[논문리뷰] VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
링크: 논문 PDF로 바로 열기
저자: Kaixin Zhu, Yiwen Tang, Yifan Yang, Renrui Zhang, Bohan Zeng, Ziyu Guo, Ruichuan An, Zhou Liu, Qizhi Chen, Delin Qu, Jaehong Yoon, Wentao Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- VGGT-Edit: 본 논문에서 제안하는 텍스트 조건부 네이티브 3D 장면 편집 프레임워크로, 3D 기하학적 필드 내에서 직접 편집을 수행합니다.
- Residual Field Prediction: 장면 전체를 재학습하는 대신, 입력된 텍스트 지시에 따라 필요한 기하학적 변위(displacement)만을 국소적으로 예측하여 장면을 수정하는 방식입니다.
- Depth-Synchronized Text Injection: 텍스트 임베딩을 모델의 포즈 변조 단계와 정렬된 계층에 주입하여, 언어적 지시를 공간적 기하 정보와 직접적으로 결합하는 기술입니다.
- DeltaScene Dataset: 편집 전후의 3D 장면 쌍을 대규모로 포함하는 데이터셋으로, 3D 일치 필터링(3D agreement filtering)을 거쳐 고품질의 지상 진실(ground-truth)을 제공합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 3D 장면 편집 모델들이 직면한 다중 뷰 불일치 및 연산 효율성 문제를 해결하고자 합니다. 대부분의 기존 연구들은 2D 이미지를 개별적으로 편집한 후 이를 3D로 다시 쌓는 "2D-lifting" 방식을 채택하고 있어, 뷰 간의 기하학적 일관성이 깨지거나 텍스처가 흐릿해지는 한계가 존재합니다. 또한, 이러한 방식은 복잡한 3D 제어와 대화형 응용 프로그램을 지원하기에는 연산 속도가 지나치게 느리다는 고질적인 문제를 안고 있습니다 [Figure 1]. 저자들은 이러한 2D 의존적 편집 파이프라인의 공간적 모호성을 극복하고, 네이티브 3D 공간에서 직접적인 편집을 수행하는 효율적인 피드포워드(feed-forward) 프레임워크가 필수적이라고 판단하였습니다.
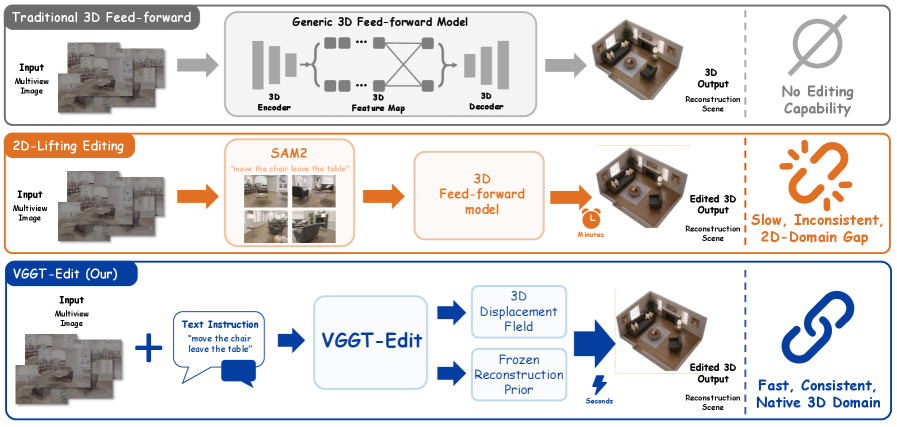
Figure 1 — 기존 3D 편집 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 강력한 사전 학습된 기하학적 사전(prior)을 고정한 채, 잔차 변환 헤드(residual transformation head)를 활용해 3D 공간 내 변위만을 학습하는 VGGT-Edit를 제안합니다 [Figure 4]. 이 모델은 깊이 동기화 텍스트 주입 모듈을 통해 언어적 의미를 3D 공간의 위치 정보와 정렬하며, 뷰 인식 중요도 가중치(view-aware importance weighting) 메커니즘을 적용하여 불확실한 관측치로 인한 노이즈를 효과적으로 억제합니다. 또한, 편집 마스크를 기반으로 기하학적 변위를 예측함으로써 배경의 구조적 무결성을 보존하고 국소적인 편집 성능을 극대화합니다 [Figure 2]. 실험 결과, VGGT-Edit는 기존 2D-lifting 베이스라인 대비 CLIP Score를 30.2로 향상시켰으며, C-FID를 122.4로 기록하여 최상의 시각적 품질과 일관성을 입증하였습니다 [Table 1]. 특히, per-scene 편집 시간을 약 5초로 단축하여 실시간 상호작용이 가능한 효율성을 실현하였습니다.
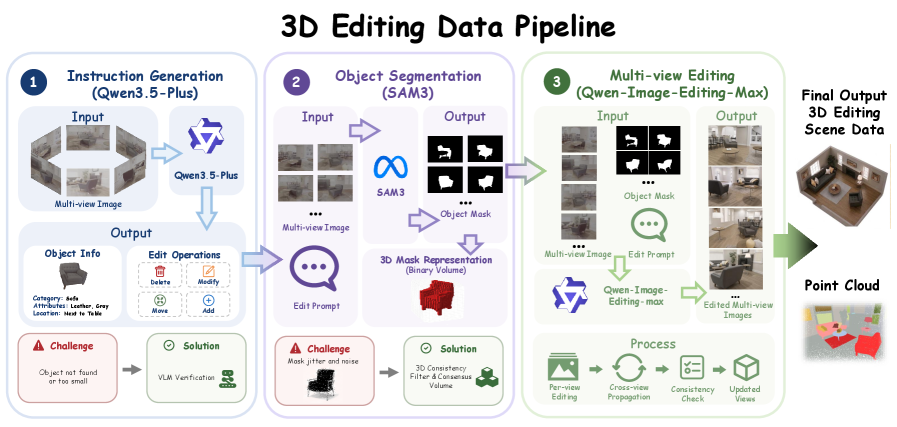
Figure 2 — DeltaScene 데이터 파이프라인
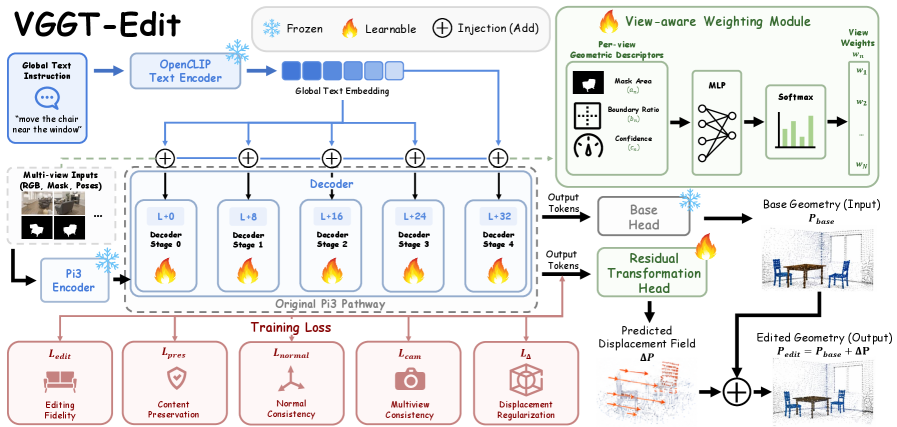
Figure 4 — VGGT-Edit 아키텍처 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 3D 장면 편집을 3D 잔차 필드 예측 문제로 재정의함으로써, 2D-lifting 기반 모델들이 가진 다중 뷰 불일치와 연산 지연 문제를 효과적으로 해결하였습니다. 제안된 VGGT-Edit는 고속 추론 성능과 높은 기하학적 정밀도를 동시에 달성하여, 로봇 조작 및 대화형 시뮬레이션과 같은 공간 컴퓨팅 분야에서 실질적인 응용 가치를 제시합니다. 나아가 구축된 DeltaScene Dataset은 향후 3D 편집 연구를 위한 대규모 학습 데이터를 제공함으로써 해당 분야의 발전을 견인할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Geometry-Guided Reinforcement Learning for Multi-view Consistent 3D Scene Editing
- [논문리뷰] Scenes as Objects, Not Primitives: Instance-Structured 3D Tokenization from Unposed Views
- [논문리뷰] 2Xplat: Two Experts Are Better Than One Generalist
- [논문리뷰] Solaris: Building a Multiplayer Video World Model in Minecraft
- [논문리뷰] GaussianBlender: Instant Stylization of 3D Gaussians with Disentangled Latent Spaces
Review 의 다른글
- 이전글 [논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
- 현재글 : [논문리뷰] VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
- 다음글 [논문리뷰] ViMU: Benchmarking Video Metaphorical Understanding
댓글