[논문리뷰] Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
링크: 논문 PDF로 바로 열기
저자: Yixing Lao, Xuyang Bai, Xiaoyang Wu, Nuoyuan Yan, Zixin Luo, Tian Fang, Jean-Daniel Nahmias, Yanghai Tsin, Shiwei Li, Hengshuang Zhao et al.
Part 1: 요약 본문
1. Key Terms & Definitions (핵심 용어 및 정의)
- 3D Gaussian Splatting (3DGS) : 실시간 radiance field 렌더링을 위해 명시적 Gaussian primitive를 사용하는 기법입니다.
- Feed-Forward : per-scene optimization 없이 장면 표현을 직접 예측하는 모델 아키텍처를 지칭합니다.
- Textured Gaussians : 학습 가능한 per-primitive texture map (color
T^c, alphaT^α)이 추가되어 고주파(high-frequency) appearance detail을 표현하는 Gaussian primitive입니다. - Dual-network architecture : LGTM의 핵심 아키텍처로, geometry 예측을 위한
primitive network와 appearance 예측을 위한texture network로 구성됩니다. - Resolution Scalability Barrier : 해상도 증가에 따라 primitive 수가 quadratic하게 증가하여 고해상도 합성(예: 4K)을 제한하는 feed-forward 3DGS 방식의 근본적인 한계점입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 feed-forward 3D Gaussian Splatting (3DGS) 방법론들은 pixel-aligned primitive를 예측하므로, 해상도가 증가함에 따라 primitive의 수가 quadratic하게 증가하여 4K와 같은 고해상도(high-resolution) novel view synthesis를 실질적으로 불가능하게 만듭니다. 이는 네트워크 예측 및 Gaussian 렌더링에 엄청난 연산 및 메모리 비용을 초래합니다. 또한, 표준 3DGS는 각 primitive 내에서 appearance와 geometry를 tightly coupling하여, 기하학적으로 단순한 표면에서도 풍부한 texture 영역을 표현하기 위해 과도한 수의 Gaussian을 필요로 합니다.
현재 Textured Gaussian 방식들이 primitive 수를 줄이는 데 기여하지만, 이들은 여전히 per-scene optimization이 필요하며, feed-forward 방식으로 장면(scene) 간 generalization이 불가능하다는 한계가 있습니다. 저자들은 이러한 기존 연구의 한계를 극복하고, augmented reality(AR) 및 virtual reality(VR)와 같이 효율적인 성능과 높은 시각적 충실도(visual fidelity)를 요구하는 응용 분야를 위해, per-scene optimization 없이 고품질 4K novel view synthesis가 가능한 feed-forward 방식을 제안합니다. Pilot study 결과(Table 1)에 따르면, 기존 방법론인 NoPoSplat은 2K 또는 그 이상의 해상도에서 메모리 제약으로 인해 학습에 실패하는 반면, LGTM은 30GB 미만의 메모리로 2K 및 4K 학습에 성공하며 효율적인 scalability를 보입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
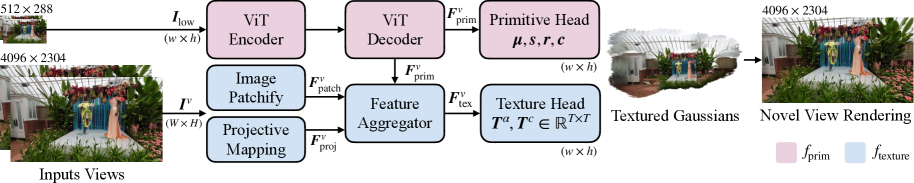
LGTM은 dual-network architecture를 사용하여 geometry와 appearance 예측을 decoupling하는 feed-forward 프레임워크를 제안합니다. 이 아키텍처는 primitive network와 texture network로 구성됩니다. primitive network(f_prim)는 저해상도(low-resolution) 이미지를 입력으로 받아 compact한 geometric primitive(위치 μ, 스케일 s, 회전 r, 기본 색상 c)를 예측합니다. 한편, texture network(f_texture)는 고해상도 이미지를 image patchification 및 projective mapping 네트워크를 통해 처리하여 per-primitive texture map(색상 T_i^c 및 알파 T_i^α)을 예측합니다. 이 texture network는 고해상도 이미지를 통한 local feature 추출, projective prior texture로부터의 고주파(high-frequency) texture detail 확보, 그리고 primitive network의 기하학적 특징(geometric features) 융합을 통해 상세한 texture를 생성합니다. 이 과정에서 bilinear sampling과 border clamping을 사용하여 texture 값을 가져옵니다.
LGTM은 2단계 학습 전략을 채택합니다. 첫 번째 단계에서는 primitive network를 독립적으로 학습시켜 견고한 기하학적 기반(geometric foundation)을 구축하고, 두 번째 단계에서는 두 네트워크를 jointly training하여 고주파 detail로 appearance를 풍부하게 합니다. 이 모델은 monocular, two-view, multi-view 등 다양한 input setting에서 적용 가능하며, camera pose 유무에 관계없이 작동합니다. LGTM의 전체 아키텍처는 이중 네트워크를 통해 기하학과 appearance를 분리하여 feed-forward 4K Gaussian splatting을 가능하게 합니다.
주요 실험 결과에 따르면, LGTM은 RE10K 및 DL3DV 데이터셋의 다양한 해상도(최대 4K)에서 3DGS 및 2DGS baseline (NoPoSplat, DepthSplat, Flash3D, VGGT) 대비 일관되게 우수한 성능을 보여줍니다. 예를 들어, DL3DV 데이터셋의 4K 해상도 two-view 설정에서 LGTM은 DepthSplat baseline과 함께 PSNR 25.508 , SSIM 0.827 을 달성하여, 3DGS (PSNR 24.740, SSIM 0.801) 및 2DGS (PSNR 24.715, SSIM 0.794)보다 우수한 정량적 결과를 보입니다. 특히, LGTM은 perceptual metric인 LPIPS에서 23%에서 75%까지의 현저한 개선을 보여, 시각적 품질 향상에 크게 기여합니다. Inference 성능 벤치마크 결과(Table 4)에 따르면, 512x288에서 4096x2304로 64배 픽셀 수가 증가하더라도 LGTM은 최대 메모리 사용량이 1.80배 , 총 소요 시간이 1.47배 증가하는 데 그쳐, 고해상도 스케일링에서 뛰어난 효율성을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고해상도 렌더링을 위한 textured Gaussians를 예측하는 최초의 feed-forward 네트워크인 LGTM을 소개합니다. LGTM은 기존 feed-forward 3DGS 방법론의 resolution scalability barrier를 성공적으로 극복하여, 메모리 제약으로 인해 4K novel view synthesis가 불가능했던 한계를 해결했습니다. LGTM의 geometry-appearance decoupling 방식은 훨씬 적은 수의 Gaussian primitive로 4K novel view synthesis를 가능하게 하며, 이는 이전에는 feed-forward 방식으로는 달성하기 어려웠던 capability입니다.
LGTM은 Flash3D, NoPoSplat, DepthSplat, VGGT 등 여러 baseline method에 걸쳐 일관된 성능 향상을 보여주며, 그 적용 가능성이 광범위함을 입증합니다. 픽셀 수 64배 증가 시 메모리 1.80배, 시간 1.47배 증가라는 효율성은 LGTM이 고성능과 고품질 시각적 fidelity를 동시에 요구하는 AR/VR과 같은 실제 응용 분야에서 중요한 진전을 가져올 것임을 시사합니다. 이 연구는 3D 장면 재구성 및 렌더링 분야에서 고해상도 feed-forward 방식을 위한 새로운 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
- [논문리뷰] UniSHARP: Universal Sharp Monocular View Synthesis
- [논문리뷰] ZipSplat: Fewer Gaussians, Better Splats
- [논문리뷰] FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
- [논문리뷰] MeshSplatting: Differentiable Rendering with Opaque Meshes
Review 의 다른글
- 이전글 [논문리뷰] Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
- 현재글 : [논문리뷰] Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
- 다음글 [논문리뷰] MACRO: Advancing Multi-Reference Image Generation with Structured Long-Context Data
댓글