[논문리뷰] AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haotian Zhao, Yuxin Zhang, Songlin Zhou, Stephen S.-T. Yau, Wenyu Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic RL: LLM 에이전트가 복잡한 환경에서 연속적인 추론과 행동을 수행하는 다중 턴(multi-turn) 강화학습 환경을 의미합니다.
- Credit Assignment: 에이전트의 전체 trajectory 중 최종 보상에 기여한 특정 행동(response)을 식별하여 그에 적절한 가중치를 부여하는 학습 기법입니다.
- Response-level Entropy: 토큰 단위가 아닌, 모델의 전체 응답(response) 단위로 측정된 불확실성 지표입니다.
- AEM (Adaptive Entropy Modulation): 학습 과정에서 모델의 응답 단위 엔트로피를 활용하여 정책의 엔트로피를 적응적으로 조절함으로써 Exploration과 Exploitation 간의 균형을 자동 최적화하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Agentic RL에서 발생하는 sparse, outcome-level reward 문제를 해결하기 위해 응답 수준에서의 정교한 Credit Assignment 프레임워크를 제안합니다. 기존의 많은 RL 방식은 다중 턴 환경에서 개별 행동의 중요도를 구분하지 못하거나, 추가적인 모델 훈련이나 복잡한 계산이 요구되는 한계가 있습니다. 저자들은 모델의 내재적 특성인 엔트로피가 각 의사결정 단계에서의 불확실성을 나타내는 자연스러운 신호가 될 수 있음에 주목합니다. 이를 통해 추가적인 지도 학습이나 설계 없이도 효율적인 Credit Assignment가 가능하도록 하는 방법론을 모색합니다. [Figure 1]
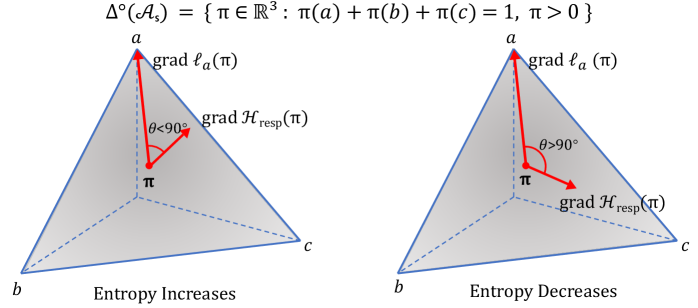
Figure 1 — 정책 심플렉스에서의 엔트로피 역학
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 응답 수준의 엔트로피 분석을 통해, 모델의 엔트로피 drift가 응답의 Advantage와 상대적 Surprisal에 의해 결정됨을 이론적으로 증명합니다 [Figure 1]. 제안하는 AEM은 이 이론을 기반으로, 학습 과정에서 보상 기반의 Advantage에 엔트로피 기반 Modulation Coefficient를 곱하여 응답 가중치를 적응적으로 조정합니다. 초기 단계에서는 엔트로피를 높여 다양한 탐색을 유도하고, 학습 후반부에는 고품질 정책으로의 자연스러운 수렴을 촉진합니다 [Figure 3]. 실험 결과, AEM은 ALFWorld, WebShop, SWE-bench-Verified 등 다양한 벤치마크에서 기존의 강력한 baseline(예: GRPO, DAPO, GSPO) 대비 일관된 성능 향상을 보입니다. 특히 SWE-bench-Verified와 같은 실무 지향적 과제에서 DeepSWE 모델에 통합되었을 때 기준 대비 +1.4%의 성능 개선을 달성했습니다 [Table 1, Table 2]. AEM 적용 시 연산 오버헤드는 전체 학습 시간의 약 1.1% 수준으로 매우 낮아 실용성이 높습니다 [Figure 4].
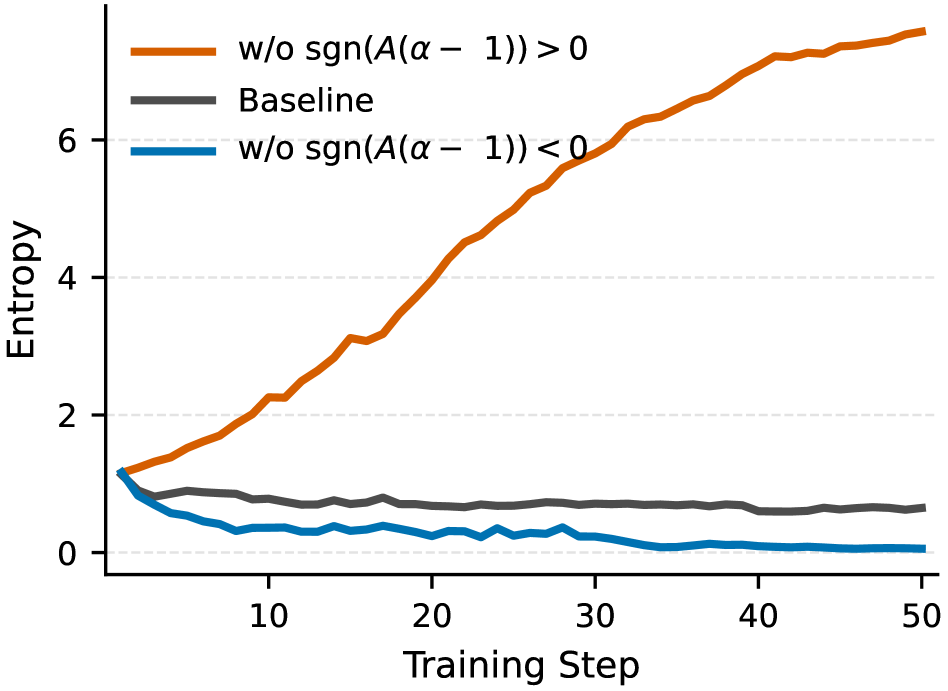
Figure 3 — 엔트로피 및 성공률 변화
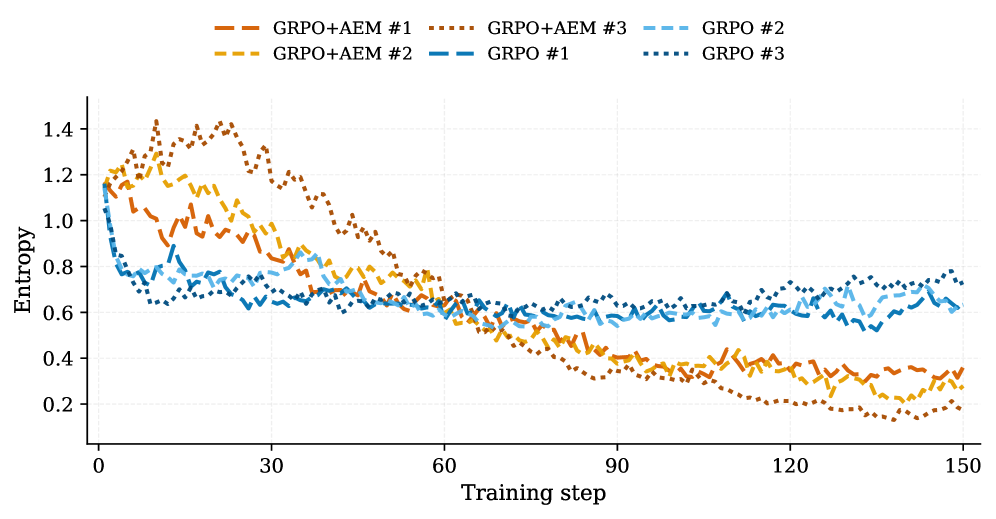
Figure 4 — 학습 시간 오버헤드 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AEM을 통해 추가적인 supervision 없이도 응답 수준의 엔트로피를 활용하여 Agentic RL의 탐색과 수렴 과정을 정교하게 조절할 수 있음을 입증했습니다. 이 연구는 모델의 내재적 확률 분포가 강화학습의 학습 역학(dynamics)을 제어하는 강력한 신호임을 규명했다는 점에서 학술적 가치가 큽니다. 산업적으로는 대규모 에이전트 시스템에서 복잡한 다중 턴 작업의 효율성을 높이는 경량화된 plug-in 프레임워크를 제공함으로써, 복잡한 환경에서의 자율 에이전트 구현을 가속화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] APPO: Agentic Procedural Policy Optimization
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] InfoPO: Information-Driven Policy Optimization for User-Centric Agents
- [논문리뷰] Agentic Entropy-Balanced Policy Optimization
- [논문리뷰] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Review 의 다른글
- 이전글 [논문리뷰] 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
- 현재글 : [논문리뷰] AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
- 다음글 [논문리뷰] Anisotropic Modality Align
댓글