[논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
링크: 논문 PDF로 바로 열기
메타데이터
저자: Harold Haodong Chen, Sirui Chen, Yingjie Xu, Wenhang Ge, Ying-Cong Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLM (Vision-Language Model) Planner: 로봇의 작업 계획을 수립하고 고수준의 의미론적 추론을 담당하는 에이전트의 두뇌 역할을 수행하는 모델입니다.
- VGM (Video Generation Model) Simulator: 물리적 타당성을 갖춘 비디오 생성 모델로서, 로봇이 수행할 작업의 시뮬레이션 환경으로 사용됩니다.
- Atomic Action: 로봇이 수행하는 가장 기본적인 단위 작업(예:
pick,place)으로, 본 논문에서는 전체 복합 작업을 분해하는 기초 구성 요소입니다. - Complementary Learning Systems (CLS): 인간의 뇌가 경험을 탐색하고 통합하는 과정에서 착안한 이론으로, 본 논문에서는 Daytime(탐색)과 Nighttime(통합)의 이중 위상 학습 루프를 설계하는 근거가 됩니다.
- GRPO (Group Relative Policy Optimization): 에이전트가 생성한 다수의 계획 및 궤적 중 상대적 우위를 평가하여 정책을 최적화하는 학습 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 로봇 조작(Robotic Manipulation) 분야에서 작업에 최적화된 물리적 상호작용 데이터가 부족하다는 근본적인 문제를 해결하고자 합니다. 기존 방식인 VLM 기반 플래너는 의미론적 이해는 뛰어나지만 물리적 기반이 부족하여 실행 불가능한 계획을 생성하는 한계가 있고, VGM 기반 시뮬레이터는 물리적 환각(Physical Hallucination) 문제로 인해 정교한 작업 수행에 어려움을 겪습니다 [Figure 1]. 이러한 데이터 고립 문제와 상호작용 데이터의 희소성을 해결하기 위해, 저자들은 플래너와 시뮬레이터가 서로를 감독하고 보완하며 진화하는 Co-Evolving 프레임워크를 제안합니다.
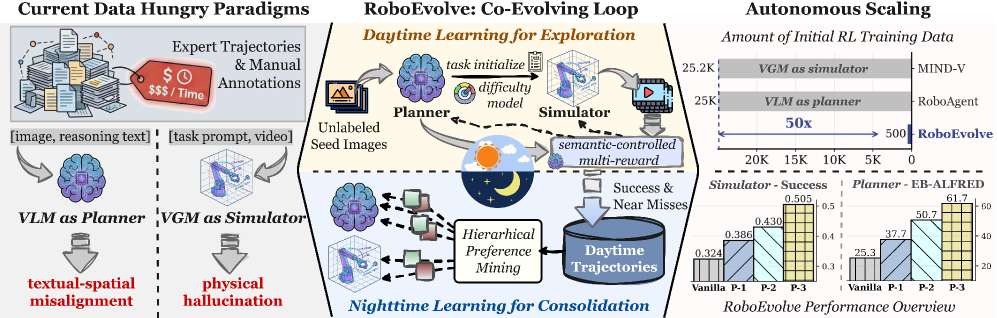
Figure 1 — RoboEvolve의 Co-Evolving 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RoboEvolve라는 이중 위상 자가 진화 프레임워크를 제안합니다. Daytime 단계에서는 Semantic-controlled Multi-Granular Reward를 사용하여 다양한 작업을 탐색하고 물리적 사실성을 검증하며, Nighttime 단계에서는 실패 사례(Near-miss failures)로부터 학습하여 Hierarchical Preference Optimization을 수행, 정책을 안정화합니다 [Figure 2]. 실험 결과, RoboEvolve는 기본 플래너 대비 EB-ALFRED 및 EB-Habitat 벤치마크에서 각각 평균 36.4점, 24.6점의 절대적 성능 향상을 달성했습니다 [Table 2]. 또한, 단 500개의 unlabeled seed 이미지만을 사용하여 기존의 완전 지도 학습(Fully Supervised) 베이스라인을 능가하는 극도의 데이터 효율성을 입증하며, 50배 이상의 데이터 비용 절감 효과를 보였습니다 [Figure 1, Figure 6].
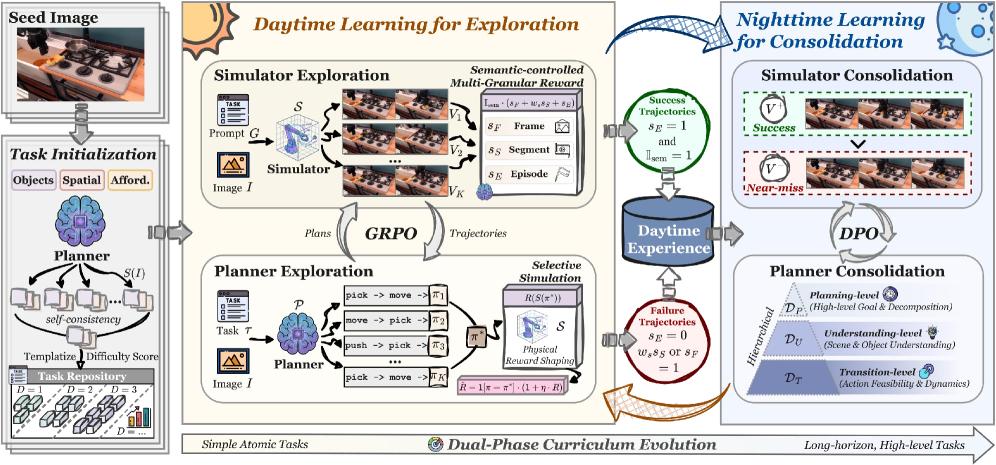
Figure 2 — RoboEvolve 전체 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 레이블 없는 원시 데이터를 활용하여 로봇이 스스로 학습하고 진화하는 RoboEvolve를 성공적으로 제시하였습니다. 이 연구는 대규모 수동 주석 데이터에 의존하던 기존의 로봇 학습 패러다임을 자율적인 자기 개선형(Autonomous Self-improvement) 모델로 전환하는 중요한 이정표를 세웠습니다. 학계와 산업계는 이 프레임워크를 통해 컴퓨팅 자원이 제한적인 환경에서도 고도로 숙련된 로봇 조작 모델을 구축할 수 있게 되며, 범용 물리 지능(General-purpose Physical Intelligence)으로 나아가는 확장 가능한 경로를 확보하게 됩니다.

Figure 3 — RoboEvolve 정성적 결과 예시
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
Review 의 다른글
- 이전글 [논문리뷰] Revisiting DAgger in the Era of LLM-Agents
- 현재글 : [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
- 다음글 [논문리뷰] SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
댓글