[논문리뷰] The Scaling Properties of Implicit Deductive Reasoning in Transformers
링크: 논문 PDF로 바로 열기
저자: Enrico Vompa, Tanel Tammet
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Horn clauses: 논리 프로그래밍의 기초가 되는 문장 형태이며, 본 논문에서는 Transformer가 이 구조 위에서 수행하는 연역적 추론을 학습하고 평가합니다.
- Proof depth ($\delta$): Forward-chaining을 통해 쿼리가 도출되는 breadth-first search(BFS)의 레이어 인덱스로, 추론 문제의 논리적 복잡도를 나타냅니다.
- r2 heuristic: 데이터셋 내의 spurious features(가짜 특징)와 provability(증명 가능성) 사이의 상관관계를 제거하기 위해 고안된 데이터 증강 기법입니다.
- Corrective objective: 모델의 direct prediction과 Chain-of-Thought(CoT) 추론 경로를 하나의 시퀀스로 통합 최적화하여, 두 방식 간의 reasoning primitives를 정렬하는 훈련 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 depth-bounded Transformer가 내재적(implicit)으로 수행하는 연역적 추론의 확장성(scaling) 한계를 규명합니다. 기존 연구들은 Transformer가 논리 문제를 해결할 수 있음을 보여주었으나, 이는 종종 실제 추론이 아닌 훈련 데이터의 spurious features에 의존하는 'shortcut learning'에 불과하다는 한계가 있습니다. Transformer 모델은 sequential algorithm을 충실히 수행하기보다, gradient descent 과정에서 저복잡도(low-complexity) 근사 함수를 학습하려는 bias를 가지고 있습니다. 이에 따라 저자들은 이러한 shortcut bias를 제거하고, 모델의 깊이(depth)와 차원(dimensionality)이 복잡도 및 정보 이론적 관점에서 추론 능력에 미치는 영향을 체계적으로 조사합니다. [Figure 1]
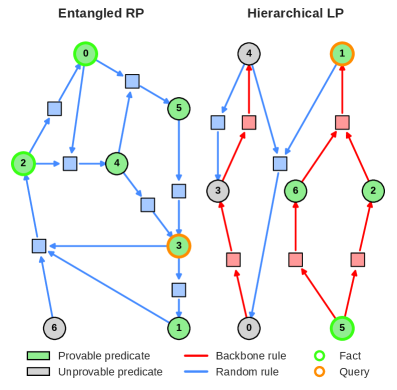
Figure 1 — RP와 LP 문제의 증명 깊이 δ
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 shortcut bias를 해결하기 위해 r2 heuristic, bidirectional prefix masking, corrective objective라는 세 가지 상호 보완적인 기법을 도입합니다. r2 heuristic은 라벨은 다르지만 superficial feature는 동일한 문제 쌍을 생성하여, 모델이 특징값 자체를 추론 근거로 활용하는 것을 방해합니다. Bidirectional prefix masking은 문제 전체에 대한 visibility를 보장하여 sequential bias를 제거하며, corrective objective는 direct prediction이 CoT의 reasoning primitives를 공유하도록 강제합니다. [Figure 4] 실험 결과, 충분한 레이어 깊이(L)를 갖춘 모델에서는 이 기법들을 통해 Implicit reasoning 성능이 explicit CoT 성능에 근접함을 확인했습니다. 특히, 모델의 깊이(L)를 scaling 할수록 복잡한 그래프 토폴로지에서도 direct와 CoT 간의 reasoning gap이 유의미하게 좁혀지는 현상을 정량적으로 증명했습니다. [Figure 6]
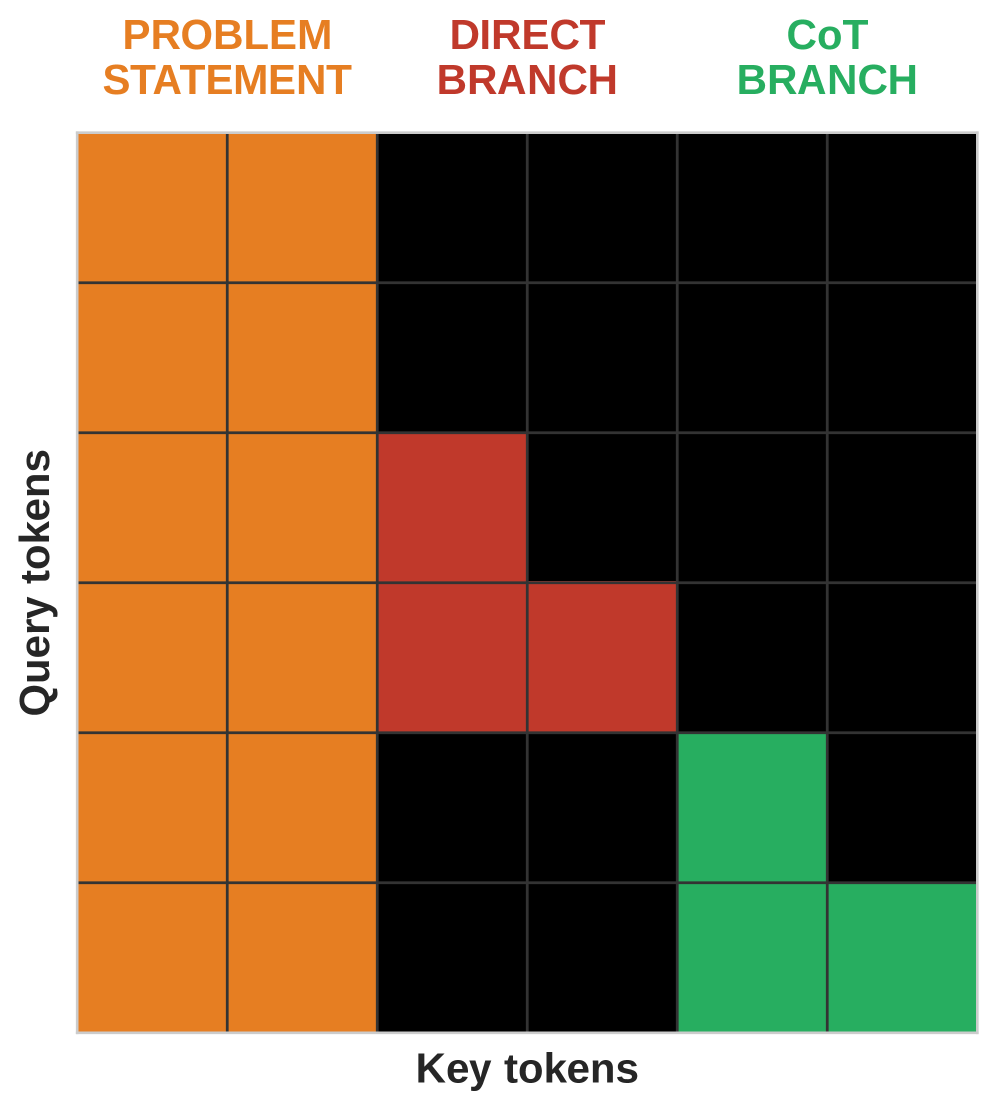
Figure 4 — 추론 브랜치별 attention mask
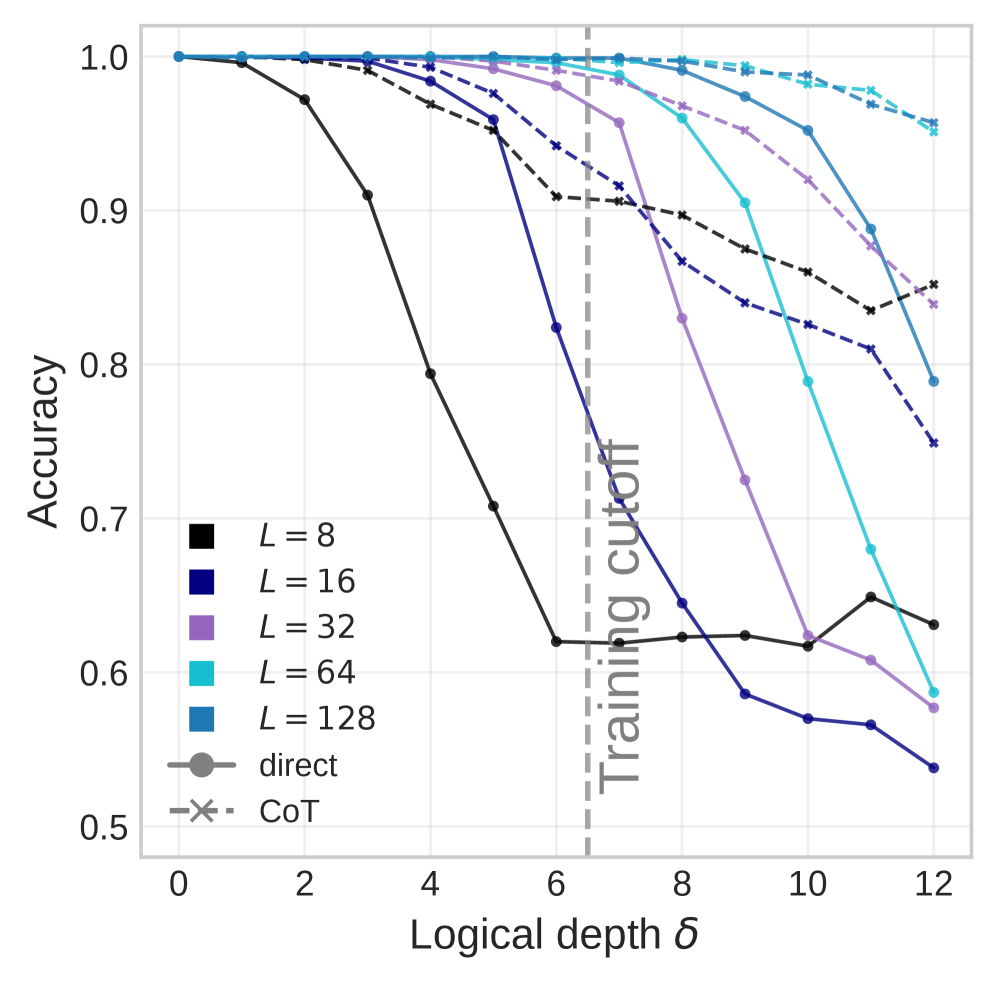
Figure 6 — 모델 깊이에 따른 성능 간극 감소
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 depth-bounded Transformer가 연역적 추론을 근사할 때 가지는 computational limit와 이를 극복하기 위한 아키텍처적 정렬의 중요성을 명확히 했습니다. 결론적으로, 모델의 깊이를 scaling 하는 것은 추론의 충실도(faithfulness)를 높이는 데 필수적이며, 적절한 algorithmic alignment를 통해 implicit 방법론이 더 효율적인 추론으로 나아갈 수 있음을 시사합니다. 본 연구는 향후 LLM의 내부 reasoning process를 해석하고, 더욱 견고한 neuro-symbolic 시스템을 구축하는 데 중요한 기술적 토대를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Chain-of-Thought Degrades Visual Spatial Reasoning Capabilities of Multimodal LLMs
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
- [논문리뷰] ReasoningLens: Hierarchical Visualization and Diagnostic Auditing for Large Reasoning Models
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
Review 의 다른글
- 이전글 [논문리뷰] TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
- 현재글 : [논문리뷰] The Scaling Properties of Implicit Deductive Reasoning in Transformers
- 다음글 [논문리뷰] 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
댓글