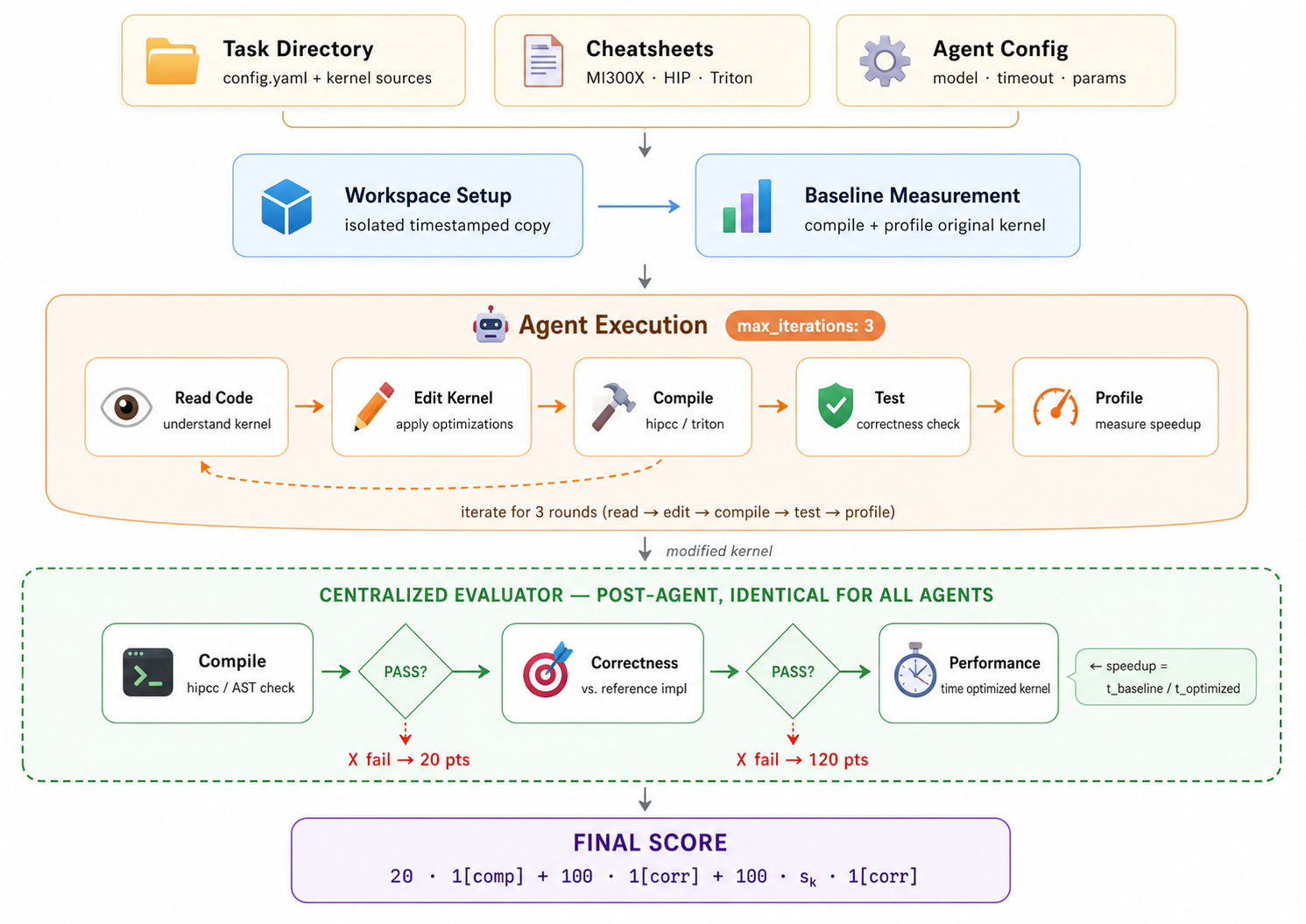
Figure 1 — AgentKernelArena 평가 파이프라인
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 GPU 커널 최적화 작업이 딥러닝 시스템의 효율성에 핵심적임에도 불구하고, 기존 벤치마크들이 이를 충분히 포괄하지 못한다는 문제 의식에서 출발합니다. 기존 연구들은 주로 단일 LLM 호출을 통한 커널 생성을 평가할 뿐, 실제 엔지니어가 수행하는 반복적인 컴파일·테스트·프로파일링 과정을 포함하는 완전한 에이전트 워크플로우를 반영하지 못합니다 [Figure 1]. 또한, 기존 벤치마크는 특정 입력 구성에 과적합(Overfitting)될 위험이 있음에도 불구하고, 학습하지 않은 입력 구성에 대한 범용성(Generalization)을 체계적으로 검증하지 않는 한계가 있습니다. 이를 해결하기 위해 저자들은 GPU 커널 최적화 에이전트를 위한 표준화된 평가 환경인 AgentKernelArena를 제안합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) AgentKernelArena는 HIP-to-HIP(24개), Triton-to-Triton(148개), PyTorch-to-HIP(24개) 등 총 196개의 실제 GPU 워크로드 작업을 포함하며, 샌드박스 환경에서 에이전트의 자율적인 반복 최적화 과정을 평가합니다. 각 에이전트는 컴파일 성공 여부, 기능적 정확도, 그리고 평균 가속도(Mean Speedup)를 기준으로 중앙 집중식 점수 체계에 따라 평가받습니다 [Figure 1]. 실험 결과, 최상위 모델 구성은 PyTorch-to-HIP에서 최대 6.89×, HIP-to-HIP에서 6.69×, Triton-to-Triton에서 2.13×의 평균 가속도를 달성했습니다 [Table 2, 3, 4]. 특히, 학습하지 않은 입력 구성에 대한 테스트 결과, HIP-to-HIP 및 Triton-to-Triton 최적화는 잘 전이되지만, PyTorch-to-HIP의 경우 특정 입력 형상에 의존적인 코드 하드코딩으로 인해 정확도가 크게 하락하는 현상이 발견되었습니다 [Figure 3].
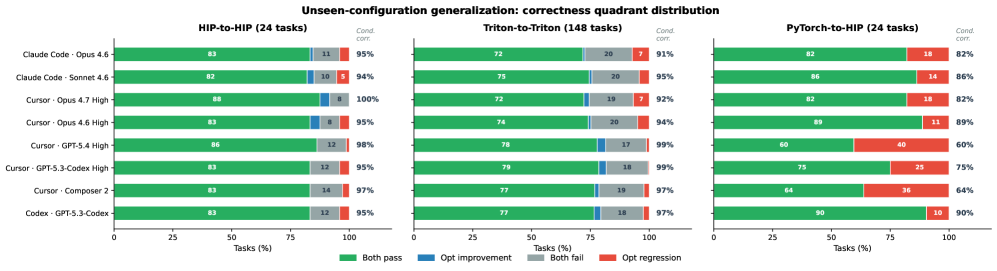
Figure 3 — 범용성 평가 사분면 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 GPU 커널 최적화 에이전트의 성능과 범용성을 객관적으로 측정하는 AgentKernelArena를 성공적으로 구축하였습니다. 연구 결과는 현재 생산 수준의 에이전트들이 높은 컴파일 성공률과 가속도를 보이지만, 여전히 입력 구성에 대한 과적합 위험이 존재함을 명확히 보여줍니다. 이 연구는 AI 기반 GPU 프로그래밍 도구 개발의 신뢰성을 높이고, 향후 에이전트 아키텍처가 실무 생산 환경에 도입되기 위한 엄격한 범용성 검증의 중요성을 강조하는 중요한 이정표가 될 것입니다.
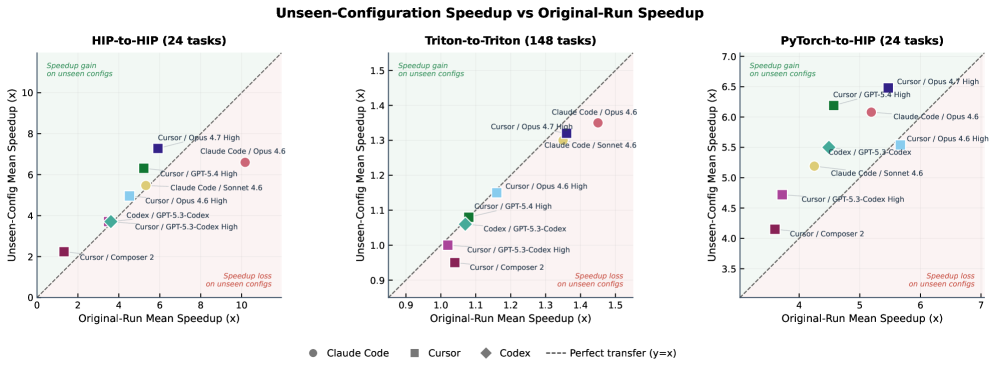
Figure 4 — 입력 구성 간 평균 가속도 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
- [논문리뷰] On Robustness and Reliability of Benchmark-Based Evaluation of LLMs
- [논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
- [논문리뷰] In-Context World Modeling for Robotic Control
- [논문리뷰] How Post-Training Shapes Biological Reasoning Models
Review 의 다른글
- 이전글 [논문리뷰] Agent Bazaar: Enabling Economic Alignment in Multi-Agent Marketplaces
- 현재글 : [논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
- 다음글 [논문리뷰] AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
댓글