[논문리뷰] 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhangquan Chen, Manyuan Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- 4DThinker: Monocular video에서 4D(3D 공간 + 시간) 동적 장면을 이해하기 위해 Latent Mental Imagery를 활용하는 VLM 프레임워크입니다.
- Dynamic-Imagery Fine-Tuning (DIFT): 텍스트 토큰과 Latent Visual Tokens를 결합하여 모델이 동적 시각적 의미를 내재적으로 시뮬레이션하도록 지도 학습(Supervised Learning)하는 단계입니다.
- 4D Reinforcement Learning (4DRL): GRPO를 수정하여, 복합적인 움직임 추론 시 텍스트 토큰에만 경사도(Gradient)를 제한하여 학습을 안정화하고 결과 기반 보상을 제공하는 강화 학습 단계입니다.
- Latent Visual Tokens: 영상의 시각적 정보를 압축한 연속적인 임베딩으로, 모델의 숨겨진 공간(Hidden Space) 내에서 동적 장면을 시뮬레이션하는 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLM이 동적 공간 추론에서 겪는 불투명성과 성능 한계를 해결하기 위해 4DThinker를 제안합니다. 기존 연구들은 추론 과정을 텍스트로만 기술하거나 외부 기하학적 모듈을 의존하여 추론 복잡도를 증가시키고 모델 자체의 내재적 능력을 제한하는 한계를 보입니다 [Figure 1]. 또한, 동적 장면의 복잡성을 언어만으로 정밀하게 묘사하는 것은 본질적으로 어렵습니다. 이러한 문제를 극복하기 위해 본 연구는 모델이 내부적으로 동적 장면의 변화를 시뮬레이션할 수 있는 내재적 4D 추론 프레임워크를 개발하는 것을 목표로 합니다.
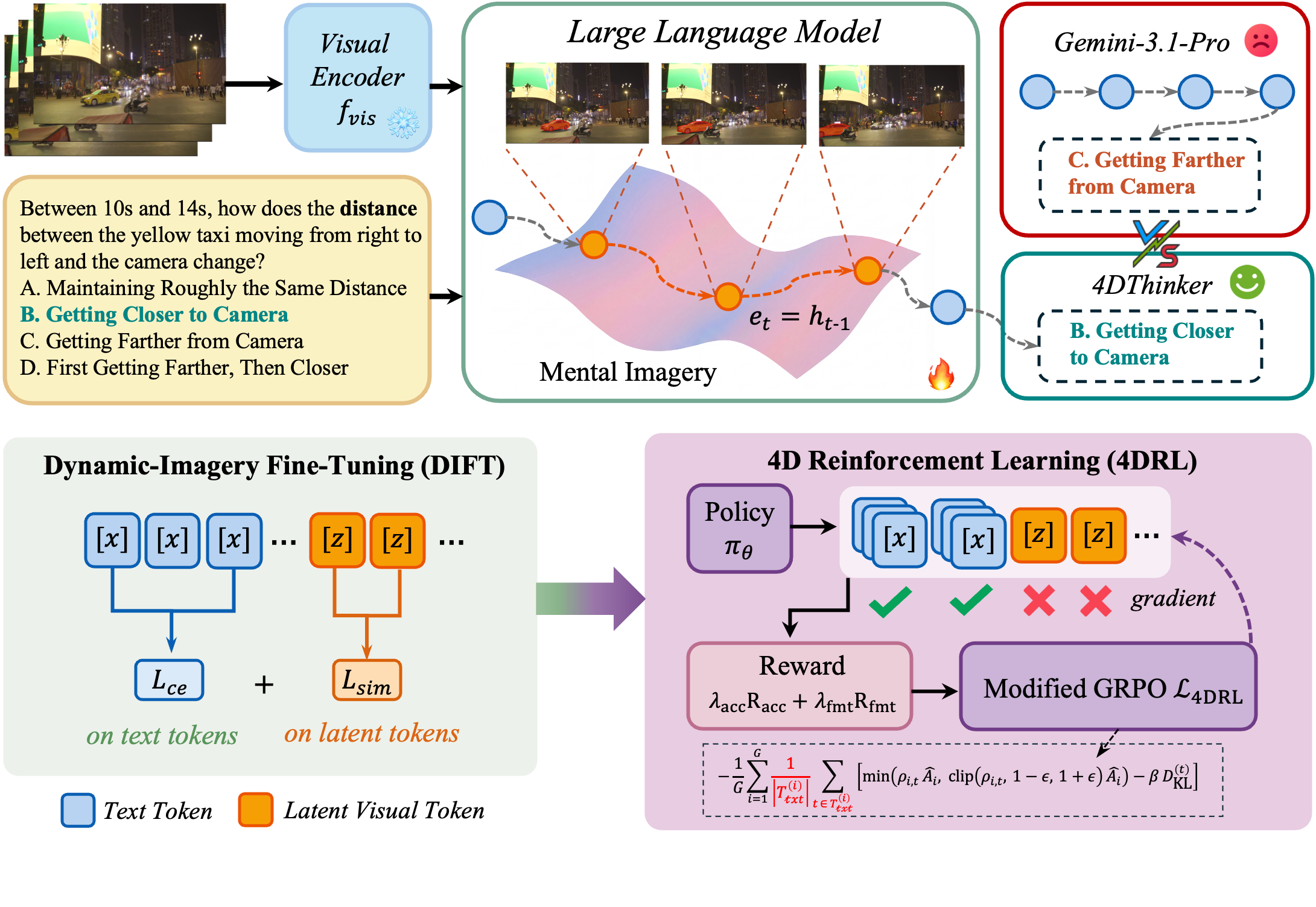
Figure 1 — 4DThinker 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 주석 없이 대규모 비디오 데이터에서 4D 추론 정보를 생성하는 Scalable, Annotation-free Pipeline을 통해 데이터를 구성하고, 이를 바탕으로 DIFT와 4DRL이라는 2단계 학습 전략을 제안합니다 [Figure 2]. 제안 모델은 비디오를 전처리하여 정적/동적 객체를 식별하고, 이를 통해 생성된 시각적 마스크 오버레이를 모델의 Latent Visual Tokens로 투영하여 학습합니다. 주요 실험 결과로 DSR-Bench에서 Qwen3-VL-32B 기반의 4DThinker가 62.0%의 정확도를 기록하여, Gemini-2.5-Pro(31.7%) 및 기존 SOTA 모델인 DSR Suite-Model(58.9%)을 크게 능가했습니다 [Table 1]. 또한 Dyn-Bench에서도 평균 75.4%의 정확도를 달성하며 동적 장면 이해 성능의 우수성을 입증했습니다 [Table 2].
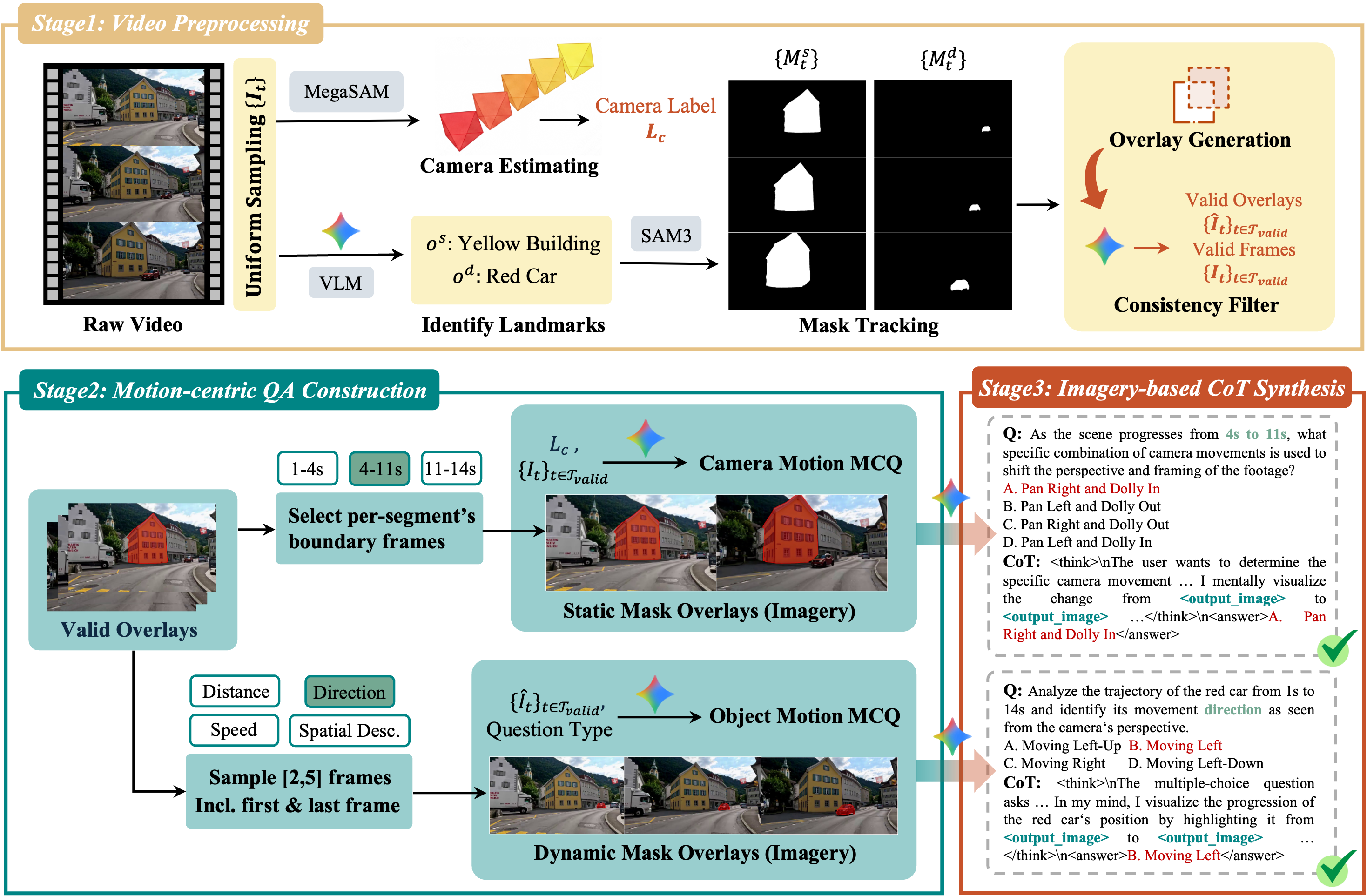
Figure 2 — 데이터 생성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Latent Visual Tokens를 활용한 "Think with 4D" 프레임워크인 4DThinker를 통해 VLM이 물리 세계의 동적 변화를 직접 시뮬레이션할 수 있는 내재적 능력을 갖출 수 있음을 입증했습니다. 이 연구는 외부 기하학적 모듈 의존 없이도 복잡한 시공간적 추론을 가능하게 함으로써 로봇 공학 및 자율 주행 분야에 중요한 시사점을 제공합니다. 본 방법론은 차세대 멀티모달 모델 설계에 있어 기하학적 정보의 효율적인 내재화 방향성을 제시하였다는 평가를 받습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
Review 의 다른글
- 이전글 [논문리뷰] The Scaling Properties of Implicit Deductive Reasoning in Transformers
- 현재글 : [논문리뷰] 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
- 다음글 [논문리뷰] AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
댓글