[논문리뷰] Efficient Image Synthesis with Sphere Latent Encoder
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tung Do, Thuan Hoang Nguyen, Hao Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sphere Latent Encoder: 본 논문에서 제안하는 생성 프레임워크로, 픽셀-잠재 공간 간의 반복적 전환 없이 잠재 공간 내에서 직접 denoising 과정을 수행하여 효율성을 극대화한 모델입니다.
- Representation Autoencoder (RAE): 본 연구에서 고정된 이미지 토크나이저로 활용하는 모델로, semantically rich한 잠재 표현을 제공하여 생성 품질을 높이는 역할을 합니다.
- Spherification Function ($\mathcal{F}$): 잠재 표현을 RMSNorm을 통해 hypersphere로 투영하여 잠재 구조를 균일하게 유도하는 함수입니다.
- NFE (Number of Function Evaluations): 이미지 생성 과정에서 모델이 호출되는 횟수를 의미하며, 본 논문에서는 낮은 NFE를 통해 효율적인 few-step 생성을 달성합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 few-step 생성 모델들이 겪는 비효율성과 훈련 불안정성 문제를 해결하고자 합니다. 기존 Sphere Encoder는 생성 과정에서 픽셀 공간과 잠재 공간 사이를 반복적으로 오가는 불필요한 연산을 수행하여 계산 비용이 높고, reconstruction과 generation 목적 함수가 단일 아키텍처 내에서 충돌하는 최적화 딜레마를 가집니다 [Figure 2]. 이러한 설계는 고해상도 이미지 합성이나 대규모 데이터셋에서의 scalability를 제한하며, 샘플 품질과 추론 속도 사이의 trade-off를 유발합니다. 따라서 본 논문은 reconstruction과 generation 역할을 독립적으로 분리하고, 모든 denoising 과정을 잠재 공간에서 수행하는 새로운 프레임워크가 필요하다고 주장합니다.

Figure 2 — 기존 방식과 제안 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 pretrained RAE를 고정된 이미지 토크나이저로 사용하고, 잠재 공간에서 작동하는 별도의 Transformer-based denoising network를 학습시키는 decoupled 설계를 제안합니다 [Figure 3]. 훈련 과정에서는 latent space 내에서 수행되는 reconstruction loss와 consistency loss를 결합하여 모델의 안정적인 학습을 도모하며, 특히 hyperspherical manifold를 활용한 denoising 프로세스를 통해 효율적인 샘플링을 구현합니다 [Figure 3]. 실험 결과, 본 모델은 ImageNet-1K 데이터셋에서 4-NFE 기준 FID 2.25를 달성하여 기존 Sphere Encoder(FID 4.02) 대비 월등한 생성 품질을 기록하였습니다 [Table 2]. 또한, 추론 과정에서 반복적인 픽셀-잠재 공간 전환을 제거함으로써, 동일한 샘플링 단계에서 Sphere Encoder 대비 약 85% 적은 FLOPs를 사용하여 inference 속도를 비약적으로 개선했습니다 [Table 1]. 이러한 결과는 본 모델이 low-NFE regime에서 높은 효율성과 우수한 품질을 동시에 확보했음을 시사합니다 [Figure 4].
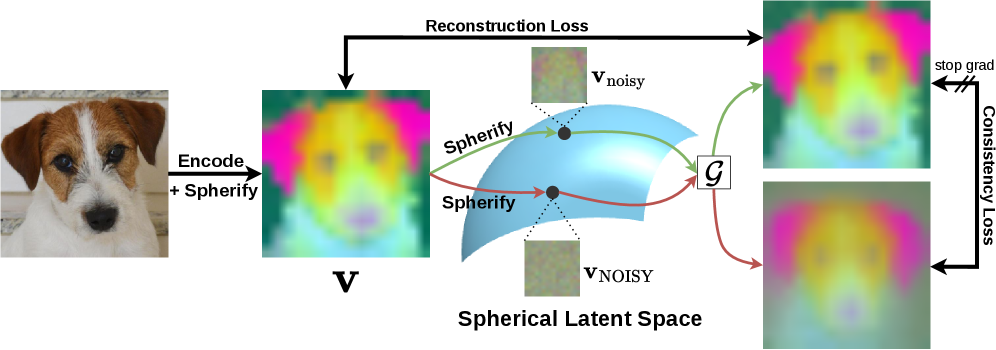
Figure 3 — 제안 모델 전체 구조 및 손실 함수

Figure 4 — 4단계 생성 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 spherical latent space에서의 denoising 기반 생성 프레임워크를 통해 few-step 이미지 생성의 새로운 효율성을 정의하였습니다. reconstruction과 generation을 명확히 분리함으로써 각 구성 요소가 자신의 역할에 전문화될 수 있게 했으며, 이는 기존 모델들의 고질적인 최적화 갈등을 성공적으로 해결했습니다. 이 연구는 고성능 이미지 합성 모델의 실용적인 적용 가능성을 크게 높였으며, 향후 다양한 조건부 생성 과제나 더 확장된 생성 프레임워크 연구를 위한 기반이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Multiplayer Interactive World Models with Representation Autoencoders
- [논문리뷰] IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
- [논문리뷰] Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
Review 의 다른글
- 이전글 [논문리뷰] Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
- 현재글 : [논문리뷰] Efficient Image Synthesis with Sphere Latent Encoder
- 다음글 [논문리뷰] FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
댓글