[논문리뷰] TEMPO: Scaling Test-time Training for Large Reasoning Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Qingyang Zhang, Xinke Kong, Haitao Wu, Qinghua Hu, Minghao Wu, Baosong Yang, Yu Cheng, Yun Luo, Ganqu Cui, Changqing Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- TEMPO (Test-time Expectation-Maximization Policy Optimization): LRM의 테스트 시점 성능 향상을 위해 Critic recalibration과 Policy refinement를 반복하는 EM 알고리즘 기반의 프레임워크입니다.
- RLVR (Reinforcement Learning from Verifiable Rewards): 라벨링된 데이터를 기반으로 모델의 추론 능력을 강화하는 학습 기법으로, TEMPO의 초기화 단계에서 사용됩니다.
- ELBO (Evidence Lower Bound): 관찰되지 않는 정답 여부를 잠재 변수로 설정하고, 이를 최적화하기 위해 도입된 변분 하한선입니다.
- Diversity Collapse: 모델이 특정 추론 경로에만 과도하게 최적화되어 출력의 다양성이 저하되고, 결과적으로 성능 정체(plateau)가 발생하는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Large Reasoning Models (LRMs)의 테스트 시점 학습(Test-time Training, TTT)이 겪는 성능 정체 및 다양성 붕괴 문제를 해결하고자 합니다. 기존 TTT 기법들은 외부 라벨 없이 모델 스스로 보상 신호를 생성하는 과정에서 휴리스틱에 의존하며, 모델이 업데이트됨에 따라 보상 신호가 드리프트되는 근본적인 한계를 가지고 있습니다. 이러한 구조적 결함은 모델이 좁은 추론 패턴에 과적합되게 만들며, 추가적인 컴퓨팅 자원을 투입해도 더 이상의 성능 향상을 이끌어내지 못하는 문제를 야기합니다 [Figure 1].
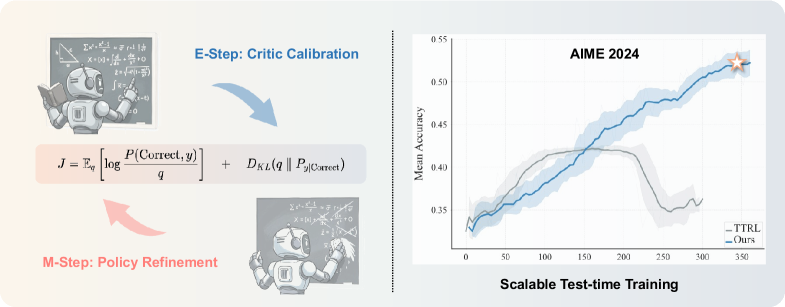
Figure 1 — TEMPO의 확장성 및 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 TTT 과정을 EM 알고리즘으로 형식화하여, 기존 기법들이 E-step(보상 재보정)을 생략하고 M-step(정책 최적화)만 수행하는 불완전한 방식임을 밝혀냅니다. 이를 극복하기 위해 TEMPO는 라벨링된 데이터로 Critic을 주기적으로 재보정하는 E-step과, 비라벨링 테스트 질문에 대해 Critic 기반 보상으로 정책을 개선하는 M-step을 교차 수행합니다 [Figure 2]. OLMO3-7B 모델의 경우, AIME 2024 벤치마크에서 기존 33.0%의 정확도를 51.1%까지 향상시켰으며, Qwen3-14B는 42.3%에서 65.8%로 개선되어 23.5%p의 압도적인 정량적 성과를 보였습니다 [Table 1]. 또한, 기존 기법들이 Pass@K 지표에서 급격한 다양성 붕괴를 겪는 것과 달리, TEMPO는 높은 다양성을 유지하며 지속적인 성능 향상을 달성했습니다 [Figure 3].
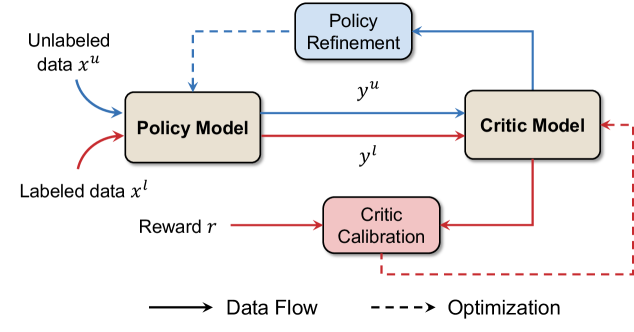
Figure 2 — TEMPO의 교차 최적화 구조
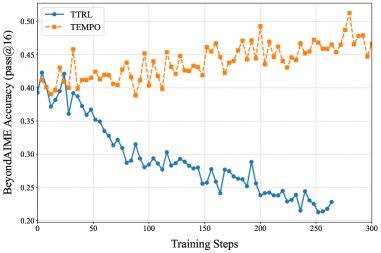
Figure 3 — 모델 다양성 유지 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 테스트 시점에서의 Critic 재보정이 지속적인 모델 성능 향상을 위한 필수 조건임을 이론적으로 정립하고, 이를 TEMPO라는 실용적인 프레임워크로 구현했습니다. 이 연구는 기존의 단순한 Self-rewarding 기법들이 가진 한계를 극복하고, 모델이 테스트 시간에 실질적인 지능적 확장을 할 수 있는 방법을 제시합니다. 학계와 산업계 모두에서 LRM의 사후 학습 효율성을 극대화하고, 다양한 추론 과제에 유연하게 적용할 수 있는 강력한 방법론으로서 큰 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
- [논문리뷰] ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
- [논문리뷰] Does Your Reasoning Model Implicitly Know When to Stop Thinking?
- [논문리뷰] FLAC: Maximum Entropy RL via Kinetic Energy Regularized Bridge Matching
- [논문리뷰] THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Review 의 다른글
- 이전글 [논문리뷰] Speculative Decoding for Autoregressive Video Generation
- 현재글 : [논문리뷰] TEMPO: Scaling Test-time Training for Large Reasoning Models
- 다음글 [논문리뷰] Target-Oriented Pretraining Data Selection via Neuron-Activated Graph
댓글