[논문리뷰] Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
링크: 논문 PDF로 바로 열기
저자: Shoubin Yu, Lei Shu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Ego2Web : 사용자의 실시간
egocentric video perception에 기반한web agentTask를 평가하기 위해 제안된 새로운 벤치마크. - Multimodal AI Agents : 텍스트, 이미지, 비디오 등 다양한
modality의 정보를 처리하고 이해하여 복잡한real-world workflow를 자동화하는AI Agent. - Egocentric Video Perception : 사용자의
first-person perspective에서 캡처된 비디오 입력으로,AR glasses와 같은 웨어러블 기기를 통해 사용자의physical surroundings를perceive하는 것을 시뮬레이션한다. - Web Agent Execution :
online environment에서web task를planning하고interaction하여 완료하는AI Agent의 능력. - Visual Grounding :
egocentric video에서 관찰된visual cue(객체, 브랜드, 이벤트 등)를online web action을 위한symbolic concept에 연결하고reason하는 과정. - LLM-as-a-Judge :
Large Language Models를 활용하여web agent의task성공 여부를 자동으로 평가하는evaluation framework.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal AI agents는 online web execution을 포함하는 복잡한 real-world workflow를 점차 자동화하고 있습니다. 하지만 기존 web-agent benchmark들은 web-based interaction 및 perception에만 전적으로 초점을 맞춰, 사용자의 physical surroundings에 대한 grounding이 부족하다는 한계가 있습니다. 이러한 한계는 agent가 egocentric visual perception(예: AR glasses를 통해)을 사용하여 주변 환경의 객체를 인식하고 해당 객체와 관련된 online task를 완료해야 하는 crucial scenario에서 evaluation을 방해합니다. 기존 벤치마크들(예: VisualWebArena , OSWorld )은 egocentric vision이 online action에 정보를 제공하는 evaluation setting을 제공하지 않아, agent가 보고 reason하며 digital world에서 행동하는 능력을 측정하거나 향상시키지 못합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 egocentric video perception과 web agent execution을 연결하는 최초의 벤치마크인 Ego2Web 을 제안합니다. Ego2Web은 real-world first-person video recording과 visual understanding, web task planning, online environment interaction이 필요한 web task를 짝지어 구성합니다. 벤치마크 구축을 위해, 저자들은 model-human collaborative pipeline을 설계했습니다. 이 pipeline은 frozen MLLM ( Qwen3-VL )을 사용하여 video clip에서 structured caption을 생성하고, 이를 통해 structured video profile을 만듭니다. 이후 LLM ( GPT-5 )은 이 video profile과 pre-defined된 웹사이트를 기반으로 visual content를 활용해야 하는 web task instruction을 자동으로 생성합니다. 최종적으로 인간 검증 및 보정을 통해 Visual Grounding, Web Feasibility, Instruction Quality를 확보합니다. 그 결과, Ego2Web은 e-commerce, media retrieval, knowledge lookup, local/maps 등 다양한 web task type에 걸쳐 500개 의 고품질 video-instruction pair를 포함합니다

, [Table 6].
Ego2Web의 evaluation을 위해 저자들은 LLM-as-a-Judge 방식의 새로운 자동 evaluation method인 Ego2WebJudge 를 개발했습니다

Ego2WebJudge는 task instruction, action history, screenshots 및 annotated egocentric visual evidence clip을 입력으로 받아 multimodal LLM을 통해 task 성공 여부를 판단합니다. 이 방법은 인간 판단과 약 84% 의 높은 agreement를 달성하여 기존 evaluation method들( WebVoyager , WebJudge )을 크게 능가합니다 [Table 4].
다양한 state-of-the-art agent ( SeeAct , Browser-Use with GPT-4.1 , Gemini-3-Flash , Claude Sonnet 3.7/4.5 , GPT-5.4 )에 대한 experiment 결과, agent들의 performance는 여전히 미흡했으며, human evaluation 대비 oracle performance와 약 40% 의 상당한 headroom이 존재함을 확인했습니다. 특히 BU-Gemini-3-Flash가 human evaluation에서 58.6% SR 을 기록하며 가장 우수한 performance를 보였습니다
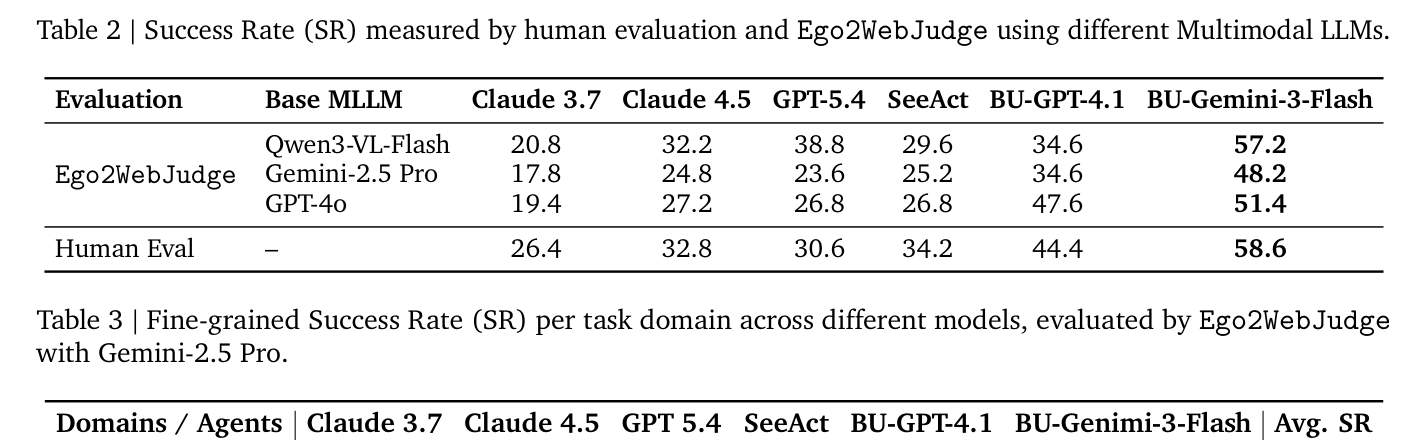
visual input modality의 impact에 대한 ablation study에서는 visual input이 전혀 없을 경우 4.4% SR 로 매우 저조했고, detailed caption만 제공했을 때 23.6% SR 로 향상되었으나, raw video input을 사용했을 때 48.2% SR 로 caption-based setting 대비 두 배 이상의 performance gain을 보였습니다 [Table 5]. 이는 egocentric web-agent task 해결에 true visual perception의 crucial한 필요성을 강조합니다. fine-grained domain analysis에서는 Knowledge Lookup task가 평균 50.0% SR 로 가장 쉬웠고, Local/Maps 및 E-Commerce task는 더 어려웠습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 egocentric visual perception과 web-agent task execution을 연결하는 최초의 벤치마크인 Ego2Web 을 소개했습니다. Ego2Web은 500개 의 자동으로 생성되고 인간이 검증한 video-instruction pair와 live online evaluation을 통해 multimodal agent를 테스트할 수 있는 realistic하고 scalable setting을 제공합니다. 또한, grounded visual cue를 활용하여 task success를 정확하게 판단하는 multimodal LLM-as-a-Judge framework인 Ego2WebJudge 를 제안하여 인간 판단과 높은 agreement를 달성합니다. state-of-the-art multimodal agent에 대한 comprehensive experiment는 visual grounding, reasoning ability, perception-action integration 측면에서 상당한 개선 여지가 있음을 보여줍니다. Ego2Web은 physical 및 digital world를 seamlessly 보고, 이해하고, 행동할 수 있는 진정으로 유능한 차세대 AI assistants 개발을 위한 critical new resource가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] Little Brains, Big Feats: Exploring Compact Language Models
- [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
Review 의 다른글
- 이전글 [논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
- 현재글 : [논문리뷰] Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
- 다음글 [논문리뷰] From Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
댓글