[논문리뷰] A2RBench: An Automatic Paradigm for Formally Verifiable Abstract Reasoning Benchmark Generation
링크: 논문 PDF로 바로 열기
저자: Qingchuan Ma, Yuexiao Ma, Yongkang Xie, Tianyu Xie, Xiawu Zheng, Rongrong Ji
1. Key Terms & Definitions
- A2RBench: LLM의 추상적 추론 능력을 평가하기 위한 자동화된 pipeline으로, task 생성, 확장, 평가 및 분석을 포괄한다.
- Cycle Consistency Check: 생성된 task의 forward function
f와 inverse functiong사이의g(f(x)) = x관계를 프로그램적으로 검증하여 task의 uniqueness와 logical soundness를 보장하는 핵심 메커니즘이다. - Abstract Reasoning: LLM이 구체적인 instance로부터 일반화 가능한 패턴을 추출하고 이를 새로운 상황에 적용하는 능력으로, 단순한 패턴 매칭이 아닌 진정한 알고리즘적 추론을 의미한다.
- Symbolic Dependency Gap (As): symbolic task에서 symbol remapping 전후의 정확도 차이를 측정하는 metric으로, LLM이 추상적 구조보다 친숙한 symbol에 얼마나 의존하는지 정량화한다.
- Augmentation Paradox: 입력 정보 복잡성이 높은 task variation이 역설적으로 LLM의 추론 정확도를 높이는 현상으로, 이는 구조화된 입력이 규칙의 모호성을 줄여주기 때문으로 분석된다.
2. Motivation & Problem Statement
현재 Large Language Models (LLM)의 추상적 추론 능력 평가는 진정한 추론 요구와 벤치마크 확장성 사이의 근본적인 trade-off에 직면해 있다. 기존 대규모 데이터셋은 종종 단순한 암기를 측정할 위험이 있으며, 수동으로 설계된 Abstraction and Reasoning Corpus (ARC)와 같은 벤치마크는 진정한 추론을 요구하지만 규모가 제한적이다. 더욱이, LLM 기반의 task 생성 방식은 generative hallucination으로 인해 논리적으로 결함 있는 task를 생성할 수 있고, 모델이 피상적인 패턴 매칭을 넘어 진정한 규칙 유도를 수행하는지 판단하기 어렵다. 따라서, 본 연구는 LLM의 추상적 추론 능력을 정확하게 측정하고, 심층적인 진단적 통찰력을 제공하며, 확장 가능하고 다양하며 공식적으로 검증 가능한 벤치마크의 부재라는 핵심 문제를 해결하고자 한다.
3. Method & Key Results
본 논문은 LLM의 추상적 추론 능력을 평가하기 위한 자동화된 pipeline인 A2RBench를 제안한다. 제안된 방법론은 generation, expansion, evaluation, analysis의 4단계로 구성된다. 핵심적으로, 각 task는 forward function f와 inverse function g의 쌍으로 구현되며, Cycle Consistency Check (g(f(x)) = x)를 통해 task의 uniqueness와 logical soundness를 형식적으로 보장한다 [Figure 1]. 이 검증 과정을 통해 generative hallucination으로 인한 논리적 오류를 제거하고, 확장 가능한 방식으로 고품질 task를 생성한다.
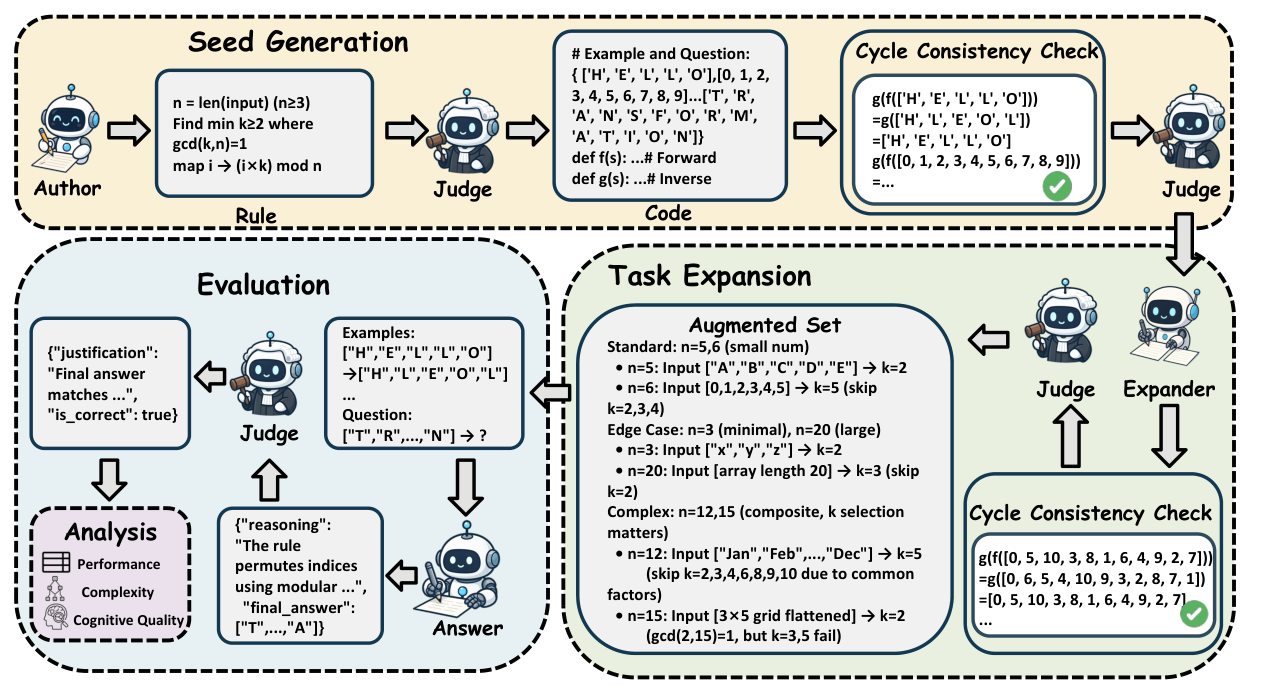
Figure 1 — 전체 방법론의 workflow와 각 단계의 역할을 시각적으로 보여주는 핵심 다이어그램
광범위한 LLM 평가 결과, 현재 LLM들은 추상적 추론에서 근본적인 결함을 보였다. 최고 성능 모델인 Gemini3-Pro는 전체 task에서 40.9%의 정확도를 달성했으나, 인간의 68.5%에 크게 못 미쳤다 [Table 1], [Table 11]. 특히, 모델의 실패는 주로 Abstraction Failure에 기인했으며, 정답을 맞춘 경우에도 상당수가 Surface Fitting이나 Inferior Rule에 의존하는 것으로 나타났다 [Figure 2]. Symbolic Dependency Gap (As) 분석에서는 GPT-5가 remapping된 task에서 17.7%의 성능 저하를 보이며 친숙한 symbol에 대한 과도한 의존성을 드러냈다 [Table 1]. 또한, 저자 모델은 3D task보다 2D task에서 일관되게 낮은 성능을 보였는데 [Figure 3], 이는 3D task 생성 시 저자 모델이 논리적 복잡성을 단순화하여 solver에게는 역설적으로 더 쉬워지는 Dimensionality Bottleneck 현상 때문으로 분석되었다 [Table 9]. 흥미롭게도, Augmentation Paradox는 입력 정보 복잡성이 높을수록 모델 정확도가 급격히 상승하는 경향을 보여주는데 [Figure 4], 이는 고도로 구조화된 입력이 규칙의 모호성을 줄여 추론 과정을 단순화할 수 있음을 시사한다. A2RBench는 task당 평균 $0.016의 비용으로, 수동 벤치마크 대비 수십 배의 경제적 효율성을 달성하여 확장성을 입증했다 [Table 3].

Table 1 — 다양한 LLM들의 전체적인 성능, symbolic dependency, generalization gap을 정량적으로 비교하는 핵심 결과 테이블
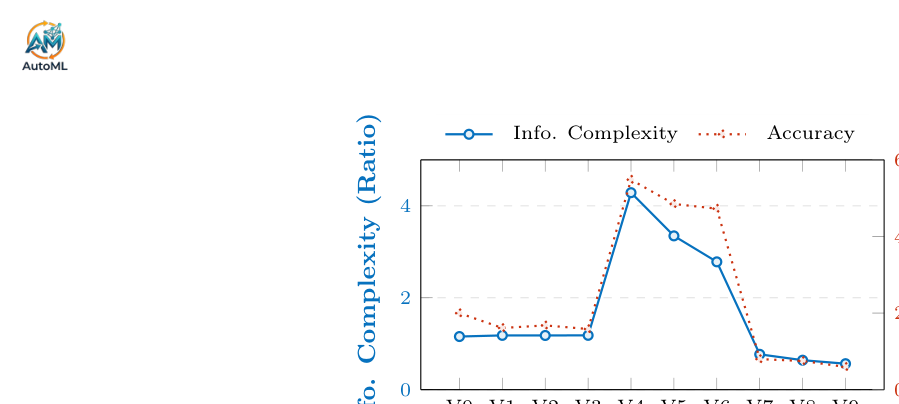
Figure 4 — input complexity와 model accuracy 간의 역설적인 관계를 보여주는 중요한 발견 (Augmentation Paradox)을 시각화
4. Conclusion & Impact
본 연구는 LLM 생성과 code verification을 결합한 자동화된 paradigm을 통해, LLM의 추상적 추론 능력 평가를 위한 확장 가능하고 공식적으로 검증 가능한 벤치마크 생성이라는 중요한 과제를 성공적으로 해결한다. Cycle Consistency (g(f(x)) = x)가 문제의 well-posedness를 보장한다는 이론적 프레임워크는 generative hallucination을 방지하고, task의 논리적 건전성을 deterministic하게 검증하는 기반을 제공한다. A2RBench는 현재 LLM의 추상적 추론 능력의 근본적인 한계, high-dimensional task 이해 부족, 그리고 역설적으로 높은 입력 복잡성이 추론 과정을 단순화할 수 있다는 점을 포함한 중요한 진단적 통찰력을 제공한다. 이러한 연구는 LLM의 진정한 인지 능력을 평가하는 새로운 표준을 제시하고, 향후 더욱 견고하고 일반화 가능한 인공지능 시스템 개발에 필요한 통찰력을 제공하여 머신러닝 분야 발전에 크게 기여할 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
- [논문리뷰] FVSpec: Real-World Property-Based Tests as Lean Challenges
- [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
- [논문리뷰] When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
- [논문리뷰] PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems
Review 의 다른글
- 이전글 [논문리뷰] WorldAct: Activating Monolithic 3D Worlds into Interactive-Ready Object-Centric Scenes
- 현재글 : [논문리뷰] A2RBench: An Automatic Paradigm for Formally Verifiable Abstract Reasoning Benchmark Generation
- 다음글 [논문리뷰] AI for Auto-Research: Roadmap & User Guide
댓글