[논문리뷰] 2Xplat: Two Experts Are Better Than One Generalist
링크: 논문 PDF로 바로 열기
저자: Hwasik Jeong, Seungryong Lee, Gyeongjin Kang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- 3D Gaussian Splatting (3DGS) : 고품질 실시간 Novel View Synthesis를 위한 강력한 3D 표현 방법론입니다.
- Pose-free Feed-forward 3DGS : Uncalibrated Multi-view Images로부터 단일 Forward Pass를 통해 3DGS Representations를 직접 생성하며, 사전 Camera Pose Estimation이 필요 없는 기법을 지칭합니다.
- Monolithic Architecture : Camera Pose와 3DGS Representation 생성을 단일 네트워크 내에서 공동으로 추정하고 합성하는 통합된 아키텍처를 의미합니다.
- Two-Experts Architecture : Geometry Estimation (Camera Pose)과 Appearance Modeling (3DGS Generation)을 전용 모듈로 명확하게 분리하여 순차적으로 처리하는 아키텍처 디자인입니다.
- Evaluation-time Pose Alignment (EPA) : 평가 시점에 Camera Pose를 추가적으로 정렬하여 성능을 개선하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 3D Gaussian Splatting (3DGS) 파이프라인은 Scene당 수십 분에서 수 시간까지 소요되는 계산 집약적인 Iterative Optimization 절차에 의존하여 광범위한 적용에 한계가 있었습니다. 이러한 Bottleneck을 해결하기 위해 Multi-view Images로부터 Gaussian Parameters를 단일 Pass로 직접 예측하는 Feed-forward 3DGS 방법론들이 활발히 연구되었지만, 대부분의 접근 방식은 정확한 Camera Pose 정보가 이미 주어져 있다고 가정하여 Unconstrained Setting에서의 적용을 제한했습니다.
Uncalibrated Multi-view Images로부터 3DGS Representations를 직접 재구성하는 Pose-free Feed-forward 3DGS 방법론이 등장했지만, 기존 연구들은 주로 Monolithic Architecture 를 채택했습니다. 이러한 “All-in-one” 디자인은 Geometry Reasoning과 Appearance Modeling을 Shared Representation 내에서 얽히게 하여, 고품질 3DGS 생성에 최적화되지 않을 수 있다는 문제가 제기되었습니다. 저자들은 Monolithic Architecture 가 Geometry와 Appearance Modeling이라는 근본적으로 다른 목표들을 단일 네트워크 내에서 처리함으로써 성능 상의 내재적 한계를 가질 수 있다고 지적합니다. 또한, 강력한 Pose-conditioned Architectural Mechanism을 통합하기 어렵고, 고품질 3DGS Attributes 생성을 위한 충분한 Representational Capacity가 부족하다는 한계를 가집니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 Monolithic Architecture 의 한계를 극복하기 위해 2Xplat 이라는 Two-Experts Architecture 기반의 Pose-free Feed-forward 3DGS 프레임워크를 제안합니다. 이 방법론은 Geometry Estimation과 Gaussian Generation을 명시적으로 분리합니다
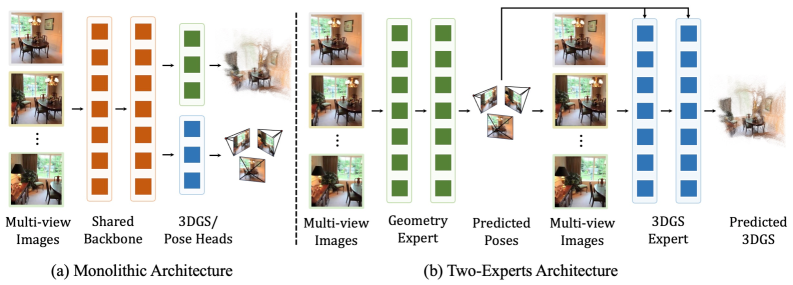
전용 Geometry Expert 가 먼저 Camera Pose를 예측하고, 이 예측된 Pose는 강력한 Appearance Expert 에게 명시적으로 전달되어 3D Gaussians를 합성합니다.
2Xplat 프레임워크는 미리 학습된 두 개의 Expert—Geometry Expert로는 Depth Anything 3 (DA3) , Appearance Expert로는 Multi-view Pyramid Transformer (MVP) —로 초기화된 후, 전체 시스템을 End-to-End로 Fine-tuning합니다. 이 Joint Training은 Appearance Expert가 노이즈가 포함된 Camera Pose Estimates에 강건해지도록 하며, 3DGS Generation의 Geometric Errors에 대한 민감도를 완화시킵니다. 전체 학습 목표 (Overall Training Objective) L은 Image Reconstruction Loss (L_render)와 Camera Pose Loss (L_cam)의 가중치 합으로 정의됩니다. L_render는 L2 Reconstruction Loss와 Perceptual Loss의 조합을 사용하며, L_cam은 Predicted Pose와 Ground-truth Pose 간의 Global Reference Frame 불확실성을 해결하기 위해 Relative Pose Loss를 채택합니다.
2Xplat 은 그 개념적 단순성에도 불구하고 매우 효과적임을 입증했습니다.
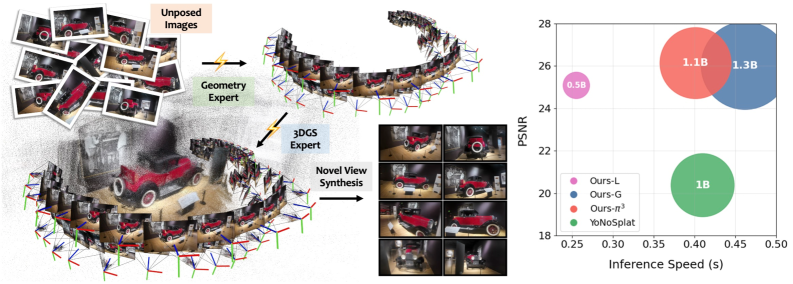
- Novel View Synthesis (NVS) 성능 : 2Xplat 은 5K 미만의 Training Iterations 내에 기존 Pose-free Feed-forward 3DGS 방법론들을 상당히 능가 하며, State-of-the-art Posed Methods 와 동등한 성능을 달성합니다.
DL3DV데이터셋의 Low-resolution Setting에서 6개의 Input Views를 사용할 때, 2Xplat 은 PSNR 26.007 을 달성하여 YoNoSplat 의 22.290 PSNR 대비 크게 향상된 성능을 보였습니다. Evaluation-time Pose Alignment (EPA) 적용 시에는 26.670 PSNR 로 YoNoSplat 의 24.531 PSNR 을 뛰어넘습니다 [cite: 1, Figure 1, Table 1].RE10K데이터셋에서도 26.161 PSNR (vs. YoNoSplat 19.723 PSNR)을 기록하며 강한 성능을 보입니다 [cite: 1, Table 3]. - Training Efficiency : 2Xplat 은 5K 미만의 Training Iterations 로 수렴하며, 이는 YoNoSplat 이 150K Iterations 와 더 많은 GPU를 요구하는 것에 비해 놀라운 Training Efficiency 를 보여줍니다.
- Cross-dataset Generalization :
DL3DV로 학습하고ScanNet++에서 Fine-tuning 없이 직접 테스트했을 때, 2Xplat 은 모든 평가 지표에서 일관되게 강력한 성능을 달성하여 다른 Scene Distribution에 대한 뛰어난 Generalization 능력을 입증했습니다 [cite: 1, Table 5, Figure 6]. - Pose Estimation : 2Xplat 은 주로 NVS 품질에 초점을 맞춤에도 불구하고, 정확한 Camera Pose Estimation도 부수적으로 가능하게 합니다.
RE10K에서 2K Iterations 만으로도 State-of-the-art 방법들과 유사한 AUC (Area Under the Curve) 성능을 달성했습니다 [cite: 1, Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구에서 저자들은 Pose Estimation과 Appearance Synthesis를 분리하는 Pose-free Feed-forward 3D Gaussian Splatting을 위한 2Xplat 이라는 Two-Experts Architecture 프레임워크를 제안합니다. 2Xplat 은 5K 미만의 Training Iterations 내에 뛰어난 Reconstruction Quality와 탁월한 Training Efficiency를 달성하면서, 기존 Pose-free 방법론들을 크게 능가하고 State-of-the-art Posed Approaches 와 동등한 성능을 보여줍니다.
이러한 결과는 Geometry Reasoning과 Appearance Modeling을 Shared Representation 내에서 얽히게 하는 것이 반드시 필요하거나 유익하다는 통념에 도전하며, 복잡한 3D Reconstruction Task에서 Modular Design Principles의 잠재적 이점을 강조합니다. 저자들은 이 연구가 3D Generation 및 그 이상의 분야에서 Expert-decomposed Architectures에 대한 추가적인 탐색을 촉진하기를 기대합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ZipSplat: Fewer Gaussians, Better Splats
- [논문리뷰] SUCCESS-GS: Survey of Compactness and Compression for Efficient Static and Dynamic Gaussian Splatting
- [논문리뷰] HyRF: Hybrid Radiance Fields for Memory-efficient and High-quality Novel View Synthesis
- [논문리뷰] Scenes as Objects, Not Primitives: Instance-Structured 3D Tokenization from Unposed Views
- [논문리뷰] Holistic Data Scheduler for LLM Pre-training via Multi-Objective Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] WorldCache: Content-Aware Caching for Accelerated Video World Models
- 현재글 : [논문리뷰] 2Xplat: Two Experts Are Better Than One Generalist
- 다음글 [논문리뷰] Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
댓글