[논문리뷰] MACRO: Advancing Multi-Reference Image Generation with Structured Long-Context Data
링크: 논문 PDF로 바로 열기
저자: Zhekai Chen, Yuqing Wang, et al.
키워: Multi-reference Image Generation, Long-Context Data, MacroData, MacroBench, Customization, Illustration, Spatial, Temporal, LLM-as-Judge
1. Key Terms & Definitions (핵심 용어 및 정의)
- MacroData : Multi-reference image generation을 위한 대규모(400K 샘플), 구조화된 long-context 데이터셋으로, 최대 10개의 reference image를 포함한다.
- MacroBench : MacroData와 함께 제안된 종합적인 벤치마크로, Customization, Illustration, Spatial, Temporal의 네 가지 task dimension과 1-10개 의 varying input scale에 걸쳐 generative coherence를 평가한다.
- Customization : 여러 reference image를 기반으로 일관성 있는 새로운 composition을 생성하는 task이다.
- Illustration : Multimodal context(텍스트 및 이미지)에 기반하여 설명을 보완하는 illustrative image를 생성하는 task이다.
- LLM-as-Judge : Gemini-3-Flash와 같은 대규모 언어 모델을 사용하여 생성된 이미지의 품질을 평가하는 메커니즘으로, task-specific criteria를 사용하여 context sensitivity 및 narrative adherence를 엄격하게 평가한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multi-reference image generation은 multi-subject composition, narrative illustration, novel view synthesis와 같은 실제 애플리케이션에 필수적이지만, 현재 모델들은 input reference의 수가 증가함에 따라 심각한 성능 저하를 겪고 있다. 기존 연구(Baseline)들은 대부분 single- 또는 few-reference pair에 치우쳐 있어, dense inter-reference dependencies 학습에 필요한 structured long-context supervision이 부족하다. 이로 인해 OmniGen2 나 Bagel 과 같은 모델들은 3-5개 이상의 input images에서 성능이 급격히 저하된다. 또한, multi-reference generation을 위한 표준화된 평가 프로토콜의 부재도 연구 발전을 저해하는 핵심적인 문제로 지적된다. 이러한 데이터 및 평가 환경의 한계를 극복하고 모델이 복잡한 multi-reference 시나리오를 효과적으로 처리할 수 있도록 새로운 접근 방식이 절실하다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 한계를 극복하기 위해 MacroData 와 MacroBench 를 제안한다. MacroData 는 400K 샘플 로 구성된 대규모 데이터셋으로, 각 샘플은 최대 10개 의 reference image를 포함하며, Customization , Illustration , Spatial , Temporal 의 네 가지 complementary dimension에 걸쳐 체계적으로 구성되어 multi-reference generation space를 포괄적으로 커버한다

데이터는 closed-source 모델의 지식을 증류하고 실제 corpora를 꼼꼼하게 필터링하는 robust pipeline을 통해 구축되어, 논리적 일관성과 시각적 fidelity를 보장한다. 이와 함께, MacroBench 는 4,000개 의 샘플로 구성된 종합적인 벤치마크로, graded task dimension과 input scale에 걸쳐 generative coherence를 평가하며, Gemini-3-Flash 기반의 LLM-as-Judge 메커니즘을 사용하여 context sensitivity 및 narrative adherence를 엄격하게 측정한다.
실험 결과, MacroData 로 fine-tuning한 모델은 multi-reference generation에서 상당한 성능 향상을 보였다
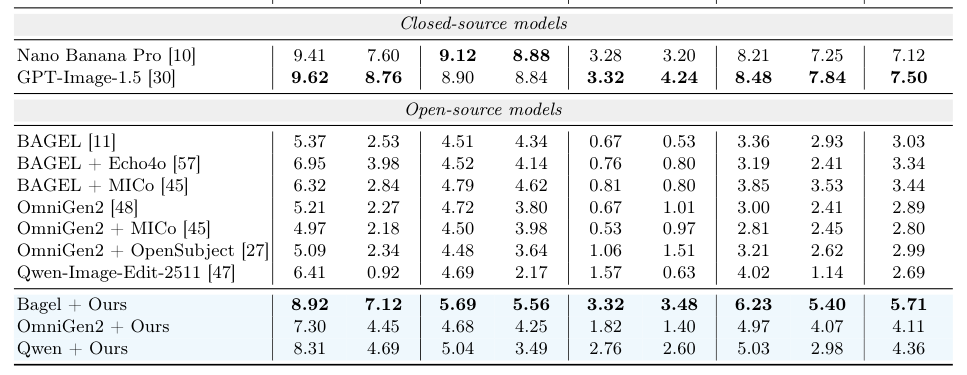
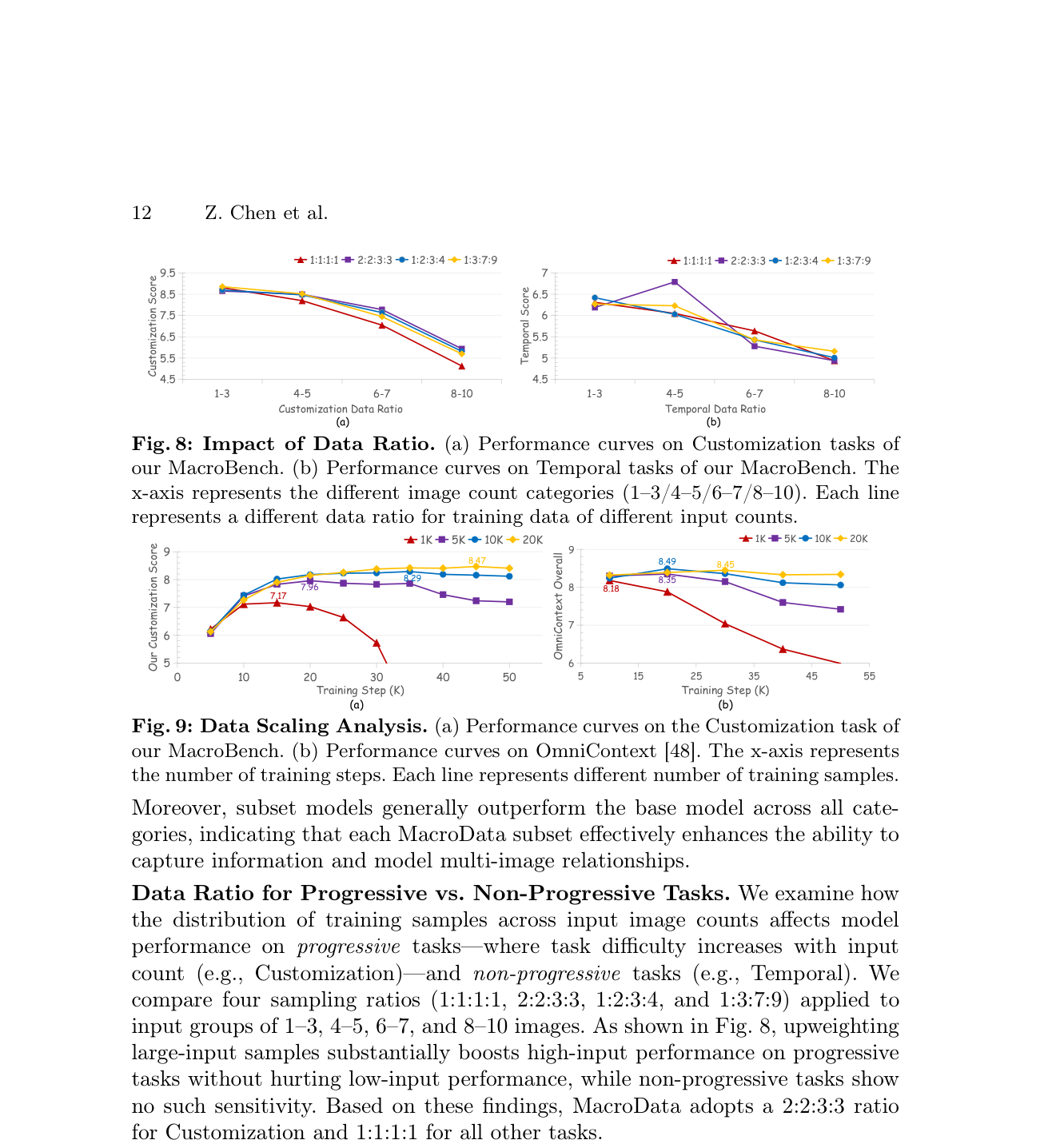
특히, fine-tuning된 Bagel 모델은 MacroBench에서 5.71 의 평균 점수를 달성하여, 기본 Bagel 모델의 3.03 을 크게 상회했다. Customization task에서는 Nano Banana Pro 에 근접했으며, Spatial task에서는 이를 능가하는 성능을 보였다. MacroData 로 훈련된 모델들은 1-5개 에서 6-10개 로 input image 수가 증가할 때 발생하는 성능 저하에 대한 robust함을 입증했다. 예를 들어, Qwen 모델의 Customization 성능 저하 폭은 5.49에서 3.62 로 완화되었다. 또한, cross-task co-training 은 대부분의 task에서 가장 우수한 성능을 보여, multi-task training의 synergistic benefits를 입증했다 [Table 3]. Data scaling analysis 결과, 데이터 볼륨 증가에 따라 성능이 꾸준히 향상되었으며, 10K 샘플 이후에는 포화 상태에 근접하지만 20K 샘플 까지는 training convergence를 안정화하는 효과를 보였다
Text-aligned token selection 전략은 30%의 token retention 으로도 가장 중요한 정보를 효과적으로 보존하여 다른 token selection 방식보다 경쟁력 있는 결과를 달성했다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 long-context multi-reference image generation의 핵심 과제를 해결하기 위해 MacroData 와 MacroBench 를 성공적으로 도입했다. MacroData 는 대규모의 구조화된 데이터셋으로서 기존 데이터 부족 문제를 해결하고, MacroBench 는 이 분야의 표준화된 평가 프레임워크를 제공한다. MacroData 를 활용한 훈련은 모델의 multi-reference generation 성능을 크게 향상시키고, 다양한 input scale에 대한 robust함을 증명했다. 이 연구는 복잡한 multi-reference input을 다루는 in-context generation 분야의 미래 연구를 위한 중요한 기반을 마련한다. 이는 creative domain에 큰 잠재적 이점을 제공할 수 있지만, 동시에 deceptive content 생성이나 unauthorized identity manipulation과 같은 이중 사용(dual-use) 위험을 내포한다. 따라서, 데이터셋 구축 시 표준 라이선스를 준수하고, 향후 모델 배포 시에는 real-time output assessment 및 automated privacy detection mechanisms과 같은 robust한 기술적 보호 조치 통합의 필요성을 강조한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
- 현재글 : [논문리뷰] MACRO: Advancing Multi-Reference Image Generation with Structured Long-Context Data
- 다음글 [논문리뷰] MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
댓글