[논문리뷰] Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Taewon Yun, Jisu Shin, Jeonghwan Choi, Seunghwan Bang, Hwanjun Song
1. Key Terms & Definitions (핵심 용어 및 정의)
- CoRD (Collaborative Reasoning Decoding): 여러 teacher LRM이 공동으로 reasoning 단계를 생성하고 통합하는 step-wise decoding 프레임워크입니다.
- Long-CoT (Long Chain-of-Thought): 모델이 복잡한 문제를 해결하기 위해 deliberative한 사고 과정을 거치며 생성하는 긴 형태의 추론 경로를 의미합니다.
- Predictive Perplexity: 특정 reasoning prefix가 주어졌을 때 ground-truth answer를 얼마나 잘 예측하는지 평가하는 지표로, candidate reasoning step의 품질을 측정하는 데 사용됩니다.
- Prompt-guided Step Segmentation: reasoning 과정을 의미론적으로 일관된 단위로 분할하기 위해 prompt를 사용하여 명시적인 boundary를 생성하는 기법입니다.
- Meta-prover (MP): predictive perplexity를 계산하기 위해 사용되는 LRM으로, teacher 모델 중 성능이 가장 우수한 모델을 채택하여 reasoning step의 품질을 평가합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 Long-CoT 모델의 높은 추론 비용을 해결하기 위한 효율적인 reasoning distillation 프레임워크를 제안합니다. 기존의 Curation 기반 방식은 완성된 reasoning 경로를 사후에 선택하는 방식을 취하여 teacher 모델 간의 협업 잠재력을 활용하지 못하고, 불필요한 계산 낭비를 초래한다는 한계가 있습니다. 또한, 기존 연구들은 Long-CoT 내에서 발생하는 동적인 사고의 진화 과정을 포착하지 못하고 사후적인 필터링에 의존하므로 최적의 데이터를 확보하기 어렵습니다. 이러한 문제를 해결하기 위해 본 연구는 사후 선택 방식에서 탈피하여 추론 과정 중에 teacher 모델들이 실시간으로 협업하는 새로운 step-wise decoding 접근 방식을 정의합니다 [Figure 1].
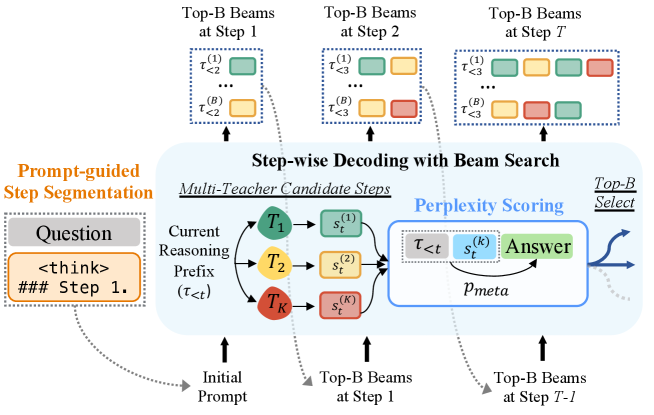
Figure 1 — CoRD 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 CoRD를 통해 reasoning distillation을 step-wise auto-regressive decoding 과정으로 재정의합니다. Prompt-guided Step Segmentation을 통해 서로 다른 모델이 생성한 추론을 정렬하고, 각 단계에서 teacher 모델들이 생성한 후보를 Predictive Perplexity를 기준으로 평가하여 최적의 단계를 선택합니다 [Table 1]. 또한, greedy decoding의 한계를 극복하기 위해 Beam Search를 도입하여 로컬 최적해에 빠지지 않고 다양한 추론 경로를 탐색합니다. 실험 결과, CoRD는 기존 baseline인 Curation 및 Integration 방식 대비 AIME24와 AIME25 벤치마크에서 일관되게 높은 Pass@1 성능을 기록했습니다 [Table 3]. 특히, heterogeneous teacher 구성에서 상호보완적인 추론 스타일이 결합되어 더 높은 Predictive Perplexity와 정확도를 달성했으며, distilled student 모델은 32B 크기에서 teacher 모델의 성능을 상회하는 결과를 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 CoRD를 통해 reasoning distillation의 패러다임을 사후 curation에서 동적 협업 디코딩으로 전환하였습니다. 이 프레임워크는 개별 teacher 모델의 역량을 넘어선 고품질의 학습 데이터를 생성하며, 적은 컴퓨팅 자원으로도 효율적으로 student 모델의 추론 능력을 극대화할 수 있음을 입증했습니다. 해당 기술은 복잡한 reasoning이 요구되는 다양한 도메인으로의 확장 가능성을 보여주었으며, 향후 LLM의 test-time scaling 및 지식 증류 분야 연구에 중요한 방법론적 토대를 제공합니다.
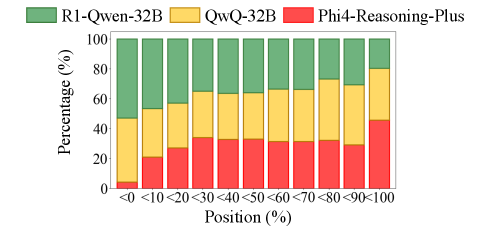
Figure 2 — 단계별 teacher 선택 히트율
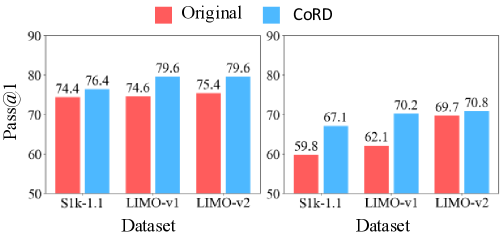
Figure 3 — 모델 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Diagnosing Harmful Continuation in Answer-Correct Long-CoT Training Traces
- [논문리뷰] Context Training with Active Information Seeking
- [논문리뷰] AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization
- [논문리뷰] RelayLLM: Efficient Reasoning via Collaborative Decoding
- [논문리뷰] Visual Autoregressive Models Beat Diffusion Models on Inference Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] DiagnosticIQ: A Benchmark for LLM-Based Industrial Maintenance Action Recommendation from Symbolic Rules
- 현재글 : [논문리뷰] Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
- 다음글 [논문리뷰] Efficient Image Synthesis with Sphere Latent Encoder
댓글