[논문리뷰] T^2PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shuowei Jin, Xin Liu, Chenwei Zhang, Hejie Cui, Haixin Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic RL: 에이전트가 외부 환경과 다회차(multi-turn) 상호작용을 통해 추론하고 행동하며 학습하는 강화학습 패러다임입니다.
- TTI (Token-Level Thinking Intervention): 토큰 생성 과정에서 모델의 예측 분포가 수렴(convergence)할 때, 추가적인 연산 없이 생각 단계를 강제로 종료하여 효율성을 높이는 방법론입니다.
- TDS (Turn-Level Dynamical Sampling): 다회차 상호작용 중 의미 없는 반복적 행동(hesitation)을 감지하고, 해당 턴을 재샘플링하여 탐색 효율을 최적화하는 기법입니다.
- Self-calibrated Uncertainty Signal ($M_t$): Shannon entropy와 모델의 confidence를 융합하여, 토큰 생성의 불확실성을 더욱 정밀하게 측정하도록 설계된 스칼라 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다회차 Agentic RL 환경에서 빈번하게 발생하는 Training Collapse 현상을 해결하고자 합니다. 기존 연구들은 Fine-grained credit assignment나 Trajectory-level filtering을 도입하여 안정화를 시도했으나, 이러한 방법론들은 종종 coarse한 수준에 머물러 있어 훈련 동역학이 하이퍼파라미터에 지나치게 민감합니다. 저자들은 이 현상의 근본 원인이 'Hesitation'이라 불리는 비효율적인 탐색(inefficient exploration)에 있다고 분석합니다. 이는 에이전트가 정보 획득에 기여하지 못하는 반복적인 생각을 토큰 단위에서 계속하거나, 성공 가능성이 낮은 행동을 턴 단위에서 지속함으로써 발생하는 문제입니다 [Figure 1].

Figure 1 — SOTA 모델의 훈련 불안정성 현상
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 탐색을 명시적으로 제어하기 위해 T^2^PO 프레임워크를 제안합니다. 먼저, Shannon entropy와 token confidence를 결합한 Self-calibrated Uncertainty Signal ($M_t$)을 정의하여 모델의 예측 안정성을 정밀하게 모니터링합니다 [Figure 3]. TTI는 $M_t$의 변동치가 임계치($\epsilon$) 이하로 떨어질 경우 reasoning 단계의 종료를 강제하고, TDS는 턴 간의 안정성 지표($\Gamma^k$)가 낮을 경우 해당 턴을 재샘플링하여 불필요한 rollouts를 방지합니다 [Figure 2].
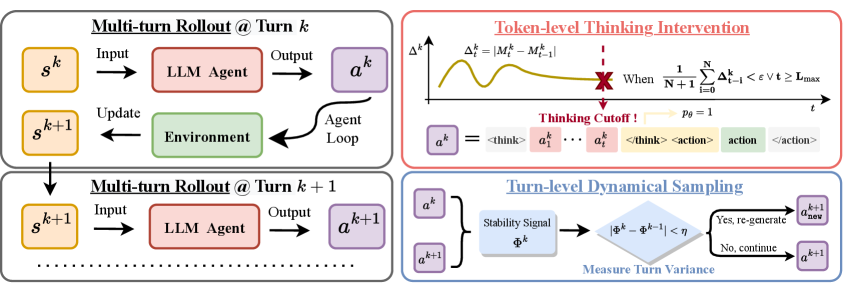
Figure 2 — T^2^PO 프레임워크 전체 아키텍처
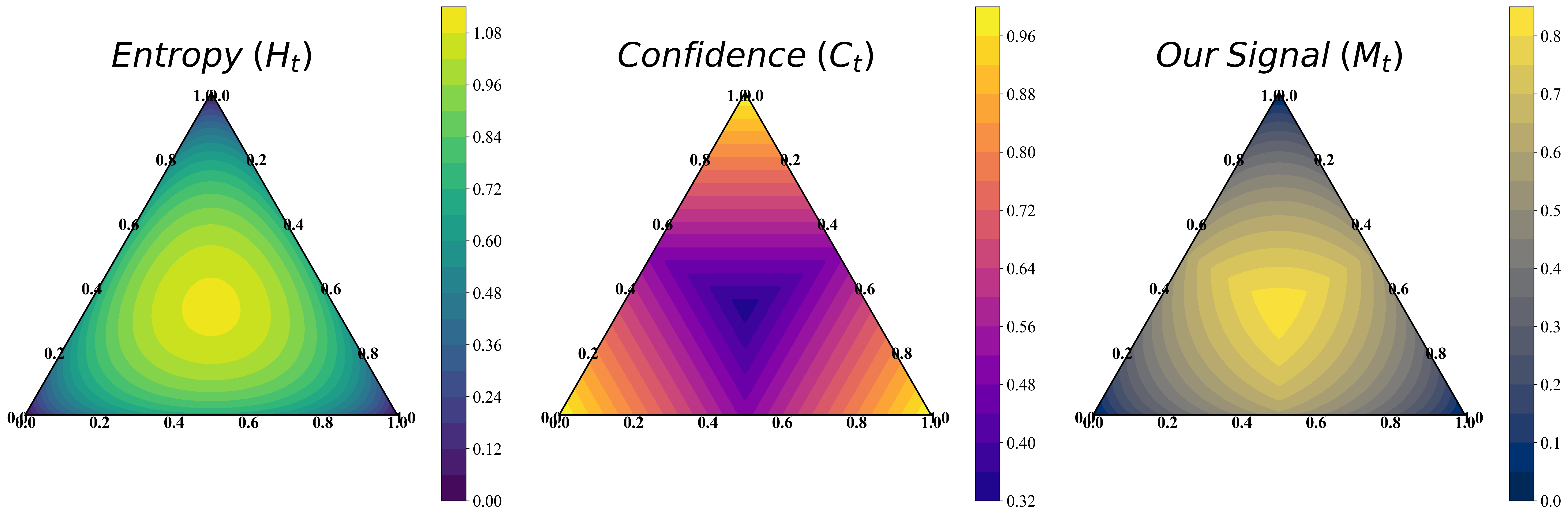
Figure 3 — 불확실성 지표 Mt의 정밀도 비교
실험 결과, T^2^PO는 WebShop 및 ALFWorld와 같은 도전적인 벤치마크에서 기존 SOTA 방식인 GiGPO 대비 유의미한 성능 향상을 보였습니다. 특히 WebShop에서 Qwen3-4B-RFT 기반으로 81.64%의 Success Rate를 달성하여 기존 방법론보다 우수한 수치를 기록하였습니다 [Table 1]. 또한, T^2^PO는 평균 약 25%의 불필요한 interaction turns를 줄이면서도 훈련 분산(variance)을 현저히 낮추어 강력한 Training Stability를 입증하였습니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 탐색의 효율성을 토큰 및 턴 수준에서 정밀하게 제어하는 T^2^PO 프레임워크를 통해 Agentic RL의 고질적인 불안정성을 성공적으로 완화하였습니다. 별도의 복잡한 보상 설계(reward shaping) 없이 모델의 내재적 불확실성 신호만을 활용하여 성능과 효율을 동시에 최적화했다는 점이 핵심적인 기여입니다. 본 연구는 대규모 상호작용 기반 모델의 훈련 과정을 체계적으로 안정화함으로써, 복잡한 실세계 의사결정 문제에 더 넓게 적용될 수 있는 확장 가능한 Agentic AI 학습 표준을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
- [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- [논문리뷰] A Gradient Perspective on RLVR Stability and Winner Advantage Policy Optimization
- [논문리뷰] APPO: Agentic Procedural Policy Optimization
- [논문리뷰] EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
Review 의 다른글
- 이전글 [논문리뷰] Repetition over Diversity: High-Signal Data Filtering for Sample-Efficient German Language Modeling
- 현재글 : [논문리뷰] T^2PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
- 다음글 [논문리뷰] A Benchmark for Interactive World Models with a Unified Action Generation Framework
댓글