[논문리뷰] DiagnosticIQ: A Benchmark for LLM-Based Industrial Maintenance Action Recommendation from Symbolic Rules
링크: 논문 PDF로 바로 열기
저자: Devin Yasith De Silva, Dhaval Patel, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- DiagnosticIQ: 산업 설비 유지보수 단계에서 LLM의 의사결정 지원 능력을 평가하기 위해 구축된 6,690개의 전문가 검증 MCQA 벤치마크.
- Symbolic Rules: 센서 데이터의 상태를 기반으로 엔지니어가 작성한 논리 규칙으로, 설비 결함 탐지 및 조치 단계를 규정.
- DNF (Disjunctive Normal Form): 정형화된 Symbolic Rules을 LLM이 처리하기 용이하도록 표준화된 논리 연산 형태(논리합의 논리곱).
- DiagnosticIQ Pro: 10개의 선택지(option)를 사용하여 다수의 유사한 실패 사례 간 변별력을 측정하는 고난도 벤치마크 버전.
- RRSim (Rule-to-Rule Similarity): 임베딩 기반의 유사도 측정 기법으로, Selection 및 Elimination 문제를 구성하기 위한 distractor 샘플링의 핵심 도구.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 산업 설비의 고장 감지 이후, 엔지니어가 수행해야 할 구체적인 정비 단계(maintenance steps)를 추천하는 데 있어 LLM의 역량을 체계적으로 진단하고자 한다. 기존의 설비 모니터링 시스템은 고장 감지(detection)에는 능숙하지만, 복잡한 설비별 고장 모드에 대한 전문 지식을 바탕으로 최적의 조치(action)를 추천하는 데는 한계가 있다. 저자들은 실제 산업 현장의 expert-authored symbolic rules이 존재함에도 불구하고, 이를 LLM이 어떻게 해석하고 활용하는지에 대한 표준화된 벤치마크가 부재하다는 점을 지적한다. [Figure 2]의 워크플로우를 통해 보여지듯, 본 연구는 symbolic rule-to-action 단계를 LLM이 얼마나 효과적으로 수행하는지 정량적으로 평가하는 것을 목표로 한다.
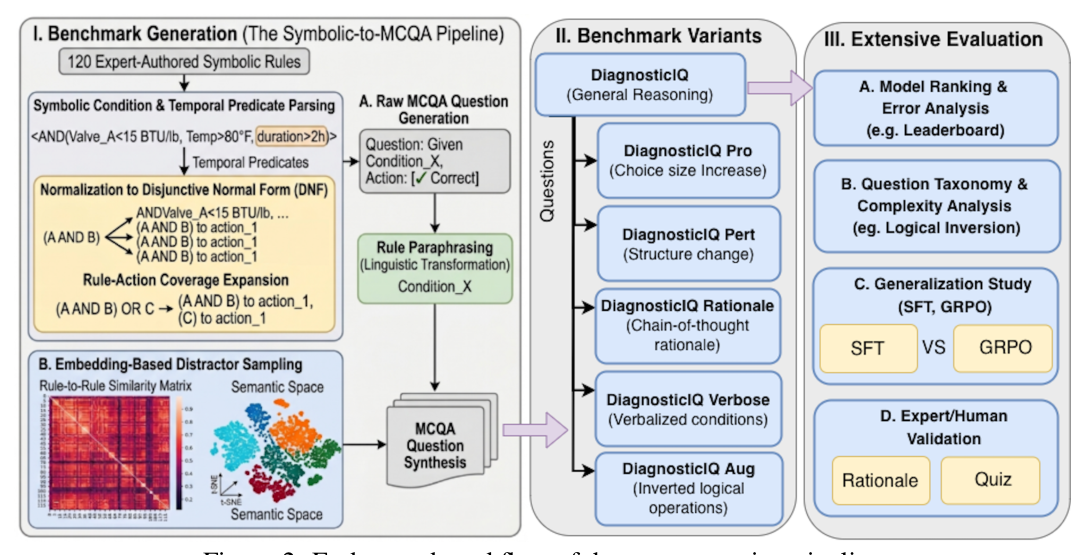
Figure 2 — 벤치마크 생성 파이프라인의 전체적인 구조를 설명하는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 expert-authored rules을 DNF 형태로 정규화하고, RRSim을 통해 의미적으로 유사하거나 차이가 있는 선택지를 생성하여 MCQA 데이터셋을 구축하는 결정론적 파이프라인을 제안한다. 주요 실험 결과로, 최신 Frontier LLM인 claude-opus-4-6, gpt-5.4, gemini-3.1-pro-preview가 DiagnosticIQ에서 Macro accuracy 7273% 수준으로 클러스터링됨을 확인하였다. 그러나 고난도 variant인 DiagnosticIQ Pro에서는 모든 모델의 relative accuracy가 1360% 하락하며, 특히 설비 간의 연관성이 복잡한 경우 성능 저하가 두드러졌다. 또한, DiagnosticIQ Aug를 활용한 실험에서 많은 모델이 논리 연산자가 반전되어도 원래의 답변을 선택하는 경향(49~63%)을 보여, 모델이 조건을 평가하기보다 템플릿 기반의 패턴 매칭에 의존하고 있음을 [Table 2]를 통해 입증하였다.
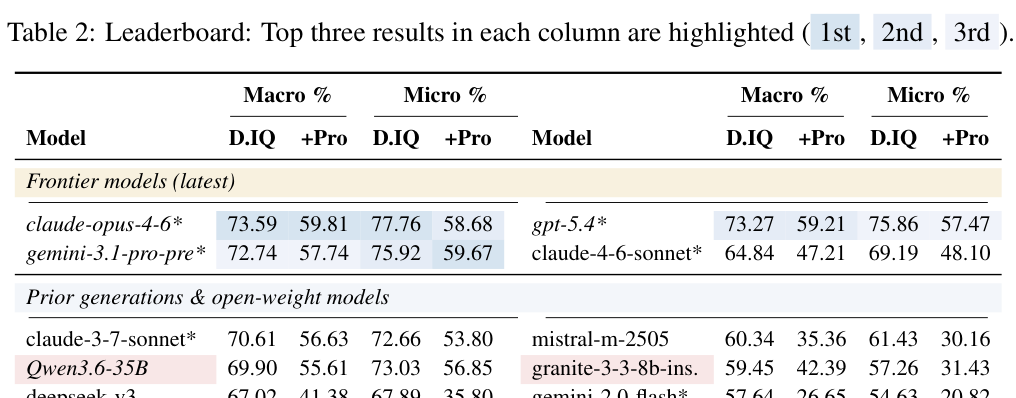
Table 2 — 다양한 LLM 모델들의 DiagnosticIQ 및 DiagnosticIQ Pro 성능을 비교한 핵심 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 산업계의 고도로 구조화된 전문 지식에 대해 현재의 Frontier LLM들이 템플릿 인식 수준의 제약에서 벗어나지 못하고 있음을 확인하였다. 연구 결과는 LLM이 단순한 추론을 넘어 복잡한 물리적 환경의 유지보수를 지원하기 위해서는 symbolic structure에 대한 깊은 이해와 논리적 견고성이 필수적임을 시사한다. DiagnosticIQ 벤치마크는 향후 산업 현장에 LLM을 배치하려는 기업들에게 모델의 신뢰성과 안전성을 평가하는 중요한 이정표가 될 것이다. 또한, 본 연구가 제시한 impact-weighted accuracy는 실제 운영상 경제적 효율성을 고려한 모델 선택 기준으로서 큰 가치를 지닌다.
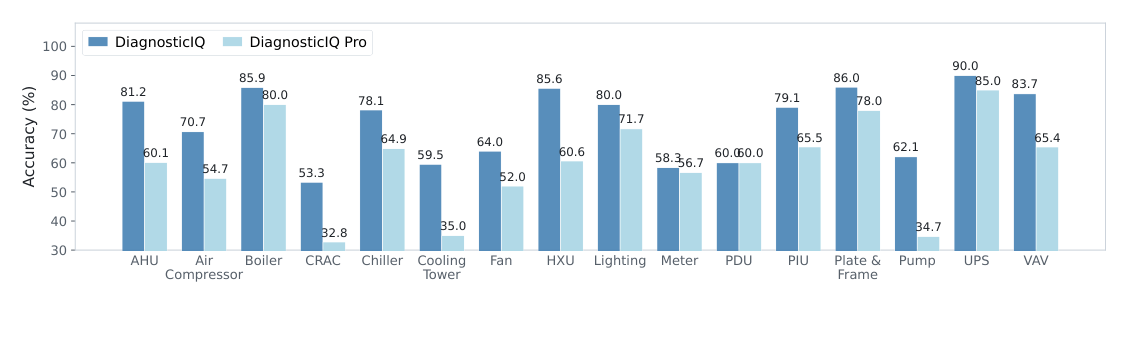
Figure 14 — 설비 타입별 성능 차이를 통해 모델의 brittleness를 시각화한 그래프
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Code-Guided Reasoning for Small Language Models: Evaluating Executable MCQA Scaffolds
- [논문리뷰] StatEval: A Comprehensive Benchmark for Large Language Models in Statistics
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
Review 의 다른글
- 이전글 [논문리뷰] DexJoCo: A Benchmark and Toolkit for Task-Oriented Dexterous Manipulation on MuJoCo
- 현재글 : [논문리뷰] DiagnosticIQ: A Benchmark for LLM-Based Industrial Maintenance Action Recommendation from Symbolic Rules
- 다음글 [논문리뷰] Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
댓글