[논문리뷰] TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Minjie Qiang, Mingming Zhang, Xiaoyi Bao, Xing Fu, Yu Cheng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- TabBench: 논문에서 제안하는 tabular embedding 모델의 수치적 추론 및 검색 능력을 평가하기 위한 포괄적인 벤치마크 스위트입니다.
- TabEmbed: tabular classification과 retrieval을 공유된 임베딩 공간에서 통합하는 최초의 일반적인(generalist) 임베딩 모델입니다.
- Task-Adaptive Query Generation: tabular 데이터를 자연어 쿼리로 변환하여, 다양한 tabular 과제를 의미론적 매칭(semantic matching) 문제로 재구성하는 방법론입니다.
- Positive-Aware Hard Negative Mining: 훈련 과정에서 모델이 미세한 차이를 판별하도록 유도하기 위해, 의미적으로는 유사하나 실제 조건은 만족하지 않는 샘플을 hard negative로 사용하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 자연어 처리에 성공한 것과 달리, tabular 데이터를 위한 통합된 representation 패러다임이 부재하다는 점을 해결하고자 합니다 [Figure 1]. 기존 모델들은 tabular classification과 retrieval을 별개의 과제로 처리하며, 특히 텍스트 기반 임베딩 모델은 serialized table을 구조적 정보가 결여된 텍스트로 취급하여 수치적 의미나 컬럼 간 관계를 제대로 포착하지 못합니다. 또한, 기존 row-to-row contrastive 학습은 데이터 간 의미적 풍부함을 희생하고 coarse한 클래스 군집으로 수렴하는 한계가 있습니다. 이를 위해 저자들은 구조적 이해가 가능한 범용적인 tabular embedding 모델의 필요성을 제기합니다.
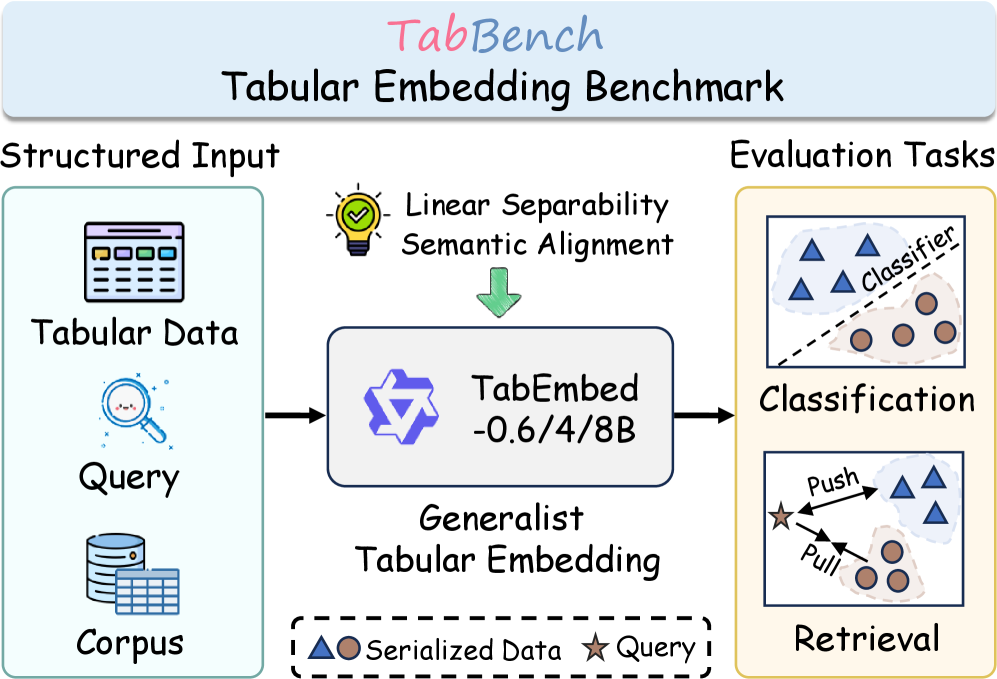
Figure 1 — TabBench 및 TabEmbed 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 tabular 이해 과제를 언어-행(language-to-row) 매칭 문제로 재정의하는 TabEmbed 프레임워크를 제안합니다 [Figure 3]. 이 방법론은 세 가지 핵심 요소를 포함합니다: (1) tabular 데이터를 자연어 시퀀스로 변환하는 serialization 파이프라인, (2) 동적으로 생성된 자연어 쿼리를 앵커로 활용하는 contrastive learning, (3) 성능 향상을 위한 positive-aware hard negative mining입니다. 실험 결과, TabEmbed는 기존 최신(SOTA) 텍스트 임베딩 모델들을 모든 parameter scale에서 압도합니다 [Table 1]. 특히, TabEmbed-0.6B는 기존 backbone인 Qwen3-Embedding-0.6B 대비 MRR@10 지표에서 35점 이상의 성능 향상을 보이며 매우 높은 parameter 효율성을 입증했습니다. 또한, 본 모델은 수치적 감수성(Numerical Sensitivity) 테스트에서 높은 Spearman correlation을 기록하며 모델이 수치적 magnitude를 효과적으로 이해하고 있음을 정량적으로 증명했습니다 [Figure 6].
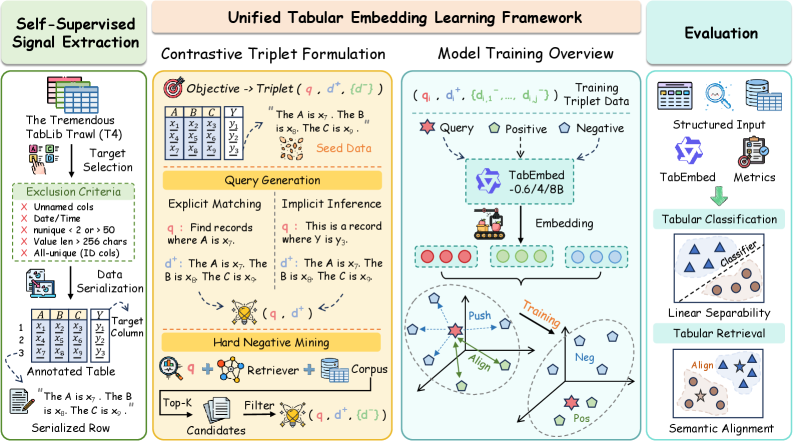
Figure 3 — TabEmbed 프레임워크
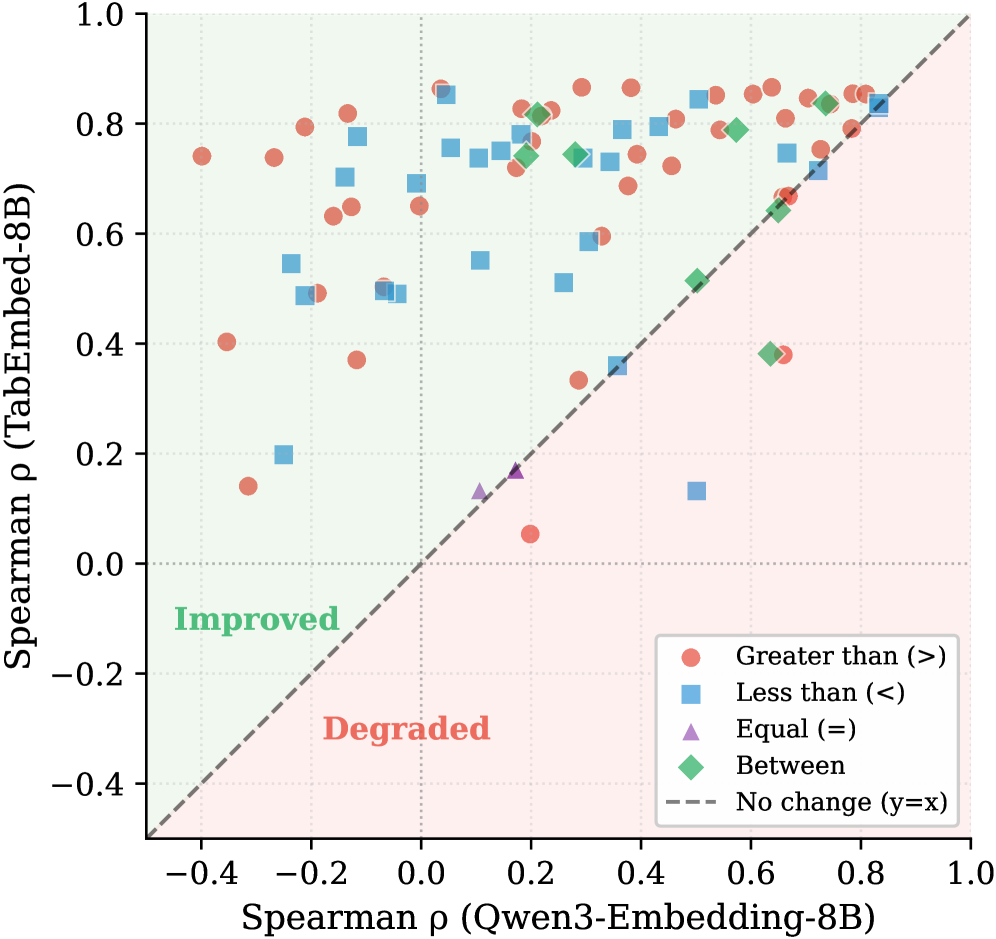
Figure 6 — 수치적 감수성 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 tabular 이해를 위한 통합 임베딩 학습 패러다임인 TabEmbed를 성공적으로 구축하였습니다. 이 연구는 tabular domain이 parameter scaling보다 도메인 맞춤형 contrastive learning을 통해 더 큰 성능 발전을 이룰 수 있음을 보여줍니다. 학계와 산업계에 제공하는 TabBench는 향후 tabular foundational model 연구의 기준점이 될 것으로 예상되며, 본 연구 결과는 tabular 데이터 검색, 엔터프라이즈 데이터 발견, 그리고 제로샷 예측 분야에 실질적인 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PixCon: Clean-Positive Contrastive Learning for Foundation-Model Semi-Supervised Segmentation
- [논문리뷰] MERIT: Learning Disentangled Music Representations for Audio Similarity
- [논문리뷰] SciLT: Long-Tailed Classification in Scientific Image Domains
- [논문리뷰] InfoNCE Induces Gaussian Distribution
- [논문리뷰] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Review 의 다른글
- 이전글 [논문리뷰] SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
- 현재글 : [논문리뷰] TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
- 다음글 [논문리뷰] The Scaling Properties of Implicit Deductive Reasoning in Transformers
댓글