[논문리뷰] UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yiqiao Jin, Yiyang Wang, Lucheng Fu, Yijia Xiao, Yinyi Luo, Haoxin Liu, B. Aditya Prakash, Josiah Hester, Jindong Wang, Srijan Kumar
1. Key Terms & Definitions (핵심 용어 및 정의)
- Self-Distillation (SD): 외부의 더 강한 Teacher 모델에 의존하지 않고, LLM이 자신의 생성 결과나 하위 모델로부터 스스로 Supervision 신호를 생성하여 모델을 개선하는 학습 방식입니다.
- Multi-Teacher Agreement: 동일한 학생의 생성 궤적(trajectory)을 여러 개의 보조 Teacher가 서로 다른 관점에서 평가하여, 일관성 있는(신뢰할 수 있는) 신호만을 학습에 사용하는 기법입니다.
- EMA Teacher (Exponential Moving Average): 학습 과정에서 모델 파라미터의 지수 이동 평균을 업데이트하여 생성되는 Teacher Target을 안정화하고, 일시적인 에러 전파를 방지하는 안정화 기법입니다.
- Token-Level Contrastive Learning: 올바른 Supervision과 그럴듯하지만 잘못된 대안(incorrect alternatives) 사이의 거리를 학습시켜, 더 견고하고 분별력 있는 모델 업데이트를 유도하는 방법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 LLM의 post-training 과정이 외부 모델에 지나치게 의존함으로써 발생하는 비용 문제와 보안 위험을 해결하기 위해 UniSD라는 통일된 Self-Distillation 프레임워크를 제안합니다. 기존의 Self-Distillation 연구들은 주로 개별 기법들을 분리된 상태로 실험해 왔기에, 어떤 요소가 실제 성능 향상을 견인하는지, 각 기법이 상호 어떻게 작용하는지에 대한 체계적인 이해가 부족합니다 [Figure 1]. 특히, LLM의 자유로운 생성(open-ended generation) 특성상 모델이 스스로 만든 Supervision 신호는 노이즈가 많고 불안정하며, 잘못된 추론 경로가 강화될 수 있다는 한계가 존재합니다.
Figure 1 — UniSD 전체 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 UniSD 프레임워크를 통해 Self-Distillation을 'Supervision 신뢰성', '표현 정렬(Representation Alignment)', '학습 안정성'이라는 3가지 축으로 체계화하고 모듈화합니다 [Figure 2]. Multi-Teacher Agreement와 Token-Level Contrastive Learning은 신뢰성 있는 신호를 식별하고 잘못된 신호를 억제하며, Feature Matching은 출력 분포를 넘어선 내부 표현 수준의 정렬을 수행합니다. 또한, EMA Teacher와 Divergence Clipping은 학습 과정의 급격한 변화를 방지하여 최적화의 안정성을 높입니다. 실험 결과, 제안하는 통합 파이프라인인 UniSD는 Qwen2.5-7B 베이스 모델 대비 전반적인 성능 점수를 67.9에서 73.3으로 +5.4 향상시켰으며, 기존 최강의 Baseline인 GKD보다 +2.8 더 우수한 성능을 기록하였습니다 [Table 1]. 특히 UniSD는 ScienceQA, MBPP, GPQA 등 다양한 벤치마크에서 일관된 성능 우위를 보였으며, 여러 모델 패밀리(Qwen2.5, Llama-3.1, Gemma-3)에 걸쳐 성공적으로 일반화되었습니다 [Figure 3].

Figure 2 — UniSD의 다중 보완적 학습 목표
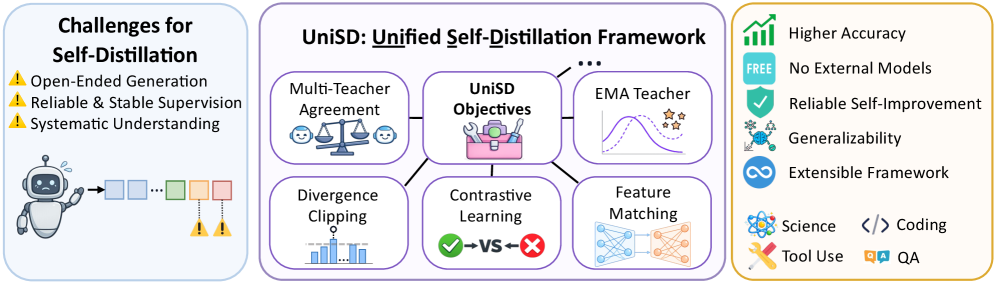
Figure 3 — 모델 크기별 성능 향상 및 분포 유지
4. Conclusion & Impact (결론 및 시사점)
본 연구는 UniSD를 통해 Self-Distillation의 다양한 구성 요소들이 어떻게 상호작용하여 학습 효율과 성능을 극대화하는지를 체계적으로 규명했습니다. 연구의 결과물인 UniSD*는 강력한 외부 Teacher 모델 없이도 효과적인 LLM 적응(adaptation)이 가능함을 입증하였으며, 이는 학계 및 산업계에서 비용 절감과 데이터 프라이버시 보호를 위한 필수적인 방법론이 될 것입니다. 이 연구는 단순히 성능 향상에 그치지 않고, 효율적이고 통제 가능한(steerable) LLM 학습을 위한 근본적인 통찰을 제공한다는 점에서 큰 학술적 가치를 지닙니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] On-Policy Self-Distillation for Reasoning Compression
- [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] Learn-by-Wire Training Control Governance: Bounded Autonomous Training Under Stress for Stability and Efficiency
- [논문리뷰] It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
Review 의 다른글
- 이전글 [논문리뷰] UniPrefill: Universal Long-Context Prefill Acceleration via Block-wise Dynamic Sparsification
- 현재글 : [논문리뷰] UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
- 다음글 [논문리뷰] What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
댓글