[논문리뷰] From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinghao Luo, Yuchen Tian, Chuxue Cao, Ziyang Luo, Hongzhan Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Storage: 과거의 상호작용 궤적(interaction trajectory)을 최소한의 변형으로 충실하게 기록하여 LLM의 제한된 context window를 극복하는 기초 메모리 단계입니다.
- Reflection: 수집된 궤적을 평가(evaluate)하고 수정하여 기억의 품질을 높이는 단계로, hallucination을 완화하고 논리적 오류를 제거하는 능동적 critic 역할을 합니다.
- Experience: 다수의 궤적에서 공통된 행동 패턴을 추상화(abstraction)하여 상황에 구애받지 않는 범용 규칙(universal rules)을 추출하는 최고 수준의 인지 단계입니다.
- Continual Learning: LLM 에이전트가 새로운 환경을 마주할 때 과거의 데이터를 재사용하고 학습하여 지식을 점진적으로 축적하고 고도화하는 최종 목표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반 에이전트 메모리 메커니즘의 파편화된 연구 현황을 통합하고, 기술적 진화 경로를 명확히 정립하기 위해 수행되었다. 기존 연구들은 공학적 시스템 엔지니어링 접근과 인지 과학적 모방 접근 사이에서 분리되어 발전해 왔으며, 이로 인해 메모리 기술의 핵심적인 진화 논리가 체계적으로 정리되지 못했다 [Figure 1]. 저자들은 이러한 Paradigmatic Fragmentation과 기술적 통합의 부재가 차세대 에이전트 아키텍처 발전을 저해하는 핵심 문제라고 지적한다. 이를 해결하기 위해 메모리 메커니즘을 동적 진화의 관점에서 체계화할 필요가 있다.
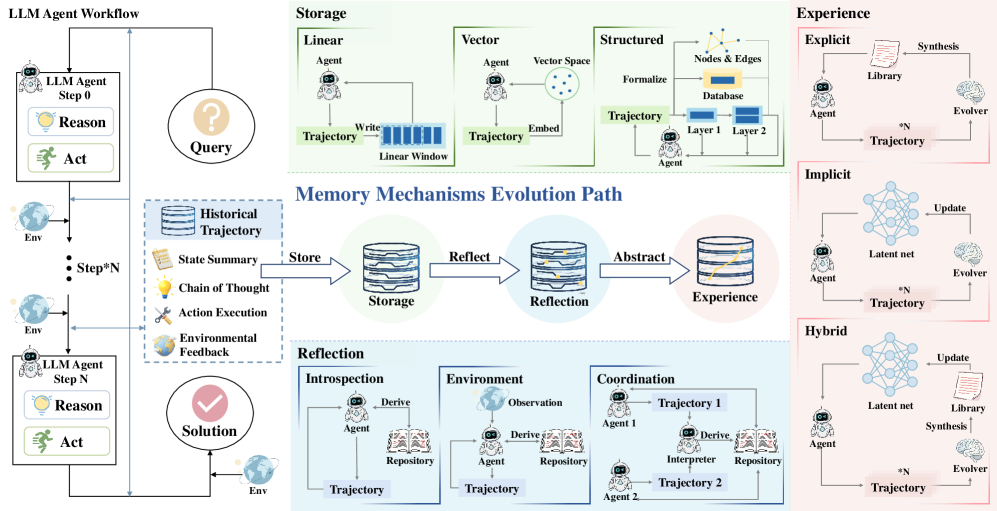
Figure 1 — LLM 에이전트 메모리 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 메모리 메커니즘의 진화 단계를 Storage, Reflection, Experience의 3단계로 정형화하는 새로운 프레임워크를 제안한다. Storage는 궤적의 충실한 기록을, Reflection은 피드백을 통한 궤적의 개선(denoising)을, Experience는 교차 궤적 추상화(cross-trajectory abstraction)를 통한 일반화된 지식 추출을 담당한다. 연구진은 메모리 진화의 핵심 동인(drivers)으로 long-range consistency, dynamic environments, 그리고 continual learning을 식별하였다 [Figure 2]. 특히 Experience 단계에서는 능동적 탐색(active exploration)과 추상화(abstraction)를 통해 에이전트가 상황적 제약을 뛰어넘어 자율적으로 진화할 수 있음을 입증한다 [Figure 3]. 기존 방식 대비 제안된 단계적 프레임워크는 개별적 작업에 국한된 episoidic memory를 넘어서, 미지의 환경에서도 활용 가능한 정책 prior를 생성함으로써 에이전트의 적응성과 자율성을 극대화할 수 있는 강력한 설계 원칙을 제시한다 [Table 1].
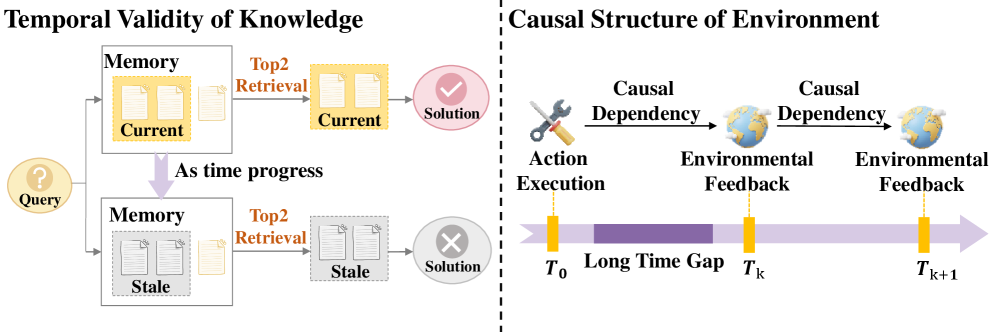
Figure 2 — 동적 환경에서의 진화 동인
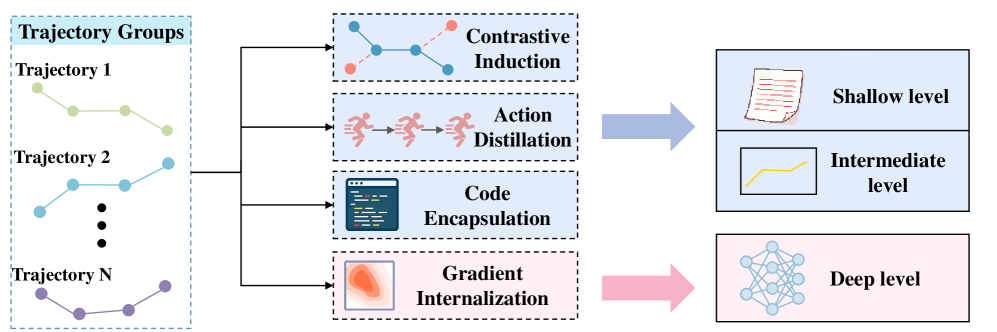
Figure 3 — 교차 궤적 추상화 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM 에이전트의 메모리 메커니즘을 단순한 데이터 저장 공간에서 경험 기반의 고도화된 지식 추상화 시스템으로 전환하는 진화적 로드맵을 제공한다. 이 연구는 학계에 파편화된 메모리 연구를 통합하는 이론적 기반을 마련하였으며, 산업계에는 차세대 자율 에이전트 설계에 필요한 구체적인 아키텍처 지침을 제공한다. 결과적으로 본 프레임워크는 LLM 에이전트가 실제 환경에서 지속적으로 자가 진화(self-evolution)하며 범용 인공지능(AGI)에 다가갈 수 있는 핵심적인 설계 원리를 제시한다는 점에서 그 의의가 크다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SkillHone: A Harness for Continual Agent Skill Evolution Through Persistent Decision History
- [논문리뷰] UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
- [논문리뷰] ResearchStudio-Idea: An Evidence-Grounded Research-Ideation Skill Suite from ML Conference Outcomes
- [논문리뷰] ASPIRE: Agentic /Skills Discovery for Robotics
- [논문리뷰] LectūraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
Review 의 다른글
- 이전글 [논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
- 현재글 : [논문리뷰] From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms
- 다음글 [논문리뷰] Gated QKAN-FWP: Scalable Quantum-inspired Sequence Learning
댓글