[논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
링크: 논문 PDF로 바로 열기
저자: Jaewon Min, Jaeeun Lee, Yeji Choi, Paul Hyunbin Cho, Jin Hyeon Kim, Tae-Young Lee, Jongsik Ahn, Hwayeong Lee, Seonghyun Park, Seungryong Kim et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Degradation-Aware Optical Flow : 실세계의 손상된 비디오(corrupted videos)로부터 정확한 dense correspondence를 추정하는 것을 목표로 하는 새로운 태스크입니다.
- Diffusion Models : 노이즈 제거(denoising) 과정을 통해 잠재 표현(latent representation)을 반복적으로 정제하는 생성 모델(generative models)로, 이미지 복원(image restoration)에 활용되며 풍부한 구조적(structural) 및 의미적(semantic) 정보를 인코딩하는 것으로 알려져 있습니다.
- End-Point Error (EPE) : 광학 흐름(optical flow) 추정의 정확도를 평가하는 일반적인 지표로, 추정된 흐름 벡터와 Ground-Truth 흐름 벡터 간의 평균 유클리드 거리(Euclidean distance)를 측정합니다.
- Full Spatio-Temporal Attention : 여러 프레임과 모달리티(modalities)에 걸쳐 토큰(tokens)에 집중하도록 확장된 어텐션 메커니즘으로, 비디오 처리에서 프레임 간 추론(inter-frame reasoning)을 가능하게 합니다.
- MM-DiT (Multi-Modal Diffusion Transformer) : 여러 모달리티별 토큰 시퀀스(예: HQ latent, LQ conditioning, text)를 멀티모달 어텐션(multi-modal attention) 메커니즘을 통해 처리하는 확산 모델 백본입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
고품질 데이터로 훈련된 Optical Flow 모델들은 블러(blur), 노이즈(noise), 압축 아티팩트(compression artifacts)와 같은 실제 환경의 손상(real-world corruptions)에 직면할 때 성능이 심각하게 저하됩니다. 기존 연구인 RobustSpring과 같은 Dense Matching 모델의 강건성(robustness)에 대한 포괄적인 연구는 있었지만, 손상된 입력으로부터 Optical Flow를 정확하게 추정하는 것이 진정으로 불가능한지에 대한 근본적인 질문은 여전히 해결되지 않았습니다.
저자들은 이러한 문제의식에서 Degradation-Aware Optical Flow라는 새로운 태스크를 제안하며, 손상된 입력(severely degraded inputs)으로부터 직접 Dense Correspondence를 추정하는 데 초점을 맞춥니다. 이 태스크는 손상이 미세한 텍스처를 파괴하고 움직임 경계(motion boundaries)를 약화시켜 신뢰할 수 있는 매칭(matching)을 위한 시각적 증거(visual evidence)를 불충분하게 만들기 때문에 본질적으로 불확정적(ill-posed)입니다. 이러한 상황에서 Correspondence Estimation은 단순한 분포 변화(distribution shift)의 문제가 아니라, 내재적으로 모호해집니다. 단순히 깨끗한 훈련 데이터에 합성 손상을 추가하는 것만으로는 이 문제를 효과적으로 해결할 수 없으며, Dense Matching을 위한 공간 구조(spatial structure)를 보존하고 손상 패턴에 민감하여 손상 과정에서 손실된 정보를 복구할 수 있는 Representation이 필요합니다 [cite: 1, Figure 1].
최근 Image Restoration Diffusion Models이 손상에 민감한(degradation-aware) Representation을 제공할 수 있음을 보여주었지만, 이는 시간적 인식(temporal awareness)이 부족하여 Optical Flow 추정에는 한계가 있습니다. 반면, Video Restoration Diffusion Models은 시간적 역학(temporal dynamics)을 공동으로 모델링하지만, 여러 프레임을 시간적으로 압축된 잠재 표현으로 인코딩하여 프레임별 공간 구조(per-frame spatial structure)를 분리된 엔티티로 보존하지 못해 픽셀 레벨 Correspondence Estimation에 부적합합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
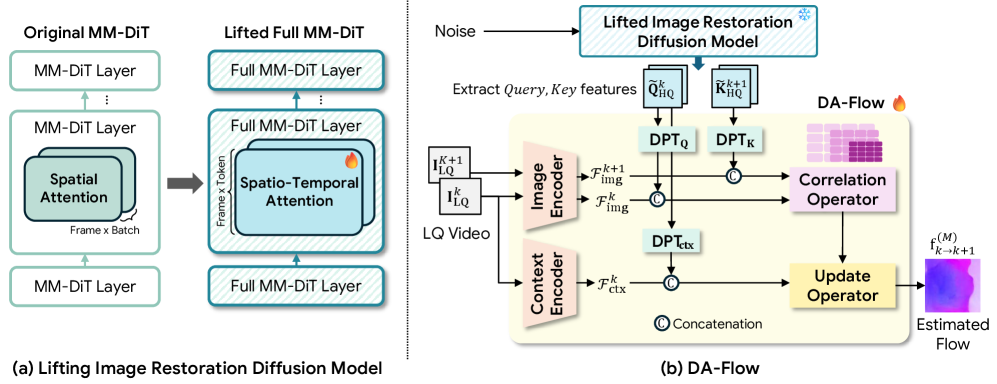
저자들은 손상에 강인한(degradation-aware) Representation과 Dense Matching의 구조적 요구사항을 조화시키기 위해, 사전 훈련된 Image Restoration Diffusion Model인 DiT4SR 을 기반으로 시작합니다. 이 모델은 프레임 수준에서 완전한 공간 해상도(full spatial resolution)를 유지하며, 모든 레이어에 Full Spatio-Temporal Attention 을 주입하여 여러 프레임을 처리하도록 "리프팅(lifting)"합니다. 이 설계는 각 프레임에 독립적인 공간 잠재 표현(spatial latents)을 유지하면서 움직임 추론(motion reasoning)을 위한 제어된 시간적 상호작용(temporal interaction)을 가능하게 합니다.
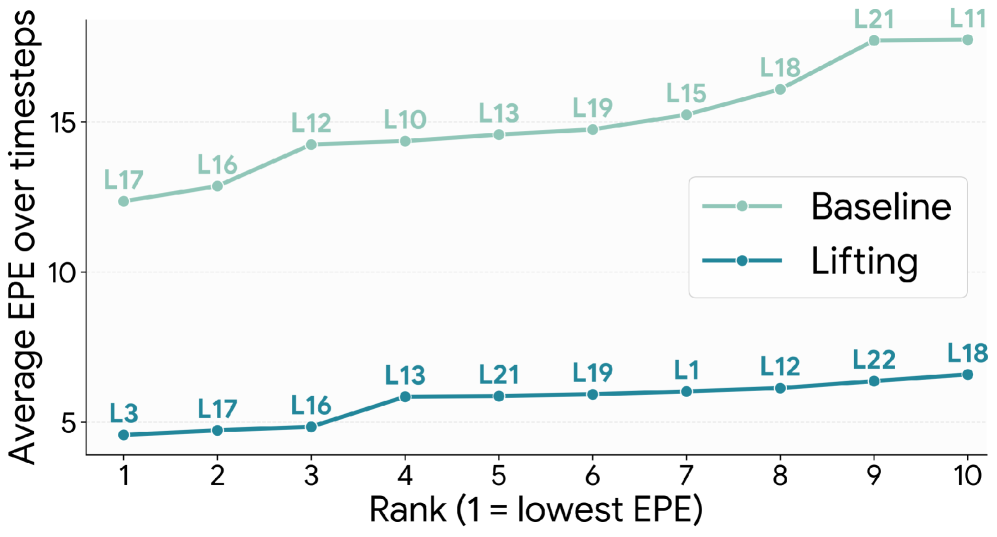
리프팅된 모델의 중간 표현(intermediate representations) 중에서, 특히 HQ Diffusion Branch의 Full Spatio-Temporal Attention Layer 에서 추출된 Query 및 Key Features 가 강력한 기하학적 Correspondence를 인코딩함을 입증했습니다. 실험 분석 결과, 리프팅된 모델은 베이스라인(Baseline) 대비 모든 레이어에서 일관되게 낮은 EPE 를 달성했으며 [cite: 1, Figure 3], 디노이징 스텝(denoising steps) 전반에 걸쳐 안정적인 성능을 유지했습니다 [cite: 1, Figure 3].
이러한 발견을 바탕으로, 저자들은 RAFT 기반의 DA-Flow 라는 Degradation-Aware Optical Flow Network를 제안합니다. DA-Flow 는 리프팅된 모델에서 얻은 Degradation-Aware Diffusion Features를 기존의 CNN 기반 인코더 Features와 융합하는 하이브리드 아키텍처(hybrid architecture)입니다 [cite: 1, Figure 2]. Diffusion Features의 coarse spatial grid 문제를 해결하기 위해, DPT 기반의 학습 가능한 업샘플링 스테이지(upsampling stage)를 도입하여 특징 맵(feature maps)을 H/8xW/8 해상도로 복원합니다. 이는 Diffusion Features의 degradation-aware prior와 CNN Features의 fine-grained spatial detail을 결합하여, correlation 및 iterative update 단계에서 모두 이점을 얻도록 합니다.
Ground-Truth Optical Flow를 확보하기 어려운 실제 손상 비디오의 특성을 고려하여, DA-Flow는 고품질(HQ) 비디오에 사전 훈련된 Optical Flow 모델( SEA-RAFT )을 적용하여 생성된 Pseudo Ground-Truth Flow 를 사용하여 훈련됩니다.
정량적 결과(Quantitative Results) 측면에서, DA-Flow는 Sintel , Spring , TartanAir 등 다양한 벤치마크에서 기존 Optical Flow Method들을 크게 능가했습니다 [cite: 1, Table 1]. 특히 Sintel 데이터셋에서 DA-Flow는 EPE 6.912 를 기록하여, RAFT (10.693) , SEA-RAFT (10.185) , FlowSeek (10.241) 대비 현저히 낮은 오류율을 보였습니다 [cite: 1, Table 1]. Spring 데이터셋에서는 EPE 2.207 을 달성하여, SEA-RAFT (2.703) 및 FlowSeek (2.861) 보다 우수한 성능을 입증했습니다 [cite: 1, Table 1]. 또한, DA-Flow는 대부분의 벤치마크에서 1px, 3px, 5px 임계값에서의 Outlier Rates 가 가장 낮아, 대부분의 픽셀에 대해 더 정확한 추정치를 생성함을 보여주었습니다 [cite: 1, Table 1].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 손상된 입력으로부터 직접적인 Dense Correspondence 추정을 목표로 하는 Degradation-Aware Optical Flow 라는 새로운 태스크와 이를 해결하기 위한 DA-Flow 를 제안합니다. DA-Flow는 사전 훈련된 Image Restoration Diffusion Model을 Spatio-Temporal Attention을 통해 멀티 프레임 처리(multi-frame processing)가 가능하도록 리프팅(lifting)함으로써, Degradation-Aware Prior와 Geometric Correspondence 정보를 동시에 인코딩하는 중간 표현을 활용합니다. 이 접근 방식은 Dense Matching에 필수적인 공간 구조를 보존하면서 손상된 환경에서도 정확한 Optical Flow 추정을 가능하게 합니다.
광범위한 실험 결과, DA-Flow는 손상된 Optical Flow 벤치마크에서 기존 방법론 대비 일관되게 높은 Flow Estimation Accuracy 를 달성했습니다. 이 연구는 Optical Flow 분야의 주요한 실제 문제에 대한 효과적인 해결책을 제시하며, Diffusion Models을 전통적인 Optical Flow 파이프라인과 통합함으로써 어려운 환경에서의 비디오 분석 애플리케이션에 대한 더욱 견고하고 정확한 발전을 위한 길을 열었습니다. DA-Flow는 Diffusion Models의 강력한 생성 능력과 전통적인 CNN의 공간적 디테일 보존 능력을 결합하여, 미래의 비디오 처리 및 컴퓨터 비전 연구에 중요한 시사점을 제공합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
- [논문리뷰] RealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
- [논문리뷰] LightsOut: Diffusion-based Outpainting for Enhanced Lens Flare Removal
- [논문리뷰] SynCity 3000: Bootstrapping Scene-Scale 3D Diffusion
- [논문리뷰] MV-Forcing: Long Multi-View Video Generation via 4D-Grounded Spatio-Temporal Self-Forcing
Review 의 다른글
- 이전글 [논문리뷰] Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
- 현재글 : [논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
- 다음글 [논문리뷰] Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
댓글