[논문리뷰] Revisiting DAgger in the Era of LLM-Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Changhao Li, Rushi Qiang, Jiawei Huang, Chenxiao Gao, Chao Zhang, Niao He, Bo Dai
1. Key Terms & Definitions (핵심 용어 및 정의)
- DAgger (Dataset Aggregation): 학생 정책(Student Policy)이 스스로 생성한 trajectory를 탐색하고, 각 상태에서 교사 정책(Teacher Policy)의 최적 행동을 라벨로 수집하여 학습 데이터셋을 점진적으로 확장하는 모방 학습 알고리즘입니다.
- Covariate Shift: 학습 데이터의 분포(교사 정책 유도 상태)와 실제 배포 환경에서의 데이터 분포(학생 정책 유도 상태) 간의 불일치로, 에이전트가 초기 실수를 복구하지 못하고 성능이 급격히 저하되는 현상입니다.
- On-Policy Distillation (OPD): 학생 정책이 생성한 trajectory에 대해 교사 모델의 로그 확률(Logit)을 직접적으로 모방하도록 유도하는 학습 기법으로, 탐색 과정에서 'cold-start' 실패 모드에 취약할 수 있습니다.
- Multi-turn LM-Agents: 프롬프트 입력 후 도구 사용, 환경 관찰, 코드 수정 등 여러 턴에 걸쳐 상호작용을 수행하며 장기적인 계획을 수립하는 언어 모델 에이전트 시스템입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 장기 상호작용을 수행하는 LLM 에이전트의 사후 학습(Post-training) 단계에서 발생하는 고질적인 분포 불일치 문제를 해결하고자 합니다. 기존의 SFT(Supervised Fine-Tuning)는 고품질의 교사 trajectory를 통해 정밀한 지도 학습을 제공하지만, 학생 모델이 실제 배포 환경에서 경험하는 상태를 반영하지 못해 Covariate Shift가 발생하며, 이로 인해 초기 단계의 작은 실수가 전체 trajectory의 실패로 이어집니다. 반면, RLVR(Reinforcement Learning with Verifiable Rewards)은 on-policy 탐색을 수행하나 보상이 매우 희소(Sparse)하여 학습 효율이 떨어집니다. 저자들은 학생의 탐색 경로를 그대로 활용하면서도 교사의 밀도 높은 지도 피드백을 결합할 수 있는 효율적인 학습 프레임워크가 필요함을 강조합니다 [Table 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 DAgger 원리를 멀티 턴 에이전트 환경에 맞게 재설계하여, 교사와 학생 정책을 혼합한 Stochastic Policy Mixture Rollout을 제안합니다. 이 방법은 교사-학생 간의 턴 단위 혹은 궤적 단위 혼합을 통해 에이전트가 배포 시 직면할 실제 상태 분포를 학습하게 함과 동시에, 매 단계마다 교사의 최적 행동 라벨을 수집하여 밀도 높은 피드백을 제공합니다 [Algorithm 1]. 특히, 학습이 진행됨에 따라 혼합 파라미터($\beta_i$)를 점진적으로 줄여 배포 시의 상태 분포에 자연스럽게 수렴하도록 설계되었습니다. 실험 결과, Qwen3-4B 모델에 적용 시 SWE-Bench Verified에서 기존 최강 모델 대비 +3.9%p 향상된 27.3%의 해결률을 기록하였으며, 8B 모델 또한 29.8%의 해결률을 달성하여 훨씬 큰 규모의 32B 모델 성능에 근접하는 우수한 효율성을 입증했습니다 [Table 3]. 또한, Reverse KL 지표를 통해 SFT 대비 에이전트의 정책 발산(Divergence)을 효과적으로 억제함을 확인하였습니다 [Figure 1].
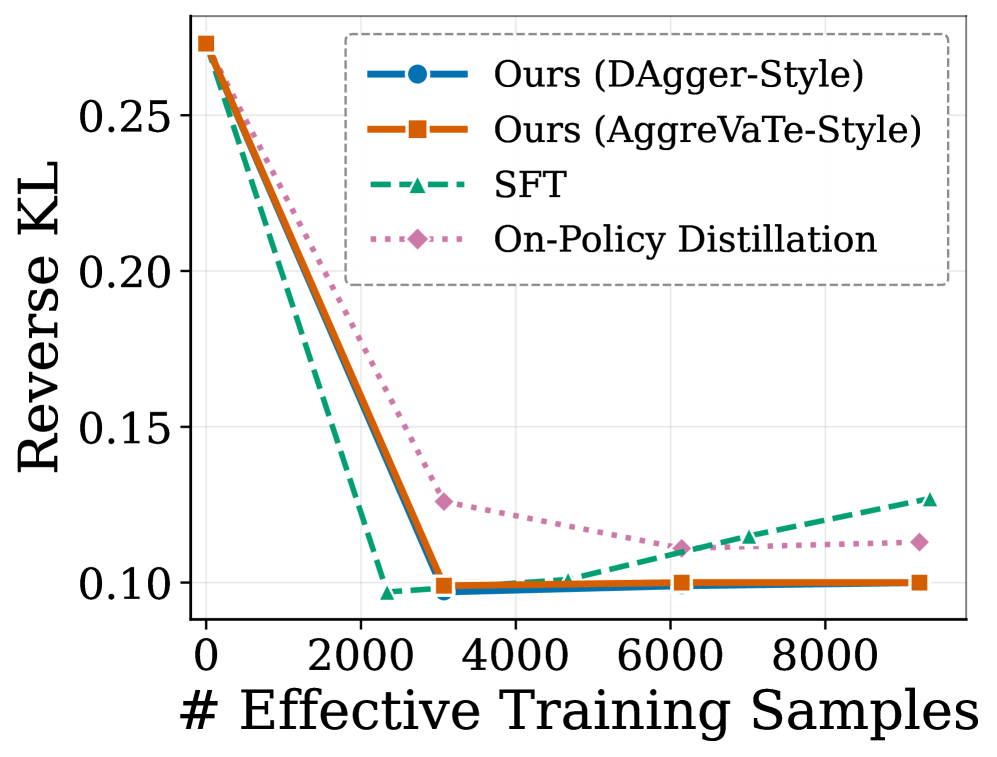
Figure 1 — 정책 발산(Reverse KL) 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고전적인 모방 학습 알고리즘인 DAgger를 현대의 LLM 에이전트 사후 학습에 효과적으로 재적용함으로써, 기존의 SFT 및 RL 기반 접근법들이 가진 한계를 극복하는 실용적인 해법을 제시합니다. 제안된 방식은 에이전트가 장기적인 환경 상호작용에서 발생하는 Covariate Shift에 강건하게 대응할 수 있도록 도우며, 학습 데이터 샘플 효율성을 대폭 개선합니다. 이 연구는 소프트웨어 공학 에이전트와 같은 복잡한 도구 활용 에이전트의 신뢰성과 성능 향상에 크게 기여할 것으로 기대되며, 다양한 에이전트 시스템의 보편적인 사후 학습 레시피로서 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SIEVE: Structure-Aware Data Selection for Imitation Learning with VLA Models
- [논문리뷰] RynnWorld-Teleop: An Action-Conditioned World Model for Digital Teleoperation
- [논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
- [논문리뷰] Translation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
- [논문리뷰] How Post-Training Shapes Biological Reasoning Models
Review 의 다른글
- 이전글 [논문리뷰] Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
- 현재글 : [논문리뷰] Revisiting DAgger in the Era of LLM-Agents
- 다음글 [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
댓글