[논문리뷰] MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
링크: 논문 PDF로 바로 열기
저자: Yu Chen, Runkai Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Memory Sparse Attention (MSA) : 수억 개의 토큰에 이르는 방대한 문맥(lifetime-scale contexts)을 효율적으로 처리하기 위해 제안된 end-to-end trainable하고 확장 가능한 sparse attention 프레임워크입니다.
- Rotary Positional Embedding (RoPE) : Transformer 모델에서 토큰의 상대적 위치 정보를 인코딩하는 방식이며, MSA에서는 document-wise 및 global RoPE 전략을 사용하여 긴 context 길이에 대한 generalization을 강화합니다.
- KV Cache Compression : Key-Value 캐시를 chunk-wise mean pooling을 통해 압축하여 memory footprint와 retrieval latency를 줄이는 기술입니다.
- Memory Interleave : 복잡한 multi-hop reasoning을 가능하게 하는 적응형 메커니즘으로, Generative Retrieval과 Context Expansion을 반복적으로 수행하여 산재된 memory segment 간의 cross-document dependencies를 통합합니다.
- Needle-In-A-Haystack (NIAH) : 긴 context 내에서 특정 "바늘(needle)" 정보를 얼마나 정확하게 찾고 활용하는지를 평가하는 벤치마크 task로, LLM의 long-context fidelity 및 extrapolation 능력을 측정하는 데 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)는 다양한 분야에서 뛰어난 능력을 보였지만, 수백만 토큰 규모의 장기적이고 세밀한 기억(long-term, fine-grained memory retention)을 처리하는 데에는 여전히 큰 어려움에 직면해 있습니다. 현재 LLM의 effective context length는 일반적으로 1M 토큰 이내로 제한되며, 이는 인간의 평생 기억 용량인 200~300M 토큰 과는 현저한 차이를 보입니다. 이러한 한계는 대규모 corpus summarization, Digital Twins with stable personas, long-history agent reasoning과 같은 복잡한 시나리오의 발전을 저해합니다.
기존 연구들은 이러한 context length 한계를 확장하고자 hybrid linear attention, fixed-size memory states (예: RNNs), RAG(Retrieval-Augmented Generation) 또는 agent systems와 같은 외부 저장 방식 등을 시도했습니다. 그러나 이들 접근 방식은 context length가 증가함에 따라 심각한 precision degradation과 latency 증가, memory content의 동적 수정 불가, 또는 end-to-end optimization의 부족과 같은 문제점을 겪었습니다. 특히, 고충실도(high-fidelity) memory의 확장성 제한과 end-to-end trainability 부족은 기존 패러다임이 안고 있는 두 가지 근본적인 제약으로 작용하여, scalable하고 고품질의 lifelong memory를 위한 필수 기준을 충족하지 못했습니다. 본 논문은 이러한 과제를 해결하기 위해 Memory Sparse Attention (MSA)을 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 "retrieve-then-read" 방식의 한계를 넘어, Memory Sparse Retrieval과 answer generation을 단일하고 jointly-optimized된 아키텍처로 통합하는 MSA (Memory Sparse Attention) 를 제안합니다. MSA는 latent state 수준에서 대규모 memory를 효율적으로 처리하기 위해 표준 dense self-attention을 document-based retrieval sparse attention 메커니즘으로 대체합니다. 각 document의 hidden state로부터 Key ( K ), Value ( V ), 그리고 라우팅을 위한 Router Key ( KR )를 생성하며, 이를 chunk-wise mean pooling ( ϕ(⋅) )을 통해 압축하여 KV Cache Compression 을 수행합니다. 추론 시, query의 Router Query ( QR )를 생성하고 이를 압축된 Router Key와 비교하여 Top-k documents를 선택합니다.
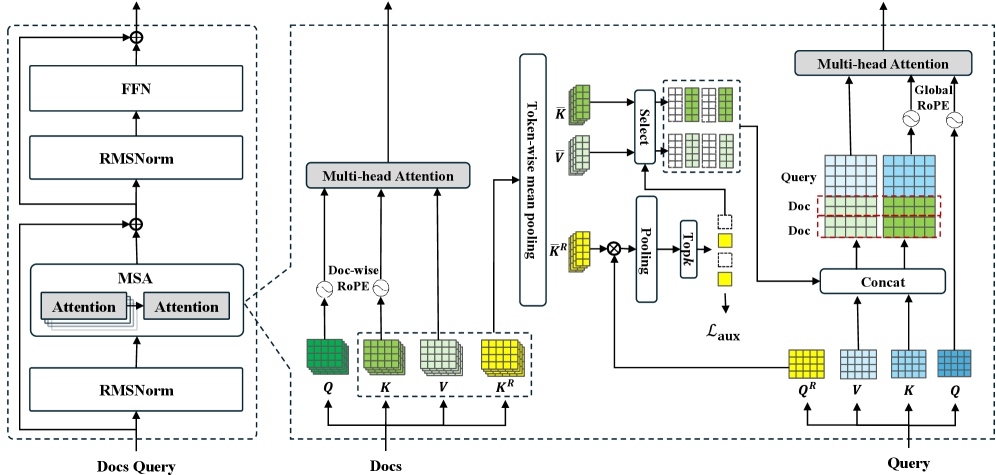
이 선택된 documents의 압축된 Key와 Value만이 query의 local cache와 결합되어 attention 연산에 사용됩니다.
Parallel and Global RoPE 전략을 사용하여 memory 규모 변화에 강건한 generalization을 보장합니다. 각 document에 독립적인 RoPE를 적용하여 training과 inference 간의 context 길이 불일치 문제를 해결하고, active context에는 Global RoPE를 적용하여 인과 관계를 유지합니다.
MSA의 학습은 두 단계로 이루어집니다. 첫째, Continuous Pre-training 단계에서는 158.95 billion 토큰의 corpus를 사용하여 Generative Retrieval 능력을 부여합니다. 이 단계에서는 표준 LLM loss (ℒLLM) 외에 Layer-wise Routing을 감독하는 auxiliary contrastive loss (ℒaux) 를 도입하여 라우터가 관련 document를 정확하게 선택하도록 유도합니다. 둘째, Post-Training 단계에서는 8k 토큰의 QA 데이터셋으로 SFT를 수행한 후, memory context length를 64k 토큰으로 확장하는 curriculum learning을 적용하여 long dependency 적응력과 extrapolation robustness를 향상시킵니다.
추론 과정은 Three-Stage Inference Process 로 구성됩니다
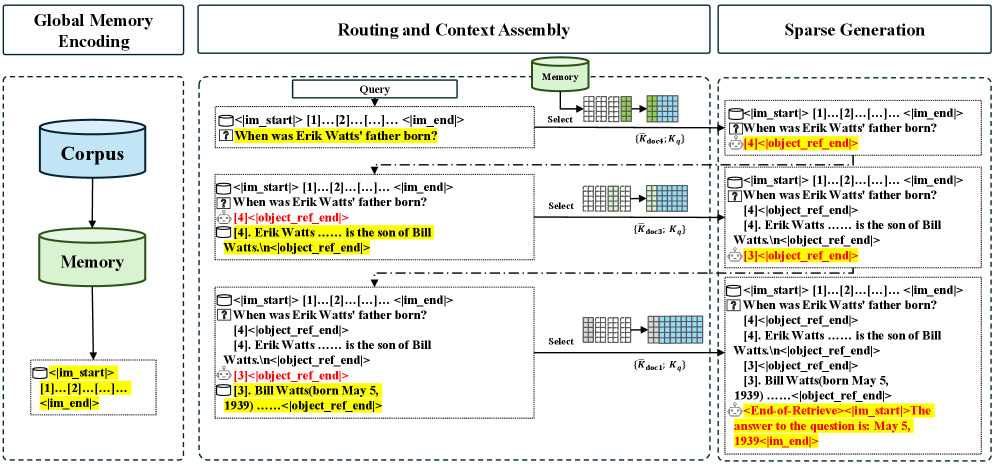
Stage 1 (Global Memory Encoding)에서는 모든 document의 압축된 KV 및 KR을 오프라인으로 캐싱합니다. Stage 2 (Routing and Context Assembly)에서는 query를 바탕으로 Top-k document를 선택하고 해당 KV를 로드하여 sparse context를 구성합니다. Stage 3 (Sparse Generation)에서는 이 sparse context를 사용하여 autoregressive generation을 수행합니다. 또한, Memory Parallel 을 통해 100M 토큰 규모의 추론을 2x A800 GPU와 같은 표준 하드웨어에서 가능하게 합니다. 이는 Tiered Memory Storage Strategy (GPU-Resident Routing Keys, CPU-Offloaded Content KVs)와 Distributed Scoring을 통해 달성됩니다. 복잡한 multi-hop reasoning을 위해 Memory Interleave 메커니즘을 도입하여 Generative Retrieval과 Context Expansion을 반복적으로 수행합니다.
주요 실험 결과는 다음과 같습니다:
- MSA는 training 및 inference에서 linear complexity (𝒪(L)) 를 달성합니다.
- MS MARCO QA 벤치마크에서 16K에서 100M 토큰 으로 context를 확장했을 때 9% 미만의 성능 저하 를 보이며 탁월한 precision stability를 입증했습니다 [Figure 1].
- QA task에서 동일한 Qwen3-4B-Instruct 백본을 사용한 RAG 시스템 대비 평균 16.0% (standard RAG), 11.5% (RAG with reranking), 14.8% (HippoRAG2)의 성능 향상을 보였습니다.
- NIAH (Needle-In-A-Haystack) 벤치마크에서 32k에서 1M 토큰까지 context length를 확장했을 때, 1M 토큰 규모에서 94.84% 의 높은 retrieval accuracy를 유지하며, 32k 토큰 대비 3.93-percentage-point 의 미미한 감소율을 보였습니다
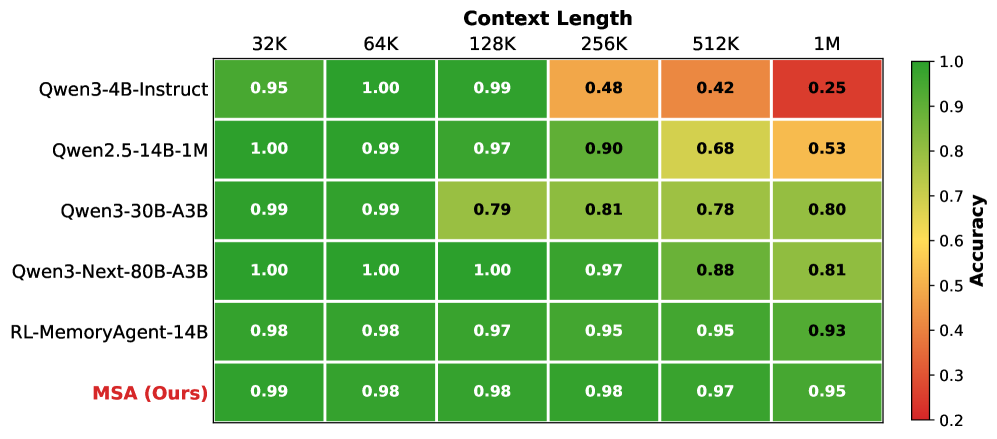
이는 기존 long-context 모델이나 외부 memory 시스템 대비 압도적인 robustness입니다.
- Ablation study 결과, curriculum learning은 평균 7.6% 성능 향상 (MS MARCO에서 29.5% ), Memory Interleave는 multi-hop reasoning (HotpotQA에서 19.2% 성능 저하)에 필수적임이 확인되었습니다. 또한, continuous pre-training 제거 시 평균 31.3% 의 성능 저하, original document text 통합 제외 시 평균 37.1% 의 성능 저하가 발생하여 각 구성 요소의 중요성을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 document-wise RoPE 및 KV-cache compression으로 강화된 확장 가능한 sparse-attention 프레임워크인 MSA를 제안하여, end-to-end 모델링을 lifetime-scale contexts로 확장합니다. MSA는 Memory Parallel을 통해 100M 토큰 규모의 고속 처리를 가능하게 하며, Memory Interleave 메커니즘을 통해 분산된 memory segment 간의 robust한 multi-hop reasoning을 지원합니다.
Long-context QA 및 Needle-in-a-Haystack 벤치마크에서 MSA는 기존 SOTA LLM 및 RAG 시스템을 능가하며 retrieval fidelity와 reasoning depth를 유지했습니다. 특히, extreme context length에서도 성능 저하가 최소화되어, effective context가 100M 토큰까지 확장될 때도 높은 정확도를 유지하는 것이 확인되었습니다. 이러한 결과는 MSA가 memory capacity를 reasoning capability로부터 효과적으로 분리함으로써, 일반 목적 모델에 내재적이고 평생 규모의 memory를 부여할 수 있는 새로운 foundational component가 될 수 있음을 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
- [논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] MACRO: Advancing Multi-Reference Image Generation with Structured Long-Context Data
- 현재글 : [논문리뷰] MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
- 다음글 [논문리뷰] MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution
댓글