[논문리뷰] Unlocking Dense Metric Depth Estimation in VLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hanxun Yu, Xuan Qu, Yuxin Wang, Jianke Zhu, Lei Ke
1. Key Terms & Definitions (핵심 용어 및 정의)
- Dense Metric Depth Estimation: 이미지의 각 픽셀에 대해 실제 거리(미터 단위)를 절대적 수치로 복원하는 3D 컴퓨터 비전 과업입니다.
- VLM (Vision-Language Models): 시각적 입력과 텍스트 정보를 통합적으로 처리하여 추론하는 거대 멀티모달 모델로, 본 논문에서는 Depth 예측의 백본으로 사용됩니다.
- Unified Vision-Text Supervision: 저자들이 제안한 학습 방식으로, 모델이 텍스트 응답뿐만 아니라 픽셀 단위의 정밀한 기하학적 정보(Depth)를 단일 Forward pass에서 동시에 생성하도록 강제합니다.
- DPT (Dense Prediction Transformer): 이미지의 중간 계층 특징(feature)을 활용하여 고해상도 밀집 예측을 수행하는 아키텍처로, 본 논문에서는 경량화된 Depth Head로 채택되었습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLMs가 2D 과업에는 뛰어나지만 3D 이해 능력은 여전히 제한적이라는 핵심 문제에서 출발합니다 [Figure 1]. 기존 연구들은 외부의 3D 전문 모델로부터 지식을 증류하거나, 텍스트 기반으로만 학습하여 정밀한 기하학적 정보가 부족하고 오류가 누적되는 한계를 보입니다. 또한, 최신 연구들은 개별 픽셀에 대해 반복적인 Query를 수행하여 추론 속도가 매우 느리거나, 출력 정보가 지나치게 거칠어 세부적인 공간 구조를 반영하지 못하는 문제점을 안고 있습니다 [Figure 2]. 따라서 본 연구는 VLM의 범용적인 멀티모달 능력을 훼손하지 않으면서, 단일 Forward pass로 고해상도의 밀집 Depth 맵을 출력할 수 있는 효율적인 Native Dense Geometry Predictor를 구축하고자 합니다.
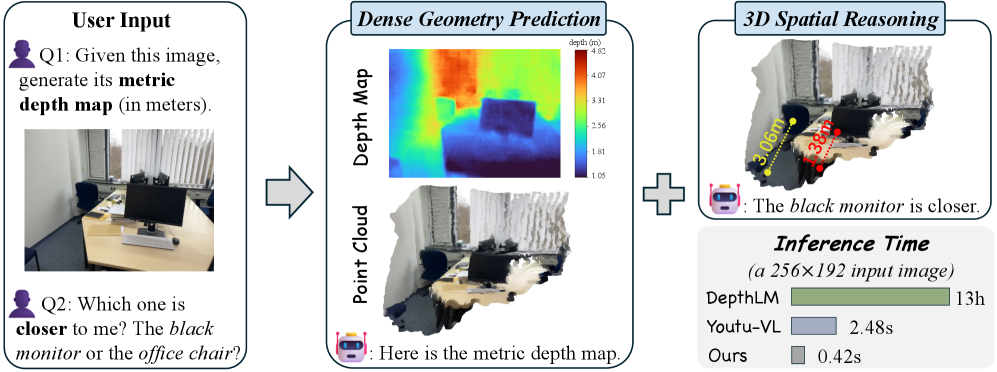
Figure 1 — DepthVLM의 모델 개요 및 통합 능력
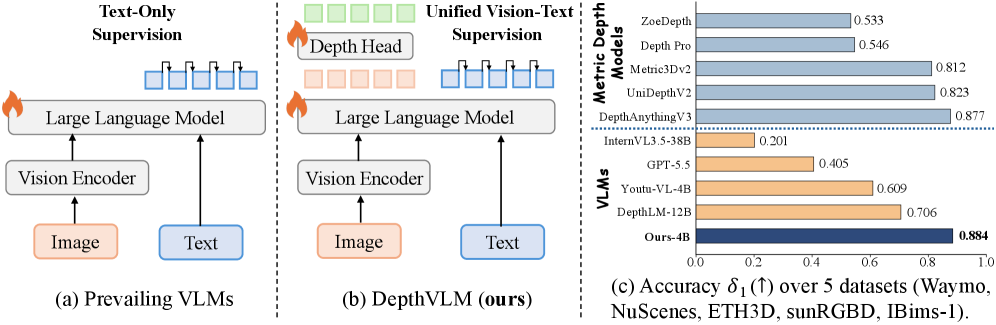
Figure 2 — 기존 VLM 대비 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 VLM 백본에 경량화된 DPT-style Depth Head를 추가하고, Two-Stage Training Strategy를 통해 모델을 최적화하는 DepthVLM을 제안합니다 [Figure 3]. 1단계에서는 고정된 VLM 하에서 Depth Head만을 학습하여 초기 기하학적 예측 능력을 확보하며, 2단계에서는 LLM 백본을 포함하여 End-to-End로 파인튜닝함으로써 공간 추론과 멀티모달 이해를 조화시킵니다. 또한, 다양한 센서 데이터 간의 스케일 문제를 해결하기 위해 Focal-Length Normalization 기법을 적용하여 학습 데이터의 일관성을 확보했습니다 [Figure 3].
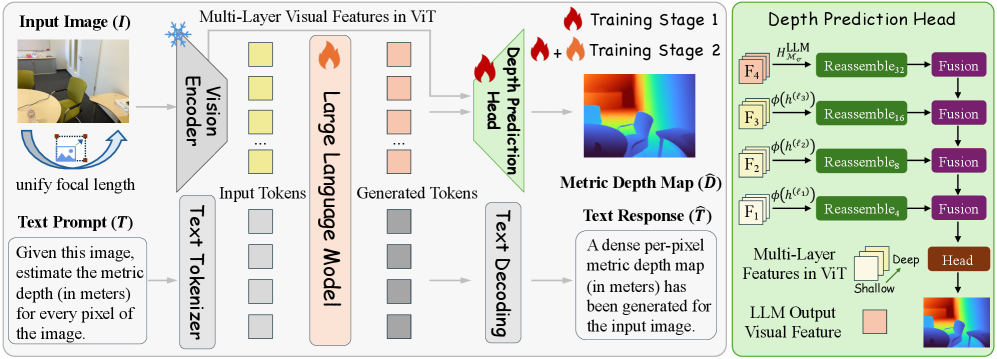
Figure 3 — DepthVLM 아키텍처 상세
실험 결과, DepthVLM은 기존 VLM 기반 접근 방식 대비 월등한 추론 효율성을 입증하였습니다. 특히, 256×192 해상도 기준 Latency 측면에서 기존 방식이 수 초(s) 이상 소요되는 반면, 제안 모델은 0.42s만에 처리가 가능하여 효율성을 극대화하였습니다 [Table 8]. 정량적 평가 지표인 δ1 성능에서도 기존의 최첨단 VLM 및 순수 비전 모델(Pure Vision Models)을 능가하는 수치를 기록하며, 다양한 Indoor 및 Outdoor 데이터셋에서 일관된 우위를 보였습니다 [Table 1, Table 2]. 또한, MMB-EN 및 OCRBench 등 범용 시각 벤치마크에서도 기존 성능을 유지하거나 향상시켜 멀티모달 능력이 보존됨을 검증하였습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLM이 별도의 외부 모델 증류 없이도 그 자체로 강력한 밀집 기하학적 예측기가 될 수 있음을 입증하며, 저수준의 기하학적 예측과 고수준의 멀티모달 이해를 하나의 모델에 통합하는 데 성공했습니다. DepthVLM은 기존의 복잡한 3D 학습 파이프라인을 단순화하고, 3D 공간 추론 과업에서 더 나은 성능을 도출할 수 있는 토대를 마련했습니다 [Figure 4]. 이 연구는 로봇 공학, AR/VR, 자율주행 등 정밀한 3D 이해가 필요한 산업계 멀티모달 모델 설계에 중요한 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
- [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
- [논문리뷰] SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
Review 의 다른글
- 이전글 [논문리뷰] Steered LLM Activations are Non-Surjective
- 현재글 : [논문리뷰] Unlocking Dense Metric Depth Estimation in VLMs
- 다음글 [논문리뷰] WorldAct: Activating Monolithic 3D Worlds into Interactive-Ready Object-Centric Scenes
댓글