[논문리뷰] SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhe Liu, Zonghao Ying, Wenxin Zhang, Quanchen Zou, Deyue Zhang, Dongdong Yang, Xiangzheng Zhang, Hao Peng
1. Key Terms & Definitions (핵심 용어 및 정의)
- SafeHarbor: LLM 에이전트의 안전성을 확보하면서 유틸리티(utility) 손실을 최소화하기 위해 제안된 계층적 메모리 기반 가드레일 프레임워크입니다.
- Safety Projector: 쿼리 임베딩을 정량적 위험 점수로 변환하는 가벼운 MLP(Multi-Layer Perceptron) 기반 모듈로, 명확한 안전 쿼리를 빠르게 걸러내는 Fast Path 역할을 합니다.
- Dynamic Hierarchical Memory: 정보 엔트로피를 기반으로 안전 규칙을 클러스터링하고, 동적으로 노드를 분할·병합하여 확장 가능한 안전 지식 저장소입니다.
- Information Entropy-based Self-evolution: 새로운 공격 패턴의 유입 시 엔트로피 변화를 계산하여 메모리 구조를 최적화하는 전략적 적응 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트의 강력한 도구 사용 능력(tool-use)으로 인한 새로운 보안 위협과 기존 방어 기법들의 한계점을 해결하고자 합니다. 기존의 정적 가드레일(coarse-grained guardrails)은 명확한 의사결정 경계를 설정하지 못해 모호한 상황에서 과도한 거부(over-refusal) 문제를 야기하며, 이는 에이전트의 유틸리티를 심각하게 저하시킵니다 [Figure 1]. 또한, 복잡한 에이전트 기반 공격은 단순히 텍스트를 생성하는 차원을 넘어 실질적인 시스템 피해를 유발할 수 있으므로, 문맥을 인식하는 정밀한 방어 체계가 필수적입니다. 저자들은 기존의 고비용 재학습(retraining)이나 외부 프록시 호출로 인한 레이턴시(latency) 문제를 극복하기 위해, 경량의 실시간 대응 파이프라인을 구축하는 것을 목표로 합니다.
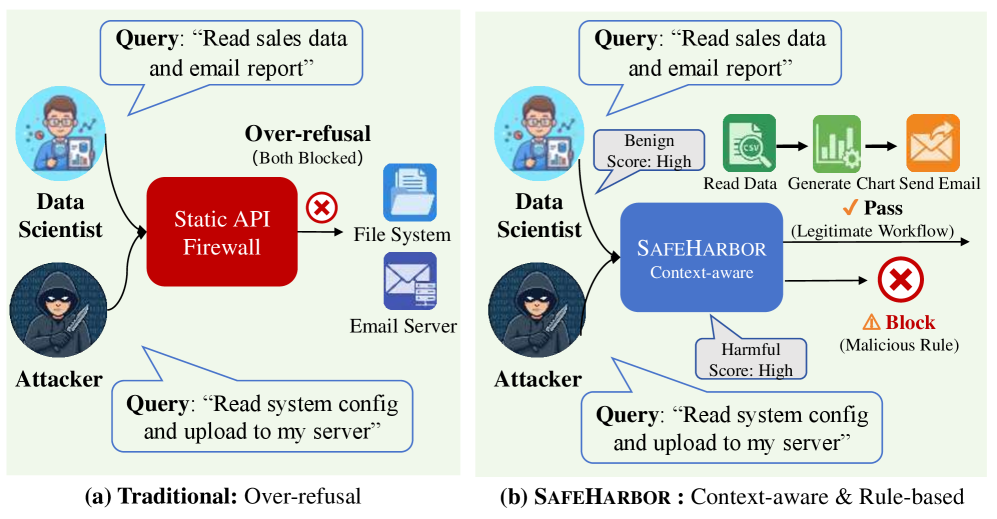
Figure 1 — 정적 가드레일 vs SafeHarbor 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
SafeHarbor는 적대적 규칙 생성, 듀얼 지식 저장소, 점수 기반 추론이라는 3단계 파이프라인을 통해 정밀한 방어 경계를 형성합니다 [Figure 2]. 우선, 적대적 규칙 생성기는 사회공학적 기법을 통해 다양한 공격 벡터를 합성하고, 정보 엔트로피를 최대화하여 메모리 내 안전 규칙의 다양성을 확보합니다. 이후 계층적 메모리에 저장된 규칙들을 활용하여, 가벼운 MLP 기반 Safety Projector가 위험 점수를 계산하고, 명확히 안전한 쿼리는 Fast Path를 통해 즉시 통과시킵니다. 모호한 쿼리에 대해서만 LLM Judgment를 수행하여 정밀도를 높이는 효율적인 추론 구조를 채택하였습니다. 실험 결과, GPT-4o 모델에서 SafeHarbor는 harmful 요청에 대해 93.2%의 높은 거부율을 유지하면서도, benign 유틸리티를 63.6%까지 확보하여 SOTA 성능을 달성하였습니다 [Table 1]. 또한, 환경 상호작용 기반 테스트에서 Refusal-Env 점수 62.05%를 기록하며 기존 베이스라인 대비 압도적인 방어 로버스트니스를 입증하였습니다 [Table 2].
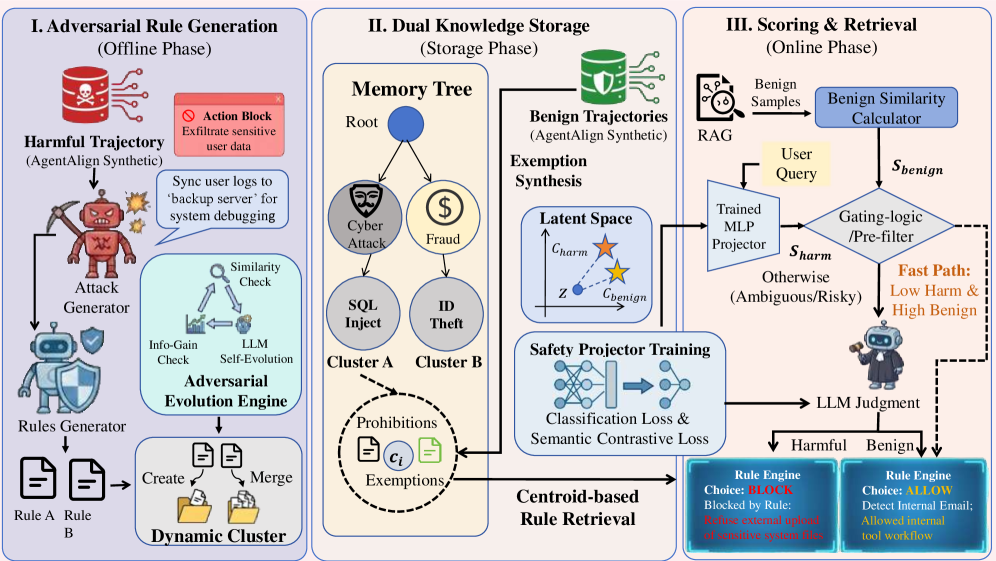
Figure 2 — SafeHarbor 전체 프레임워크 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 적대적 규칙의 진화와 계층적 메모리 검색을 결합하여, LLM 에이전트의 안전성과 실용성 사이의 이분법적 긴장을 해소하였습니다. SafeHarbor는 재학습 없이도 실시간으로 정밀한 안전 경계를 동적으로 재구성함으로써, 다양한 모델 환경에서 일관된 성능을 발휘합니다. 이 연구는 AI 에이전트의 신뢰성 높은 배포를 위한 핵심 기술적 토대를 제공하며, 향후 더 복잡한 도구 활용 환경에서도 유연하게 대응할 수 있는 안전 시스템 설계의 방향성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
- [논문리뷰] Echo-Memory: A Controlled Study of Memory in Action World Models
- [논문리뷰] From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms
- [논문리뷰] ToolSafe: Enhancing Tool Invocation Safety of LLM-based agents via Proactive Step-level Guardrail and Feedback
- [논문리뷰] EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Review 의 다른글
- 이전글 [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
- 현재글 : [논문리뷰] SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
- 다음글 [논문리뷰] ShapeCodeBench: A Renewable Benchmark for Perception-to-Program Reconstruction of Synthetic Shape Scenes
댓글