[논문리뷰] Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
링크: 논문 PDF로 바로 열기
저자: Intern-S1-Pro Team Shanghai AI Laboratory
키워: Scientific Multimodal Foundation Model, Trillion Parameters, MoE, Reinforcement Learning, Scientific Discovery, Multimodal Reasoning, Agent Capabilities
1. Key Terms & Definitions (핵심 용어 및 정의)
- Mixture-of-Experts (MoE) : 모델의 capacity를 확장하기 위해 각 input token을 small subset의 expert로 라우팅하며, 오직 선택된 expert들만이 gradient update를 받는 아키텍처.
- Grouped Routing : MoE 모델의 Expert Parallelism training 시 발생하는 expert load imbalance 문제를 해결하고 training stability를 강화하기 위해 제안된 메커니즘.
- Straight-Through Estimator (STE) : MoE 라우팅 operation의 forward 및 backward pass를 decoupling하여, backpropagation 시 모든 expert embedding이 gradient update를 받을 수 있도록 하여 load balancing, convergence 속도, optimization stability를 개선하는 방법론.
- Fourier Position Encoding (FoPE) : Fourier analysis를 활용하여 tokens의 discrete particle nature와 물리적 신호의 continuous wave characteristics를 동시에 포착함으로써, multimodal data 처리를 위한 positional encoding의 한계를 극복하는 기법.
- Specializable Generalist : 충분히 큰 generalist 모델이 general 및 specific tasks에 대해 joint training될 때, specialized 모델을 능가하는 superior performance를 달성할 수 있음을 보여주는 개념.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)와 Visual Language Models (VLMs)의 등장은 인공지능 분야에 혁신을 가져왔지만, 과학 분야(AI for Science, AI4S)에서 효과적인 foundation model을 구축하는 것은 과학 domain의 immense diversity와 specialization으로 인해 큰 도전을 제시합니다. 화학, 생물학, 물리학, 지구과학 등 각 과학 분야는 고유한 'language'와 long-tailed knowledge를 포함하고 있어 기존 모델로는 그 깊이를 온전히 다루기 어렵습니다.
특히, Mixture-of-Experts (MoE) 모델을 trillion parameter 규모로 scaling할 경우, massive한 expert들 간의 load imbalance로 인한 training instability와 router embeddings 최적화의 어려움이 발생합니다. 또한, 과학 문헌에 있는 기존 image caption은 종종 간결하고 visual elements와의 명확한 alignment가 부족하여 VLM training에 한계가 있습니다. 마지막으로, scientific data와 general data를 통합할 때 발생하는 "distribution shift" 및 "negative transfer" 문제는 모델 inference 시 logical confusion을 야기할 수 있습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
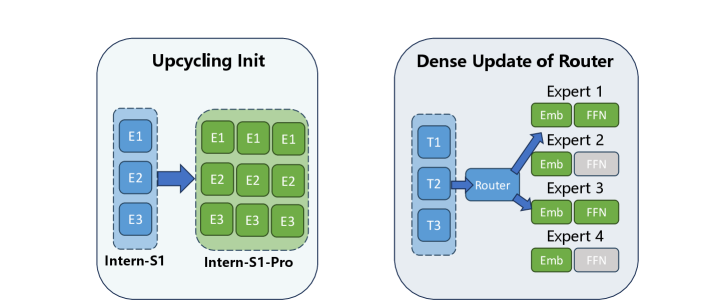
저자들은 이러한 문제들을 해결하기 위해 Intern-S1-Pro 를 제안하며, 이는 1-trillion-parameter 규모의 scientific multimodal foundation model입니다. 이 모델은 Intern-S1에서 expert expansion을 통해 파생되었으며, SAGE (Synergistic Architecture for Generalizable Experts) 프레임워크를 따릅니다
핵심 방법론은 다음과 같습니다: 첫째, MoE 모델의 training stability와 expert load balancing을 위해 Grouped Routing 메커니즘을 도입했습니다. 이는 expert들을 group으로 나누고 각 group 내에서 top expert를 선택하여 8-way Expert Parallelism training에서 absolute load balancing을 보장합니다 [Figure 3]. 둘째, router embeddings의 효율적인 학습을 위해 Straight-Through Estimator (STE) 를 활용하여, 모든 router embeddings가 backpropagation 시 gradient update를 받을 수 있도록 하여 load balancing을 개선하고 convergence 속도를 높입니다. 셋째, vision encoder로는 native resolution image 처리를 위한 Native Vision Transformer (ViT) 를 사용하며, 300 million image-text pairs 로 contrastive learning을 수행합니다. 넷째, multimodal data의 continuous wave characteristics를 포착하기 위해 Fourier Position Encoding (FoPE) 를 통합했습니다 [Figure 4]. 다섯째, 시간-계열 데이터 처리를 위해 adaptive subsampling module과 time series encoder를 포함하는 전용 time series module을 업그레이드하여 10^0에서 10^6 time steps 범위의 heterogeneous time series를 처리할 수 있게 합니다 [Figure 5].
Pre-training 단계에서는 6T tokens 의 image-text 및 text data를 활용했으며, 특히 과학 이미지에 특화된 고품질 caption 생성을 위한 dedicated caption pipeline 을 개발했습니다
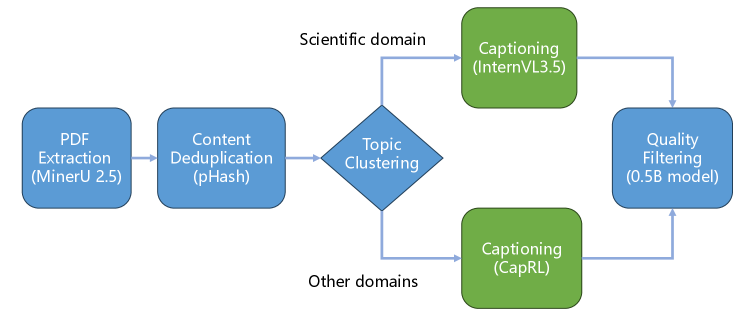
이 pipeline은 PDF 문서에서 sub-figure를 추출하고 MinerU2.5 , InternVL3.5-241B , CapRL-32B 등의 전문 VLM을 활용하여 270B tokens 규모의 고품질 scientific image-text caption data를 생성했습니다. Scientific data와 general data 간의 conflicts를 해결하기 위해 Structured Scientific Data Transformation , Scientific Data Diversification , System Prompt Isolation 전략도 구현했습니다. Post-training 단계에서는 FP8 quantization 과 함께 연산자 수준의 precision discrepancy 감소, rollout router replay, targeted mixed-precision scheme, dual importance sampling ratios를 포함하는 framework를 통해 sparse MoE 모델에서 stable Mixed-Precision Reinforcement Learning (RL) 을 달성했습니다 [Figure 8].
Intern-S1-Pro의 핵심 결과는 다음과 같습니다:
- Scientific Tasks : SciReasoner 벤치마크에서 55.5 점을 달성하여 proprietary models인 Gemini-3-Pro (14.7) 및 GPT-5.2 (13.6)를 크게 능가했습니다 [Table 2]. 또한 SmolInstruct (74.8) , MatBench (72.8) , Mol-Instructions (48.8) , Biology-Instruction (52.5) , XLRS-Bench (52.8) 등 다양한 과학 벤치마크에서 top score를 기록했습니다 [Table 2].
- Time Series : SciTS 벤치마크에서 EAU01 task의 F1 score 99.5 를 기록하며, Text LLMs 및 Vision-Language LLMs 대비 월등히 superior performance를 보였습니다 [Table 3].
- Specializable Generalist : 생물학 분야 case study에서 Intern-S1-Pro는 specialized model인 Biology-Instruction 대비 significantly better comprehensive performance를 보였으며, 특히 Protein-Fluorescence (78.14) task에서 Biology-Instruction (2.57)을 압도했습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Intern-S1-Pro , 즉 1-trillion-parameter 규모의 scientific multimodal foundation model을 소개하며, 이는 과학적 발견을 위한 AI의 frontiers를 발전시키는 데 기여합니다. 저자들은 Intern-S1의 견고한 기반 위에 novel expert expansion strategy와 Grouped Routing 을 결합하여 모델을 scaling함으로써, device 전반의 효율적인 load balancing과 training stability를 확보했습니다.
특히, 과학적 이미지에 특화된 dedicated caption pipeline의 개발은 기존 데이터셋의 한계를 극복하고 모델의 complex scientific visual content 해석 능력을 실질적으로 향상시켰습니다. 광범위한 평가를 통해 Intern-S1-Pro는 다양한 과학 및 general 벤치마크에서 state-of-the-art performance를 달성하며, robust reasoning capabilities와 deep domain knowledge를 입증했습니다.
이 연구는 "Specializable Generalist" 패러다임을 통해, 대규모 generalist 모델이 specialized scientific domains에서도 탁월한 성능을 발휘할 수 있음을 시사하며, general 및 specialized intelligence의 synergistic fusion을 촉진합니다. Intern-S1-Pro는 핵심 과학 분야의 scientific discovery 가속화를 위한 powerful, open-source foundation model로서 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] IQuest-Coder-V1 Technical Report
- 현재글 : [논문리뷰] Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
- 다음글 [논문리뷰] Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
댓글