[논문리뷰] Target-Oriented Pretraining Data Selection via Neuron-Activated Graph
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zijun Wang, Haoqin Tu, Weidong Zhou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- NAG (Neuron-Activated Graph): 특정 입력을 처리할 때 모델 내에서 강한 영향을 미치는 뉴런들의 레이어별 분포를 구조화하여 표현한 모델의 '기능적 중추(functional backbone)'입니다.
- Neuron Impact: 특정 입력 $h_{in}$이 주어졌을 때, 해당 레이어의 뉴런 $N_k$를 비활성화(deactivation)함으로써 발생하는 모델 출력값의 변화량을 측정하여 뉴런의 중요도를 수치화한 지표입니다.
- NAG-based Ranking: 모델의 black-box 표현 방식을 사용하는 대신, NAG의 유사성을 기반으로 타겟 도메인/태스크에 적합한 데이터를 선별하는 학습이 불필요한(training-free) 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM pretraining 과정에서 타겟 도메인 및 태스크의 특성을 효율적으로 학습하기 위한 정교한 데이터 선별 기법의 부재 문제를 해결합니다. 기존의 데이터 선별 방식은 주로 일반적인 데이터 품질 휴리스틱에 의존하거나 black-box 임베딩 유사성을 활용하는데, 이는 모델이 타겟 능력을 획득하는 데 필요한 기능적 정렬(alignment)을 보장하지 못한다는 한계가 있습니다 [Figure 1]. 이러한 불투명한 distillation 과정은 데이터 선별 기준과 모델의 실제 기능 습득 사이의 간극을 초래하므로, 모델 내부의 기능적 뉴런 수준에서 해석 가능하고 직접적으로 타겟 능력을 포착할 수 있는 새로운 접근 방식이 필요합니다.
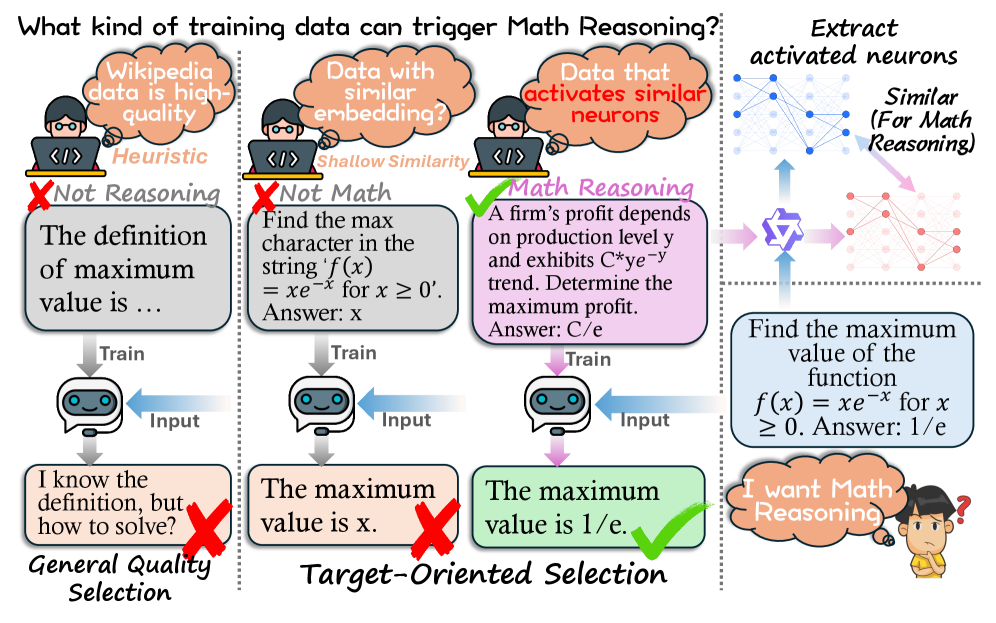
Figure 1 — 기존 방식 대비 NAG의 개념 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 각 입력 데이터를 모델 내부의 핵심 뉴런 활성화 패턴으로 특성화하여 이를 NAG로 구성하고, 타겟 예제와의 NAG 유사도를 통해 데이터를 랭킹하는 NAG-based Ranking을 제안합니다 [Figure 2]. 구체적으로, 각 레이어에서 높은 영향력을 가진 상위 K개의 뉴런을 선정하여 NAG를 구성하고, 이를 타겟 예제들로부터 집계된 프로파일과 비교하여 선별합니다. 정량적 실험 결과, NAG-based Ranking은 Random Sampling 대비 타겟 태스크 성능을 평균 4.9% 향상시켰으며, 특히 HellaSwag 등에서 기존 SOTA 베이스라인 대비 5.3% 높은 정확도를 기록했습니다 [Table 1]. 또한, NAG를 기존의 FineWeb-Edu 품질 신호와 결합했을 때 평균 1.8%의 추가 성능 향상을 보여, 이 기법이 기존 데이터 파이프라인과 상호보완적으로 작동함을 입증했습니다 [Table 2].
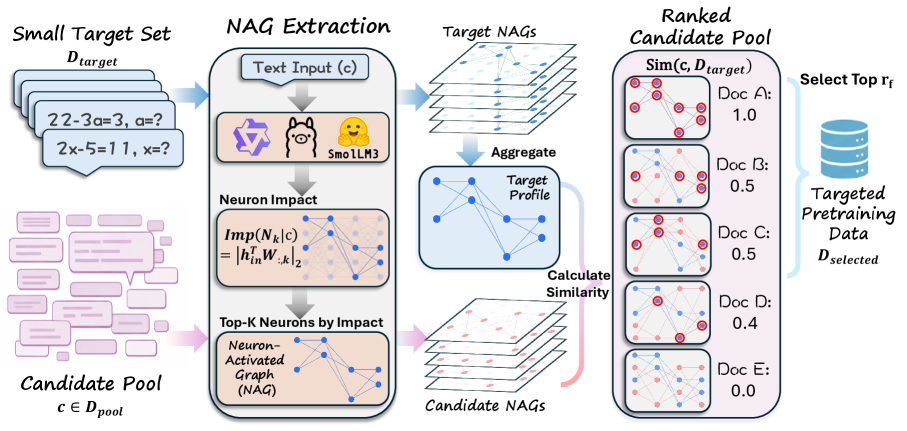
Figure 2 — NAG 기반 데이터 선별 프레임워크
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델 내부의 뉴런 활성화 패턴을 직접 활용하여 타겟 데이터를 효율적으로 선별하는 NAG-based Ranking을 성공적으로 제시했습니다. 이 접근 방식은 추가적인 학습 없이도 강력한 타겟 성능 향상을 이끌어내며, 특히 매우 적은 비율(0.12%)의 뉴런만 비활성화해도 성능이 23.5% 급감하는 결과를 통해 NAG가 모델의 핵심 기능적 backbone을 성공적으로 포착함을 증명했습니다 [Table 3]. 이 연구는 데이터 선별 과정의 투명성을 높이고, 특정 도메인에 최적화된 LLM을 구축하기 위한 데이터 전략에 중요한 해석학적 근거를 제공합니다.

Figure 3 — NAG 표현의 태스크별 클러스터링 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Review 의 다른글
- 이전글 [논문리뷰] TEMPO: Scaling Test-time Training for Large Reasoning Models
- 현재글 : [논문리뷰] Target-Oriented Pretraining Data Selection via Neuron-Activated Graph
- 다음글 [논문리뷰] The Cognitive Penalty: Ablating System 1 and System 2 Reasoning in Edge-Native SLMs for Decentralized Consensus
댓글