[논문리뷰] Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
링크: 논문 PDF로 바로 열기
The paper is about AutoGaze, a lightweight module for efficient and scalable video understanding.
It addresses the problem of MLLMs struggling with long, high-resolution videos due to spatiotemporal redundancy.
AutoGaze removes redundant patches before processing by a ViT or MLLM.
It uses next-token prediction and reinforcement learning to autoregressively select multi-scale patches for video reconstruction within an error threshold.
The paper also introduces HLVid, a new high-resolution, long-form video QA benchmark.
Let's extract the required information:
Authors: Baifeng Shi, Stephanie Fu, Long Lian, Hanrong Ye, David Eigen, Aaron Reite, Boyi Li, Jan Kautz, Song Han, David M. Chan, Pavlo Molchanov, Trevor Darrell, Hongxu Yin. (I will use "Baifeng Shi, Stephanie Fu, et al." as per the prompt instructions, considering the first two are marked as equal contribution).
Keywords: I will select 5-8 from the abstract and introduction: Video Understanding, Multi-modal Large Language Models (MLLMs), Vision Transformers (ViTs), Autoregressive Gazing, Token Reduction, Multi-scale Patches, High-Resolution Video, Long-Form Video.
Key Terms & Definitions:
- AutoGaze : A lightweight module (3M-parameter) that autoregressively selects a minimal set of multi-scale patches from a video to remove spatiotemporal redundancy before processing by a ViT or MLLM.
- MLLMs (Multi-modal Large Language Models) : 텍스트와 비전 데이터를 모두 처리하여 일반 목적의 비디오 이해 (video QA, captioning 등)를 수행하는 모델.
- ViT (Vision Transformer) : 이미지나 비디오의 visual tokens를 처리하는 트랜스포머 기반 모델.
- HLVid : AutoGaze의 확장성을 stress-test하기 위해 제안된, 5분 길이의 4K-resolution 비디오를 포함하는 최초의 high-resolution, long-form video QA 벤치마크.
- Multi-scale Patches : 다양한 해상도(scale)의 패치들을 선택하여, 디테일이 필요한 영역에는 finer scale을, 정적인 넓은 영역에는 coarser scale을 적용하는 방식.
Motivation & Problem Statement:
- Modern MLLMs struggle with long, high-resolution videos because they process every pixel equally, leading to computational waste due to significant spatiotemporal redundancy.
- Existing token pruning methods typically only prune tokens within the LLM or between the ViT and LLM, leaving the ViT to still process all pixels, which creates a huge efficiency bottleneck.
- This limitation prevents MLLMs from scaling to real-world applications requiring long-form and high-resolution video understanding.
- Figure 1 illustrates how static backgrounds only need to be viewed once, highlighting the redundancy.
Methodology & Key Results:
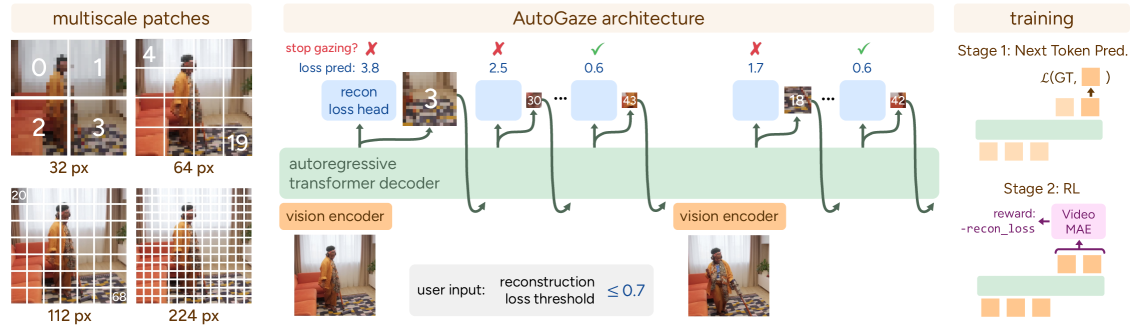
- AutoGaze 는 3M-parameter의 lightweight model로, 비디오 프레임을 인코딩하고 이전 프레임 및 선택된 패치 이력을 기반으로 multi-scale patch index를 autoregressively하게 디코딩하여 정보가 풍부한 패치만 선택하고 중복된 패치를 제거합니다 [cite: 1, Figure 2].
- Reconstruction loss threshold를 사용자 지정하여 해당 손실 내에서 비디오를 재구성할 수 있는 최소한의 패치 세트를 선택하며, 예측된 손실이 임계값 아래로 떨어지면 gazing을 자동으로 중단합니다 [cite: 1, Figure 2].
- 훈련은 Next-Token Prediction (NTP) 사전 훈련과 Reinforcement Learning (RL) 사후 훈련의 두 단계로 이루어집니다 [cite: 1, Figure 2]. NTP는 greedy search로 수집된 gazing sequences를 통해 이루어지며, RL은 reconstruction reward를 사용하여 gazing quality를 더욱 개선합니다.
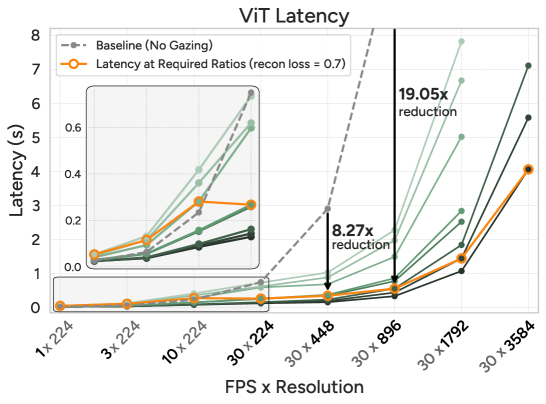
- AutoGaze는 visual tokens를 4배에서 100배 까지 줄여주고, ViTs를 최대 19배 , MLLMs를 최대 10배 가속화하여 1K-frame, 4K-resolution 비디오 처리를 가능하게 합니다 [cite: 1, Figure 7].
- HLVid 벤치마크에서 AutoGaze를 사용한 MLLM은 기존 Baseline 대비 10.1% 성능 향상을 보였으며, 이전 SOTA MLLM보다 4.5% 더 우수한 결과를 달성했습니다 [cite: 1, Table 1].
- AutoGaze는 optical flow 가 높은 패치에 더 자주 gazing하며 [cite: 1, Figure 3], 더 상세한 패치에는 finer scales 를 사용합니다 [cite: 1, Figure 4]. 또한 OOD(Out-of-Distribution) 비디오에서도 일반화되는 능력을 보였습니다 [cite: 1, Figure 5].
Conclusion & Impact:
- AutoGaze 는 ViT 및 MLLM의 효율성을 향상시키기 위해 중복되는 비디오 패치를 제거하는 lightweight framework를 제안합니다.
- 이 연구는 Multi-modal Large Language Models (MLLMs)가 long-form, high-resolution 비디오를 처리하는 데 있어서의 심각한 확장성 문제를 해결하며, 실제 애플리케이션에 필수적인 비디오 이해를 가능하게 합니다.
- 새롭게 도입된 HLVid 벤치마크는 long-form 및 high-resolution 비디오 이해를 평가하는 데 있어 중요한 리소스를 제공하며, AutoGaze는 이 벤치마크에서 SOTA 성능을 달성했습니다.
- 이러한 효율성 및 성능 향상은 비디오 이해 분야에서 MLLM의 적용 범위를 크게 확장하고, 자율 주행, 감시, 엔터테인먼트 등 다양한 산업 분야에 긍정적인 영향을 미칠 것으로 예상됩니다.
Figures to select:
- Figure 1: What is AutoGaze paying attention to? (Overall concept, very illustrative)
- Figure 2: Architecture and training pipeline of AutoGaze. (Key methodology)
- Figure 7: Efficiency gain on ViTs and MLLMs with AutoGaze. (Key quantitative result)
- Table 1: Comparison to state-of-the-art MLLMs. (Key quantitative result)
I will pick Figure 1, Figure 2, and Figure 7 as they represent the concept, architecture, and key efficiency results, and they are images. Table 1 is good but I need to focus on images.
Figure 1 : Original video, multi-scale gazed patches, and reconstructed video examples.
image_url: https://arxiv.org/html/2603.12254v1/x1.png
caption_kr: "AutoGaze의 시선 집중 예시"
Figure 2 : Architecture and training pipeline of AutoGaze.
image_url: https://arxiv.org/html/2603.12254v1/x2.png
caption_kr: "AutoGaze 아키텍처 및 훈련 파이프라인"
Figure 7 : Efficiency gain on ViTs and MLLMs with AutoGaze.
image_url: https://arxiv.org/html/2603.12254v1/x7.png
caption_kr: "AutoGaze를 통한 ViT 및 MLLM 효율성 향상"
Let's start writing the summary. 저자: Baifeng Shi, Stephanie Fu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AutoGaze : Multi-modal Large Language Models (MLLMs) 및 Vision Transformers (ViTs)의 효율성을 개선하기 위해 비디오 내의 redundant한 spatiotemporal patches를 제거하는 lightweight (3M-parameter) 모듈입니다. 이 모듈은 autoregressively하게 multi-scale patches의 최소 세트를 선택하여 사용자 지정 reconstruction loss threshold 내에서 비디오를 재구성합니다.
- MLLMs (Multi-modal Large Language Models) : 일반적인 비디오 이해 (예: 비디오 QA, 캡셔닝) 작업을 수행하기 위해 텍스트와 비전 데이터를 모두 처리하도록 설계된 모델입니다.
- ViT (Vision Transformer) : 이미지 및 비디오의 visual token을 처리하는 데 사용되는 트랜스포머 기반의 아키텍처입니다. MLLMs 내에서 비디오 프레임 인코딩에 주로 활용됩니다.
- HLVid : AutoGaze의 scalability를 평가하기 위해 저자들이 새롭게 도입한 high-resolution, long-form video QA 벤치마크입니다. 최대 5분 길이의 4K-resolution 비디오와 해당 QA 쌍으로 구성되어 있습니다.
- Multi-scale Patches : 비디오의 다양한 detail level을 효율적으로 표현하기 위해 여러 해상도(scales)의 패치를 선택하는 기능입니다. 이를 통해 정적인 영역에는 coarser scale을, 세부 정보가 필요한 영역에는 finer scale을 사용하여 정보 손실 없이 패치 수를 줄일 수 있습니다 [cite: 1, Figure 2].
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Multi-modal Large Language Models (MLLMs)의 발전은 일반 목적의 비디오 이해 분야에서 상당한 진전을 가져왔습니다. 그러나 이러한 모델들은 long-form, high-resolution 비디오를 처리하는 데 심각한 어려움을 겪고 있습니다. 주된 문제는 Vision Transformers (ViTs) 또는 LLM이 비디오 내의 상당한 spatiotemporal redundancy에도 불구하고 모든 픽셀을 동등하게 처리함으로써 발생하는 계산 낭비 때문입니다. 기존 연구들은 주로 LLM 내에서 또는 ViT와 LLM 사이에서 token pruning을 시도했지만, ViT 자체는 여전히 모든 픽셀을 처리해야 하므로 긴 고해상도 비디오로 확장하는 데 있어 효율성 bottleneck이 발생합니다. 이러한 한계는 실시간 처리와 고품질 세부 정보를 요구하는 자율 주행, 감시, 엔터테인먼트와 같은 실제 애플리케이션에서 MLLM의 활용을 제약합니다. 예를 들어, Figure 1 은 정적인 배경과 같은 중복 영역은 한 번만 보아도 충분함을 보여주며, 기존 모델의 비효율성을 강조합니다 [cite: 1, Figure 1]. 따라서, computation cost를 줄이면서 정보 손실 없이 비디오 데이터를 효율적으로 처리할 수 있는 새로운 접근 방식의 필요성이 제기됩니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 AutoGaze 라는 3M-parameter의 lightweight module을 제안합니다. AutoGaze는 ViT로 처리되기 전에 비디오에서 redundant한 patches를 제거합니다. 이 모델은 비디오의 각 프레임을 처리하고, 이전 프레임 및 이전에 선택된 패치 정보를 기반으로 multi-scale patches의 인덱스를 autoregressively하게 디코딩하여, 사용자 정의 reconstruction loss threshold 내에서 현재 프레임을 재구성할 수 있는 최소한의 패치 세트를 선택합니다 [cite: 1, Figure 2]. AutoGaze는 예측된 reconstruction loss가 임계값 아래로 떨어지면 자동으로 gazing을 중단함으로써 효율적인 처리를 가능하게 합니다.
AutoGaze의 훈련은 두 가지 주요 단계로 구성됩니다 [cite: 1, Figure 2]. 첫째, greedy search 알고리즘을 통해 수집된 gazing sequences를 사용하여 Next-Token Prediction (NTP) 방식으로 사전 훈련됩니다. 둘째, 사전 훈련된 모델의 gazing quality를 개선하기 위해 reconstruction reward를 사용하는 Reinforcement Learning (RL) 방식으로 사후 훈련됩니다. 이 훈련 파이프라인은 AutoGaze가 새로 나타나는 content에 집중하고 반복되는 정보를 무시하며, multi-scale patches를 사용하여 넓은 영역을 coarser하게 커버하고 필요한 곳에서 finer detail로 확대하는 법을 학습하게 합니다.
실험 결과는 AutoGaze의 뛰어난 효율성과 성능을 입증합니다. AutoGaze는 비디오의 visual tokens를 4배에서 100배 까지 줄였으며, 이는 ViTs를 최대 19배 , MLLMs를 최대 10배 가속화합니다 [cite: 1, Figure 7]. 이러한 효율성 덕분에 AutoGaze는 MLLMs를 1K-frame, 4K-resolution 비디오로 확장할 수 있게 하며, VideoMME 벤치마크에서 67.0% 의 성능을 달성하는 등 다양한 비디오 벤치마크에서 우수한 결과를 보였습니다. 특히, 새로 도입된 HLVid 벤치마크에서 AutoGaze를 사용한 MLLM은 Baseline 대비 10.1% 성능 향상을 기록하며, 이전 SOTA MLLM보다 4.5% 더 높은 성능을 달성했습니다 [cite: 1, Table 1]. 또한, AutoGaze는 움직이는 패치에 더 자주 gazing하고 [cite: 1, Figure 3], 상세한 패치에는 더 finer scale을 사용하며 [cite: 1, Figure 4], OOD (Out-of-Distribution) 비디오에서도 일반화되는 능력을 보여줍니다 [cite: 1, Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Vision Transformers (ViTs) 및 Multi-modal Large Language Models (MLLMs)의 효율성을 획기적으로 향상시키기 위해 redundant한 비디오 패치를 제거하는 lightweight framework인 AutoGaze 를 소개합니다. AutoGaze는 greedy 알고리즘으로 수집된 gazing sequences에 대한 Next-Token Prediction (NTP)과 reconstruction reward를 활용한 Reinforcement Learning (RL)을 통해 훈련되어, 사용자 지정 임계값 내에서 비디오를 재구성할 수 있는 multi-scale patches의 최소 세트를 선택하는 능력을 학습합니다.
실증적으로, AutoGaze는 visual tokens를 4배에서 100배 까지 줄여주며, ViTs와 MLLMs를 각각 최대 19배 와 10배 까지 가속화하여, 기존에는 어려웠던 1024-frame, 4K-resolution 비디오 이해를 가능하게 합니다. 이러한 효율성 증대는 다양한 비디오 벤치마크에서 성능 향상으로 이어졌습니다. 또한, 저자들은 long-form (5분), high-resolution (4K) 비디오 QA를 위한 최초의 벤치마크인 HLVid 를 도입했으며, AutoGaze를 탑재한 MLLM은 이 벤치마크에서 이전 SOTA 모델을 4.5% 능가하는 성능을 보였습니다.
AutoGaze의 개발은 Multi-modal Large Language Models (MLLMs)가 long-form, high-resolution 비디오를 처리하는 데 있어 직면했던 중요한 확장성 문제를 해결합니다. 이는 비디오 이해 분야의 학술적 연구뿐만 아니라, 자율 주행, 감시 시스템, 엔터테인먼트 콘텐츠 분석 등 고해상도 및 장기 비디오 분석이 필수적인 다양한 산업 응용 분야에 혁신적인 영향을 미칠 것으로 기대됩니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
- [논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
- [논문리뷰] Watch, Remember, Reason: Human-View Video Understanding with MLLMs
- [논문리뷰] VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
- [논문리뷰] M^3Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Review 의 다른글
- 이전글 [논문리뷰] 2Xplat: Two Experts Are Better Than One Generalist
- 현재글 : [논문리뷰] Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
- 다음글 [논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
댓글