[논문리뷰] Motion-Aware Caching for Efficient Autoregressive Video Generation
링크: 논문 PDF로 바로 열기
저자: Shiwei Liu, Xuzhe Zheng, Songwei Liu, Yuexiao Ma, Jing Xu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Autoregressive Video Generation: 영상을 연속적인 chunk 단위로 나누어 LLM의 next-token 예측 패러다임을 비디오 생성에 적용한 프레임워크입니다.
- KV Cache: 기존 계산 결과를 저장하여 중복 계산을 생략하고 효율적인 추론을 가능하게 하는 메커니즘입니다.
- Residual: diffusion 모델의 velocity field와 입력 latent 사이의 차이값으로, feature caching에서 계산 효율성을 위해 재사용되는 핵심 요소입니다.
- Motion-Aware Token Importance: 프레임 간 차이(intra-chunk frame difference)를 사용하여 비디오의 어느 영역(token)이 더 많은 계산이 필요한지 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 autoregressive 비디오 생성 모델에서 반복적인 denoising 프로세스로 인해 발생하는 과도한 계산 비용 문제를 해결하기 위해 MotionCache를 제안합니다. 기존의 캐싱 방식(예: TeaCache, FlowCache)은 전체 chunk 또는 timestep을 단위로 하여 skipping 여부를 결정하는 coarse-grained 방식을 취하고 있습니다 [Figure 4]. 이러한 방식은 비디오 내의 세밀한 픽셀 단위(token-level)의 움직임을 반영하지 못해, 정적인 배경 영역과 동적인 객체 영역을 구분하지 못하고 계산 자원을 비효율적으로 사용한다는 한계가 있습니다. 따라서 본 연구는 fine-grained 수준에서 token별 움직임에 따라 유연하게 계산 자원을 할당할 수 있는 새로운 메커니즘이 필요하다고 정의합니다.
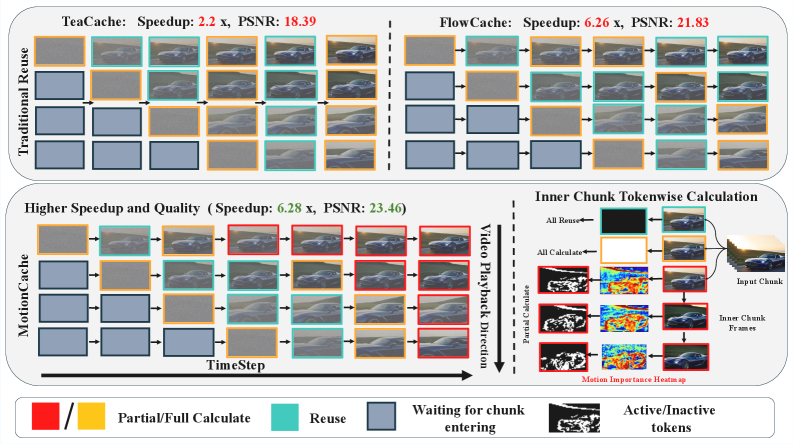
Figure 4 — 기존 캐싱과 MotionCache 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 캐싱 오류가 residual의 불안정성과 직결된다는 이론적 분석을 바탕으로, 프레임 간 차이를 residual 불안정성의 상한선으로 규정하는 MotionCache를 제안합니다 [Figure 4]. 제안 방법론은 초기에는 구조적 안정성을 확보하기 위해 전체 chunk 단위의 계산을 수행하고, 이후에는 토큰 단위로 움직임 중요도(importance weight)를 계산하여 임계값을 초과하는 토큰만 재계산하는 Dual-Stage Coarse-to-Fine 스케줄을 적용합니다 [Figure 6]. SkyReels-V2 모델에서 MotionCache는 기존 FlowCache 대비 동등하거나 더 우수한 품질(VBench score 82.84%)을 유지하면서도 **6.28×**의 높은 속도 향상을 달성했습니다 [Table 1]. 또한 MAGI-1 모델에서는 **2.07×**의 속도 향상을 기록하면서도 시각적 품질 저하를 최소화하여(VBench score 74.59%), 기존 coarse-grained 방식이 겪던 심각한 품질 저하(68.81%~73.42%)를 극복했습니다 [Table 1].
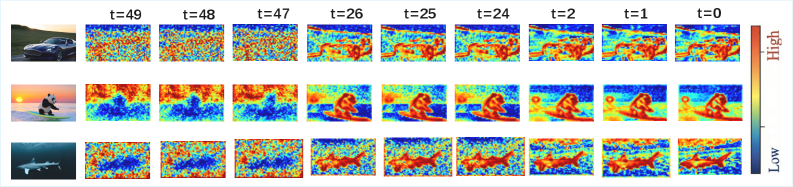
Figure 6 — denoising 과정 중 중요도 맵 변화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 비디오 내 움직임의 공간적/시간적 특성을 활용한 fine-grained caching 전략이 autoregressive 비디오 생성 모델의 효율성을 극대화할 수 있음을 입증했습니다. 이론적 분석과 실증적 결과는 coarse-grained 방식에서 탈피하여 토큰 단위의 적응형 자원 할당이 필수적임을 보여줍니다. 이러한 성과는 고해상도 비디오 생성 모델의 실시간 배포를 가능하게 하는 실질적인 기술적 진보로 평가됩니다. 특히, 본 연구에서 확립한 motion-aware proxy는 향후 효율적인 generative 모델 설계의 핵심 가이드라인으로 활용될 것으로 기대됩니다.

Figure 7 — SkyReels-V2에서의 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers
- [논문리뷰] WorldCache: Content-Aware Caching for Accelerated Video World Models
- [논문리뷰] OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
- [논문리뷰] DiffusionBench: On Holistic Evaluation of Diffusion Transformers
Review 의 다른글
- 이전글 [논문리뷰] MolmoAct2: Action Reasoning Models for Real-world Deployment
- 현재글 : [논문리뷰] Motion-Aware Caching for Efficient Autoregressive Video Generation
- 다음글 [논문리뷰] OceanPile: A Large-Scale Multimodal Ocean Corpus for Foundation Models
댓글