[논문리뷰] What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhengrong Yue, Taihang Hu, Mengting Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PAE (Prior-Aligned AutoEncoder): 본 논문에서 제안하는 tokenizer로, 단순 reconstruction을 넘어 diffusion 모델 학습에 최적화된 latent manifold를 명시적으로 형성하도록 설계된 프레임워크입니다.
- VFM (Vision Foundation Models): 학습된 강력한 시각적 특징을 제공하는 모델로, PAE의 semantic 및 structural prior를 구축하기 위한 기준점으로 활용됩니다.
- SSC (Spatial Structure Coherence): Latent token의 공간적 배치가 객체 단위의 구조적 정보를 얼마나 잘 보존하는지 측정하는 지표입니다.
- LPC (Local Perceptual Continuity): Latent 공간에서 국소적인 섭동(perturbation)이 발생했을 때 디코딩된 이미지의 지각적 변화가 얼마나 완만하고 안정적인지를 정량화하는 지표입니다.
- GSQ (Global Semantic Quality): Latent 공간에서 유사한 의미를 가진 샘플들이 얼마나 응집력 있게 분류되는지를 평가하여, 생성 모델의 조건부 학습 용이성을 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Latent Diffusion Models(LDMs)의 tokenizer들이 주로 reconstruction fidelity에만 초점을 맞추어 설계되어, 정작 확산 생성 모델의 학습에 적합한 latent space를 형성하지 못한다는 문제를 제기합니다 [Figure 1]. 기존 연구들은 단순히 reconstruction 성능을 높이거나 VFM의 특징을 상속받는 방식에 의존했으나, 이러한 접근은 생성 품질과 reconstruction 성능 사이의 미스매치를 초래합니다 [Figure 2]. 따라서 저자들은 diffusion 학습에 진정으로 친화적인(diffusion-friendly) latent manifold의 구성 요소가 무엇인지 규명하고, 이를 명시적으로 학습 목적함수에 반영해야 할 필요성을 강조합니다 [Figure 2].
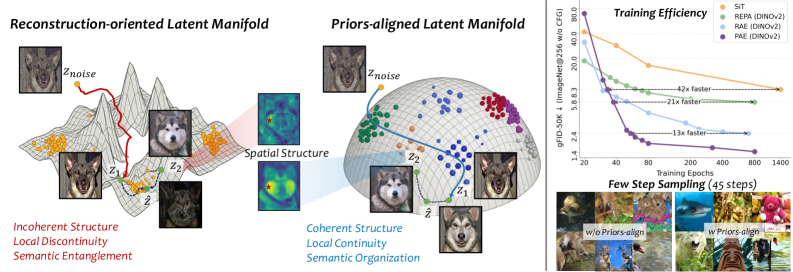
Figure 1 — PAE의 개념 및 생성 성능
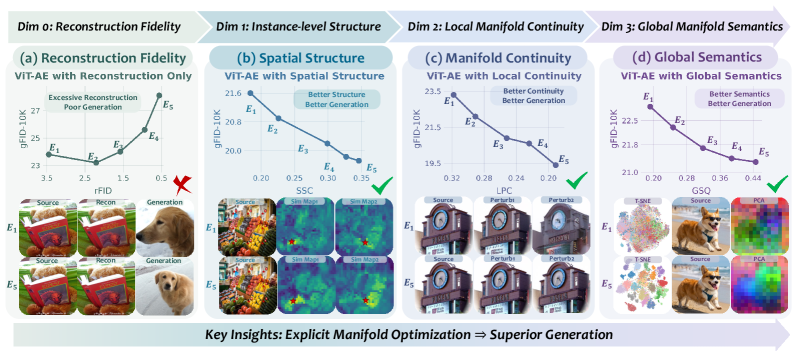
Figure 2 — 다양한 매니폴드 특성 분석
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 latent manifold의 세 가지 핵심 속성(Spatial Structure Coherence, Local Perceptual Continuity, Global Semantic Quality)을 학습하기 위한 Prior-Aligned AutoEncoder(PAE)를 제안합니다 [Figure 3]. PAE는 frozen VFM으로부터 추출된 특징을 Detail-aware Modulator (DAM)를 통해 정교화하고, 세 가지 목적함수(SSR, MCR, SCR)를 통해 latent 공간의 구조, 연속성, 의미론적 조직을 명시적으로 제어합니다 [Figure 3]. 특히, 고정된 VFM을 기반으로 bottleneck-matched target을 구축하여 alignment의 효율성을 극대화했습니다 [Figure 4]. 실험 결과, PAE는 ImageNet 256×256 환경에서 기존 tokenizer 대비 압도적인 효율성을 보였습니다 [Table 1]. LightningDiT 설정에서 PAE는 기존 RAE와 동등한 성능을 13배 적은 학습 epoch으로 달성했으며, 최종적으로 1.03 gFID라는 새로운 state-of-the-art를 기록했습니다 [Table 1]. 또한, PAE는 고품질의 이미지 생성뿐만 아니라 적은 denoising step(45 steps)에서도 높은 생성 품질(1.05 gFID)을 유지하는 강건함을 입증했습니다 [Figure 5, Figure 7].
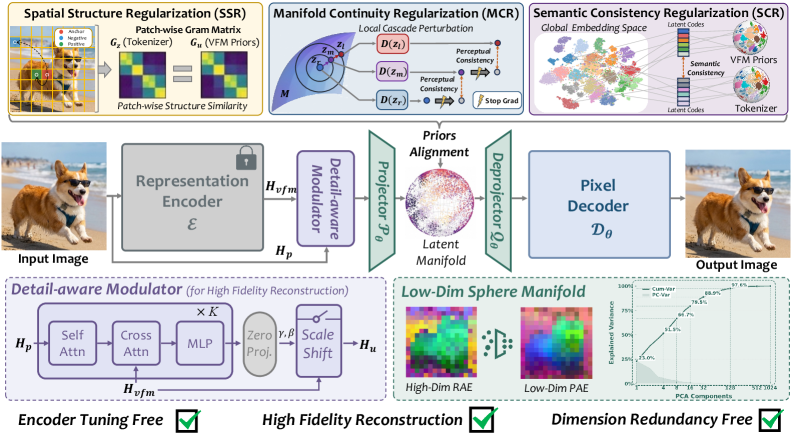
Figure 3 — PAE 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 reconstruction fidelity보다 latent manifold의 기하학적 조직화가 확산 생성 모델의 학습 효율과 품질에 더 직접적인 영향을 미친다는 점을 명확히 규명했습니다. PAE 프레임워크는 latent manifold를 명시적으로 구성함으로써 고성능 generative modeling의 새로운 설계 원칙을 제시했습니다. 이 연구는 향후 효율적이고 고품질의 latent diffusion 모델을 구축하려는 학계 및 산업계 연구에 중요한 가이드라인을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
- [논문리뷰] Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
- [논문리뷰] Where to cut, how deep: BPE and Unigram-LM on chemistry SMILES
- [논문리뷰] SiamJEPA: On the Role of Siamese Student Encoders in JEPA
- [논문리뷰] Quantifying and Expanding the Theoretical Capacity of Late-Interaction Retrieval Models
Review 의 다른글
- 이전글 [논문리뷰] UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
- 현재글 : [논문리뷰] What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
- 다음글 [논문리뷰] What if AI systems weren't chatbots?
댓글