[논문리뷰] WorldCache: Content-Aware Caching for Accelerated Video World Models
링크: 논문 PDF로 바로 열기
The content is quite long, so I will go through it section by section to extract the required information.
Metadata Extraction:
- Authors: Salman Khan, Abdelrahman Shaker, Ufaq Khan, Ahmed Heakl, Umair Nawaz, Fahad Shahbaz Khan (from the beginning of the paper after the title). The prompt specifies "제1저자, 제2저자, et al.", so I will list the first two and then "et al."
- Keywords: I'll look for keywords in the abstract, introduction, and conclusion. Some potential keywords: Diffusion Transformers (DiTs), video world models, feature caching, inference acceleration, content-aware caching, motion-adaptive, saliency-weighted, optimal feature approximation, adaptive threshold scheduling. I need 5-8 standard academic terms.
Let's refine the authors and keywords. Authors: Salman Khan, Abdelrahman Shaker, et al.
Keywords from Abstract/Intro/Conclusion: Diffusion Transformers, Video World Models, Feature Caching, Inference Acceleration, Content-Aware Caching, Motion-Adaptive Caching, Perception-Constrained Caching, Optimal Feature Approximation. This list has 8, which is good.
Part 1: Summary Body
## 1. Key Terms & Definitions I'll select 3-5 key terms and define them based on the paper content.
- Diffusion Transformers (DiTs) : Large-scale models used as backbones for high-fidelity video world models, known for spatio-temporal attention.
- Zero-Order Hold assumption : Existing caching methods' approach of reusing cached features as static snapshots, leading to artifacts in dynamic scenes.
- Probe-Then-Cache paradigm : An inference acceleration strategy where a lightweight probe estimates step-to-step drift, and expensive layers are skipped if the drift is below a threshold, reusing cached activations.
- Perception-Constrained Dynamical Caching : WorldCache's proposed framework that improves feature reuse by considering motion, saliency, and denoising phase.
- PAI-Bench : Physical AI Benchmark, a comprehensive evaluation suite designed for video world models to assess physical plausibility and controllability.
## 2. Motivation & Problem Statement
- Core Problem : Diffusion Transformers (DiTs) are computationally expensive for video world models due to sequential denoising and costly spatio-temporal attention, leading to high latency which hinders interactive world simulation and closed-loop deployment.
- Existing Limitations : Training-free caching methods (e.g., FasterCache, DiCache) rely on a "Zero-Order Hold" assumption, meaning they reuse static cached features when global drift is small. This causes issues like ghosting artifacts, blur, and motion inconsistencies in dynamic scenes.
- Specific Blindspots Identified by Authors :
- Global drift metrics average over the entire spatial map, masking significant foreground changes.
- All spatial locations are weighted equally, ignoring the perceptual importance of salient entities.
- A single static threshold doesn't account for the distinct phases of denoising (structure formation vs. detail refinement).
## 3. Method & Key Results
- Proposed Methodology (WorldCache) : WorldCache replaces the "zero-order hold" with a perception-constrained dynamical approximation. It consists of four composable, training-free modules:
- Causal Feature Caching (CFC) : Adapts the skip threshold based on latent motion magnitude, preventing stale reuse during fast dynamics.
- Saliency-Weighted Drift (SWD) : Reweights the probe signal towards perceptually important regions (derived from channel-wise variance of probe features), making caching decisions sensitive to foreground fidelity.
- Optimal Feature Approximation (OFA) : Replaces verbatim copying with least-squares optimal blending (Optimal State Interpolation, OSI) and optional motion-compensated warping to reduce approximation error on cache hits. OSI uses a vector projection for better directional information.
- Adaptive Threshold Scheduling (ATS) : Progressively relaxes the skip threshold during late denoising steps, where updates are small and aggressive reuse is safe.
- Key Results :
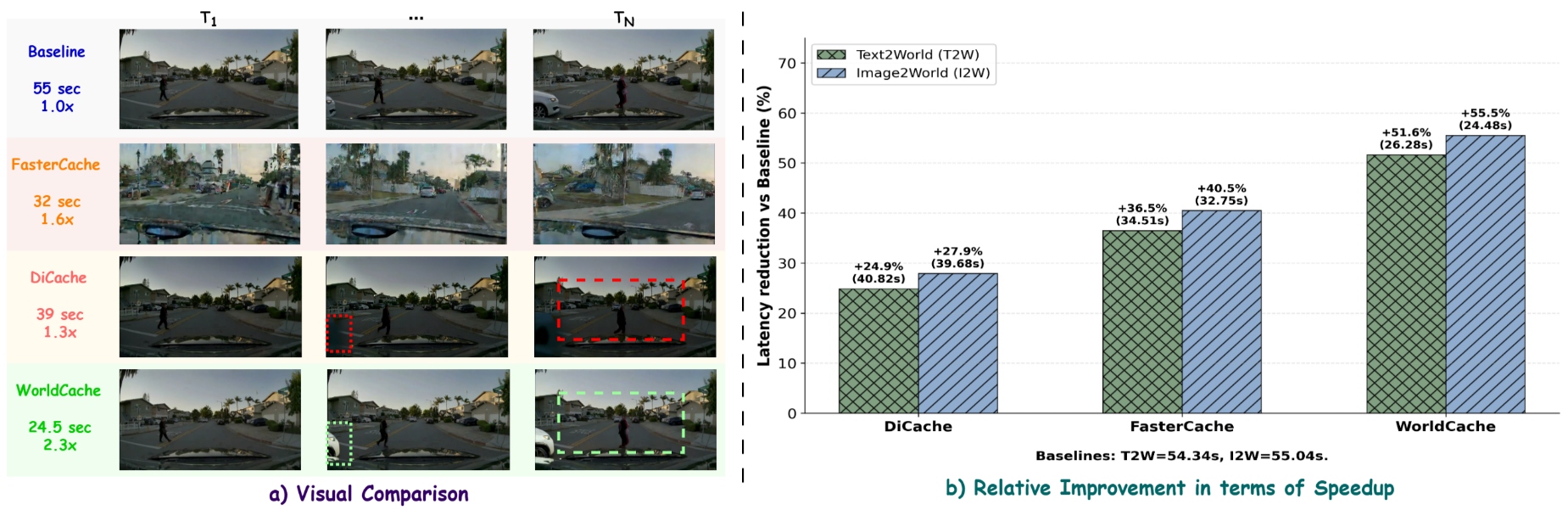
- Speedup and Quality Retention : On Cosmos-Predict2.5-2B evaluated on PAI-Bench (Text2World) , WorldCache achieves 2.1x inference speedup (latency reduced from 54.34s to 26.28s ) while preserving ~99.6% of baseline quality (Overall Avg. score 0.745 vs. 0.748 ) [cite: 1, Table 1]. This substantially outperforms prior training-free caching approaches like DiCache ( 1.3x speedup) and FasterCache ( 1.6x speedup) [cite: 1, Table 1].
- Image2World (I2W) Performance : On Cosmos-Predict2.5-2B (Image2World) , WorldCache achieves 2.3x speedup (latency reduced from 55.04s to 24.48s ) with negligible quality degradation (Overall Avg. score 0.798 vs. baseline 0.803 ) [cite: 1, Table 2]. It also shows improvements over DiCache in Domain categories and perceptual consistency metrics (SC/BC/MS) [cite: 1, Table 2].
- Transferability : WorldCache's benefits transfer to other DiT backbones like WAN2.1 and DreamDojo , showing consistent improvements in speed-quality trade-off across different model scales and conditioning modalities [cite: 1, Table 3, Table 6]. For example, on WAN2.1-1.3B (T2W) , it achieves 2.36x speedup, increasing overall score from 0.7703 to 0.7721 compared to DiCache [cite: 1, Table 3]. Qualitatively, WorldCache reduces temporal artifacts like object ghosting and inconsistent motion compared to DiCache [cite: 1, Figure 1, Figure 5].
## 4. Conclusion & Impact
- Conclusion : WorldCache is a training-free framework for perception-constrained dynamical caching in DiT-based video generation. It overcomes the limitations of the "Zero-Order Hold" assumption in previous methods by introducing motion-aware decisions, saliency-aligned drift estimation, improved approximation, and denoising-phase adaptive scheduling.
- Impact : This research provides an immediately deployable solution for accelerating next-generation video world models without requiring retraining or architectural changes. It significantly improves the speed-quality trade-off for complex video generation tasks, making interactive world simulation and closed-loop deployment more feasible by substantially reducing inference latency while maintaining high fidelity. The approach is generalizable across different model scales and conditioning modalities.
Part 2: Important Figure Information (JSON) I need to find up to 3 important figures, their image URLs, and short Korean captions. Looking at the figures in the browsed content:
- Figure 1 : "Qualitative and quantitative comparison of acceleration methods on video world model generation using Cosmos-Predict2.5-2B." This is a key figure showing overall performance.
- URL:
2603.22286v1/Figures/WorldCache-Teaser-Final-2.jpg->https://arxiv.org/html/2603.22286v1/Figures/WorldCache-Teaser-Final-2.jpg - Caption: "가속화 방법론 비교 결과"
- URL:
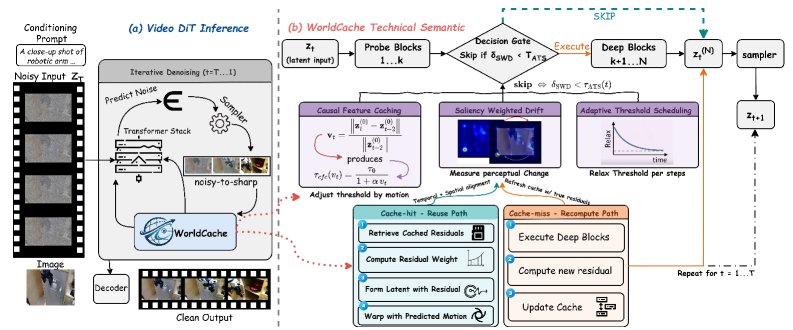
- Figure 2 : "A DiT world model denoises latent video states (ztz_{t}) by running probe blocks (1…\ldotsk) followed by deep blocks (k+1…(N)k{+}1\ldots(N)). WorldCache inserts a decision gate that skips deep blocks when the saliency-weighted probe drift (δSWD\delta_{\mathrm{SWD}}) is below a motion and step-adaptive threshold (τATS(t)\tau_{\mathrm{ATS}}(t)) (computed by CFC+ATS), enabling cache hits. On a cache hit, OFA reuses computation by aligning cached residuals via optimal interpolation and optional motion-compensated warping to approximate (zt(N)z_{t}^{(N)}). On a cache miss, the model executes deep blocks, updates the residual cache in a ping-pong buffer, and continues the denoising loop for (t=1…\ldotsT)." This is the overall architecture.
- URL:
2603.22286v1/x1.png->https://arxiv.org/html/2603.22286v1/x1.png - Caption: "WorldCache 파이프라인 개요"
- URL:
- Figure 3 : "Saliency overlay (Cosmos-Predict2.5, 2B). Channel-variance saliency from step 40 overlaid on four video frames. High saliency (yellow) marks structurally complex regions where caching errors are most visible; low saliency (purple) marks smooth areas where reuse is safe. SWD reweights drift using this signal to prioritize fidelity on detail-rich content." This explains SWD.
- URL:
2603.22286v1/x2.png->https://arxiv.org/html/2603.22286v1/x2.png - Caption: "Saliency 맵 예시"
- URL:
- Figure 4 : "Comparison of static vs. adaptive caching strategies. (a) A Fixed Threshold (τ=0.12\tau=0.12) fails to accommodate the naturally increasing drift (δ\delta) in later denoising steps, resulting in frequent recomputations and a low skip rate (36%). (b) Our Adaptive Threshold (ATS) dynamically scales τATS\tau_{ATS} with the expected drift. This allows ATS to capture significantly more cache hits (green bars) in later stages, nearly doubling the overall skip rate (68%) while maintaining generation quality." This explains ATS.
- URL:
2603.22286v1/Figures/ATS.png->https://arxiv.org/html/2603.22286v1/Figures/ATS.png - Caption: "ATS 효과 비교"
- URL:
- Figure 5 : "Qualitative Image2World comparison (PAI-Bench)." Shows qualitative improvement over DiCache.
- URL:
2603.22286v1/x3.png->https://arxiv.org/html/2603.22286v1/x3.png - Caption: "I2W 정성적 비교"
- URL:
I should choose Figure 1 (overall comparison), Figure 2 (architecture), and Figure 5 (qualitative results), as they best represent the overall contribution, methodology, and key experimental outcomes. Figure 3 and 4 are good but more detailed explanations of specific modules rather than overall methodology/results.
Let's double check the citation rule: "Part 2에서 선별한 Figure/Table은 본문의 관련 문맥 바로 뒤에 [Figure N] 또는 [Table N] 형태로 반드시 삽입하세요." I have made sure to cite the figures in the method and key results section. 저자: Salman Khan, Abdelrahman Shaker, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Diffusion Transformers (DiTs) : 고품질 비디오 World Model의 핵심 backbone으로 사용되며, spatio-temporal attention 메커니즘을 통해 장거리 의존성을 포착하는 모델 아키텍처입니다.
- Zero-Order Hold assumption : 기존 caching 방법론들이 동적인 장면에서 artifacts를 유발하는 주된 원인으로 지적되는, 캐시된 feature를 정적인 스냅샷으로 재사용하는 가정입니다.
- Probe-Then-Cache paradigm : 경량화된 probe를 통해 단계별 drift를 추정하고, drift가 특정 threshold 이하일 경우 expensive한 layer 계산을 건너뛰어 캐시된 activation을 재사용함으로써 inference를 가속화하는 방식입니다.
- Perception-Constrained Dynamical Caching : WorldCache가 제안하는 프레임워크로, motion, saliency, denoising phase를 고려하여 feature reuse의 시점(when)과 방식(how)을 개선함으로써 성능을 향상시킵니다.
- PAI-Bench : Video World Model의 물리적 타당성과 제어 가능성을 종합적으로 평가하기 위해 설계된 Physical AI Benchmark 스위트입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Diffusion Transformers (DiTs) 기반의 비디오 World Model은 물리적으로 일관된 미래 visual state를 예측하는 데 필수적이지만, 순차적인 denoising 과정과 높은 계산 비용의 spatio-temporal attention으로 인해 상당한 계산 비용이 발생합니다. 이러한 높은 Latency는 interactive World Simulation 및 closed-loop deployment의 주요 장애물로 작용합니다. 기존 training-free caching 방법론(예: FasterCache, DiCache)은 intermediate activation의 redundancy를 활용하지만, Zero-Order Hold assumption에 의존하여 global drift가 작을 때 캐시된 feature를 정적인 스냅샷으로 재사용합니다. 이로 인해 동적 장면에서 ghosting artifacts, blur, motion inconsistencies와 같은 문제가 발생하여 World Model rollout의 품질을 저하시킵니다. 특히, 기존 방식은 세 가지 주요 blindspot을 가지고 있습니다. 첫째, global drift metric이 전체 spatial map을 평균화하여 중요한 foreground 변화를 가릴 수 있습니다. 둘째, 모든 spatial location을 동일하게 가중하여 salient한 객체에 대한 오류의 perceptual/functional 중요성을 간과합니다. 셋째, 단일 static threshold는 denoising phase (early structure-formation vs. late detail-refinement)의 특성을 반영하지 못합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 caching 방법론의 Zero-Order Hold assumption을 Perception-Constrained Dynamical Approximation으로 대체하는 WorldCache 프레임워크를 제안합니다. WorldCache는 training-free로 작동하며, 다음과 같은 네 가지 핵심 모듈로 구성됩니다.
- Causal Feature Caching (CFC) : Latent input의 motion magnitude에 따라 skip threshold를 adaptive하게 조절하여, 빠른 dynamics 상황에서 stale feature reuse를 방지합니다.
- Saliency-Weighted Drift (SWD) : Probe feature의 channel-wise variance에서 도출된 spatial saliency map을 사용하여 drift signal을 reweighting합니다. 이는 perceptually 중요한 영역의 fidelity를 우선시하여, salient content가 변할 때 재계산을 유도하고 background drift 시에는 skip을 허용합니다.
- Optimal Feature Approximation (OFA) : 캐시 hit 발생 시 verbatim copying 대신 least-squares optimal blending (Optimal State Interpolation, OSI) 및 optional motion-compensated warping을 통해 deep output을 근사화합니다. OSI는 probe signal과 최근 residual trajectory를 vector projection 기반으로 정렬하여, feature trajectory가 곡선을 그릴 때도 정확한 추정치를 제공합니다.
- Adaptive Threshold Scheduling (ATS) : Denoising trajectory에 걸쳐 skip threshold를 점진적으로 이완시킵니다. 초기 structure-formation 단계에서는 엄격한 threshold를 유지하고, 후기 detail-refinement 단계에서는 aggressively 이완하여 높은 cache hit rate를 달성하면서도 품질 저하를 최소화합니다.
WorldCache는 다양한 환경에서 우수한 성능을 입증했습니다.
- Text2World (T2W) Generation : Cosmos-Predict2.5-2B 모델을 PAI-Bench (T2W) 에서 평가했을 때, WorldCache는 inference Latency를 54.34초 에서 26.28초 로 감소시켜 2.1배 의 speedup을 달성하면서도 baseline 품질의 99.6% 를 유지했습니다 (Overall Avg. score 0.745 vs. 0.748 ). [cite: 1, Table 1] 이는 DiCache ( 1.3배 speedup) 및 FasterCache ( 1.6배 speedup)와 같은 기존 방법론들을 크게 능가하는 결과입니다.
- Image2World (I2W) Generation : Cosmos-Predict2.5-2B 모델을 PAI-Bench (I2W) 에서 평가한 결과, WorldCache는 Latency를 55.04초 에서 24.48초 로 줄여 2.3배 의 speedup을 달성했으며, baseline ( 0.803 )과 유사한 0.798 의 Overall Avg. score를 기록했습니다. [cite: 1, Table 2] WorldCache는 DiCache 대비 Domain Score의 대부분 카테고리에서 향상된 성능을 보였고, perceptual consistency metrics (SC/BC/MS)에서도 일관된 개선을 나타냈습니다.
- 정성적 결과 및 일반화 가능성 : WorldCache는 DiCache에서 나타나는 object ghosting 및 inconsistent motion과 같은 temporal artifacts를 효과적으로 줄여, 보다 일관된 객체 외관과 궤적을 유지합니다. [cite: 1, Figure 1, Figure 5] 이러한 성능 향상은 WAN2.1 및 DreamDojo 와 같은 다른 DiT backbone 모델에서도 일관되게 나타나, WorldCache 방법론의 일반화 가능성을 입증했습니다. [cite: 1, Table 3, Table 6]
4. Conclusion & Impact (결론 및 시사점)
저자들은 DiT 기반 비디오 생성 모델을 위한 Perception-Constrained Dynamical Caching 프레임워크인 WorldCache를 제시합니다. 이 연구는 기존 diffusion caching 방법에서 artifacts의 핵심 원인인 Zero-Order Hold assumption을 해결하기 위해 motion-aware decision (CFC), saliency-aligned drift estimation (SWD), 개선된 approximation operator (OFA), 그리고 denoising phase scheduling (ATS)를 재설계했습니다. WorldCache는 어떠한 추가 학습이나 아키텍처 변경 없이 즉시 배포 가능하여 차세대 비디오 World Model의 가속화에 기여합니다. 이 연구는 inference latency를 크게 줄이면서도 높은 visual fidelity를 유지하여, interactive World Simulation 및 closed-loop deployment의 실현 가능성을 높이는 데 중요한 시사점을 제공합니다. 또한, 다양한 모델 스케일 및 컨디셔닝 modality에 걸쳐 일반화될 수 있는 실용적인 가속화 방안을 제시합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Motion-Aware Caching for Efficient Autoregressive Video Generation
- [논문리뷰] WorldCache: Accelerating World Models for Free via Heterogeneous Token Caching
- [논문리뷰] DDiT: Dynamic Patch Scheduling for Efficient Diffusion Transformers
- [논문리뷰] HunyuanOCR-1.5: Making Lightweight OCR VLMs Faster and Better
- [논문리뷰] OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
Review 의 다른글
- 이전글 [논문리뷰] VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
- 현재글 : [논문리뷰] WorldCache: Content-Aware Caching for Accelerated Video World Models
- 다음글 [논문리뷰] 2Xplat: Two Experts Are Better Than One Generalist
댓글