[논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hanbo Cheng, Limin Lin, Ruo Zhang, Yicheng Pan, Jun Du
1. Key Terms & Definitions (핵심 용어 및 정의)
- CLVR (Closed-Loop Visual Reasoning): 시각-언어 논리 계획과 픽셀 단위의 diffusion 생성을 결합한 다단계 추론 프레임워크입니다.
- PPRL (Proxy Prompt Reinforcement Learning): 다단계 생성 과정에서 긴 컨텍스트 최적화 불안정성을 해결하기 위해, 다중 모달 기록을 명시적인 보상 신호로 변환하여 학습하는 강화학습 기법입니다.
- DSWM (Δ-Space Weight Merge): alignment 가중치를 사전에 훈련된 증류(distillation) 사전(prior)과 병합하여, 추가적인 재증류 없이 inference 비용을 획기적으로 줄이는 경량화 기법입니다.
- NFE (Number of Function Evaluations): diffusion 모델의 step 수를 의미하며, 본 논문에서는 효율적인 추론을 위해 4 NFE로 최적화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재 T2I(Text-to-Image) 모델이 의존하는 single-step generation 패러다임의 한계를 극복하고자 합니다. 기존의 단일 forward pass 기반 모델들은 복잡한 의미론적 요구사항을 처리할 때 속성 혼동이나 공간적 관계 오류 등 구조적 성능 저하를 겪으며, 모델 크기를 키워도 성능 향상이 정체되는 임계점에 직면해 있습니다. 최근의 CoT(Chain-of-Thought) 기반 접근법들은 계획 부족, 긴 컨텍스트 최적화 불안정성, 그리고 높은 inference latency 등의 기술적 난관으로 인해 실제 시스템 도입에 어려움을 겪고 있습니다 [Figure 2]. 따라서 본 연구는 이러한 문제들을 해결하기 위해 데이터 합성, 모델 정렬, 추론 및 배포 전반을 관통하는 통합 프레임워크를 제안합니다.
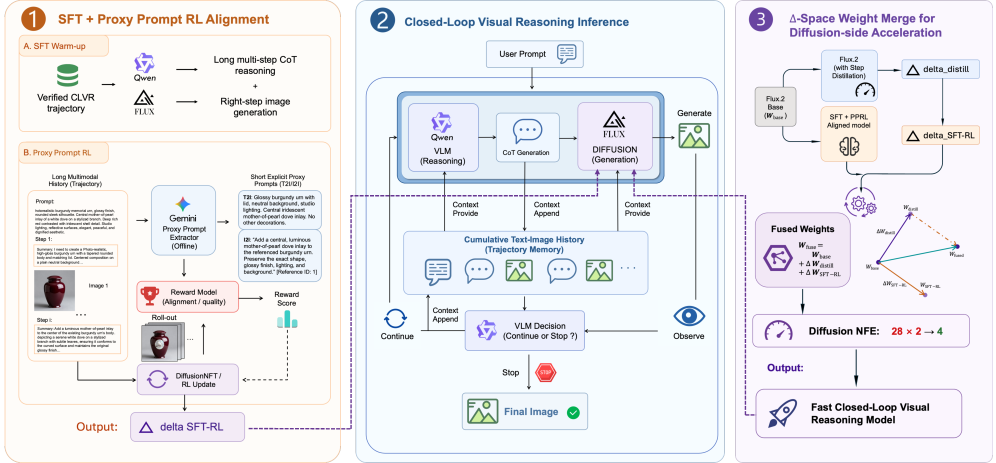
Figure 2 — CLVR 프레임워크의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 CLVR 프레임워크를 통해 추론과 생성의 closed-loop 루프를 완성합니다. 먼저 데이터 단계에서는 상태 제약 제어기와 단계별 시각적 검증을 통해 높은 신뢰도의 Reasoning Trajectory를 합성합니다 [Figure 3]. 이어지는 모델 정렬 단계에서는 PPRL을 도입하여, 긴 다중 모달 기록을 VLM을 통해 명시적인 'proxy prompt'로 변환하고 이를 reward 신호로 활용함으로써 최적화 안정성을 확보합니다. 마지막으로 배포 최적화를 위해 DSWM을 제안하여, 훈련된 정렬 가중치를 증류 사전과 기하학적으로 병합함으로써 per-step inference 비용을 4 NFE까지 감소시킵니다. 실험 결과, CLVR (9B) 모델은 GenEval 및 PRISM 등 주요 벤치마크에서 기존 오픈소스 베이스라인들을 크게 상회하였으며, 상용 모델인 GPT-4o의 성능에 근접하는 수준을 달성했습니다 [Table 1, Table 3]. 특히 복잡도가 높은 tier의 프롬프트에서 single-step 모델들이 급격한 성능 저하를 보일 때, CLVR은 우수한 pass rate를 유지하며 일반적인 test-time scaling 능력을 입증했습니다 [Figure 5].
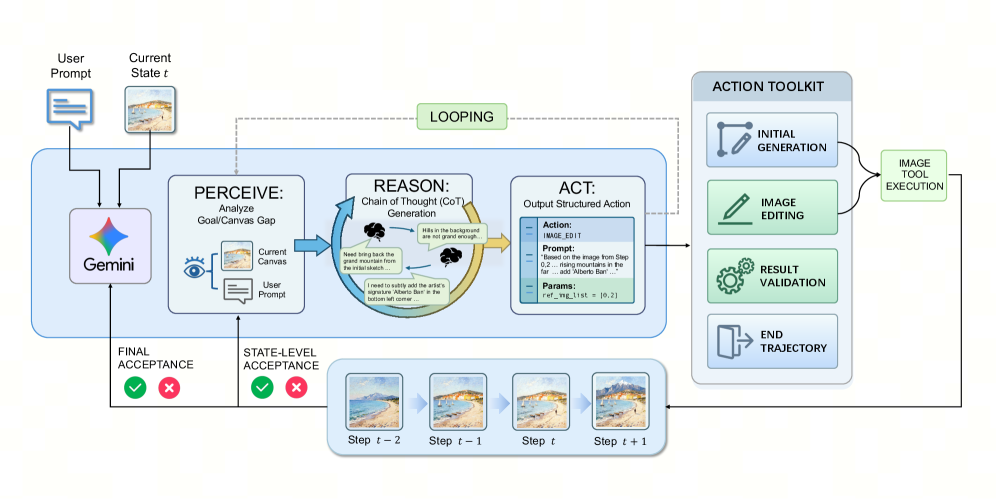
Figure 3 — 데이터 합성 파이프라인 아키텍처
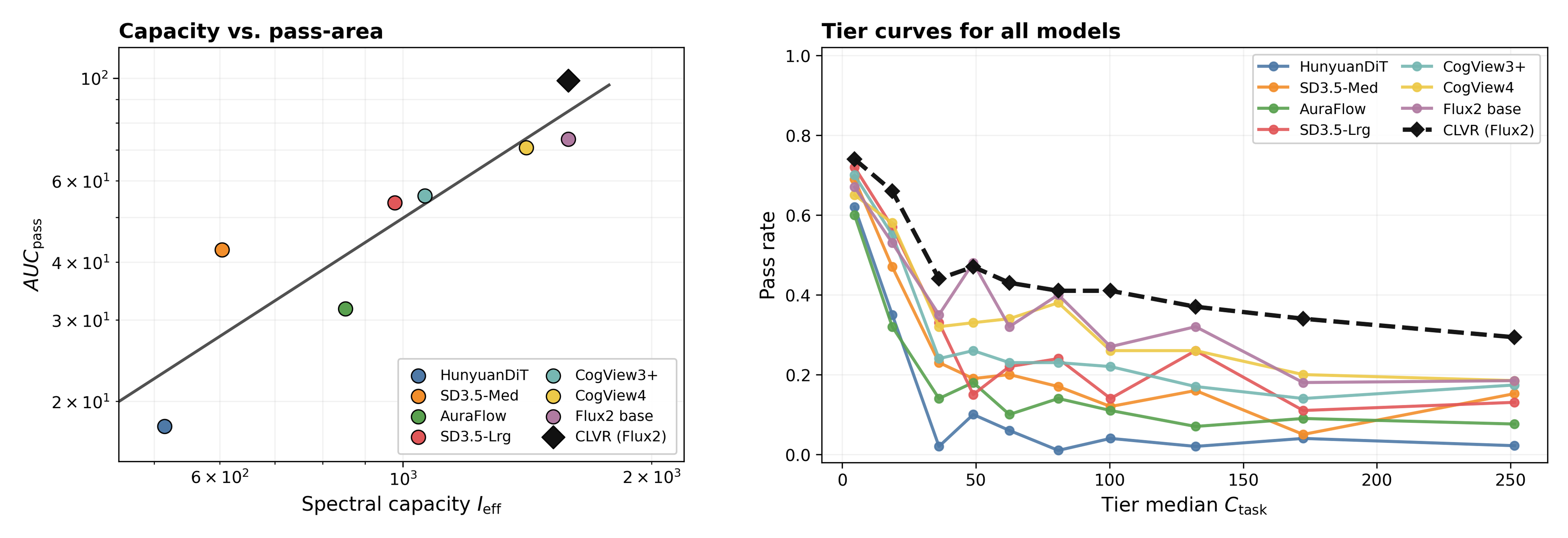
Figure 5 — 의미론적 복잡성 스케일링 프로브 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 데이터 합성부터 배포 가속화까지 시각 생성의 전 과정을 재구성하는 CLVR 시스템을 성공적으로 구축하였습니다. 이 연구는 복잡한 시각적 생성 작업에서 고비용의 단일 모델 스케일링을 대체할 수 있는 새로운 경로를 제시하며, 특히 DSWM 기법을 통해 다단계 추론 모델을 실제 운영 환경에서도 사용할 수 있는 효율적인 기술로 탈바꿈시켰습니다. 이러한 접근 방식은 향후 멀티모달 생성 분야에서 추론 능력을 극대화하고 실시간성까지 확보해야 하는 다양한 산업적 응용 분야에 핵심적인 방법론적 토대를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
- [논문리뷰] GARDO: Reinforcing Diffusion Models without Reward Hacking
- [논문리뷰] RealGen: Photorealistic Text-to-Image Generation via Detector-Guided Rewards
- [논문리뷰] Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
- [논문리뷰] Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference
Review 의 다른글
- 이전글 [논문리뷰] Topology-Preserving Neural Operator Learning via Hodge Decomposition
- 현재글 : [논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
- 다음글 [논문리뷰] VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
댓글