[논문리뷰] From Web to Pixels: Bringing Agentic Search into Visual Perception
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dongming Wu, Xingping Dong, Kaituo Feng, Xinyi Sun, Bokang Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Perception Deep Research: 웹 기반의 외부 정보를 능동적으로 검색하고 추론하여, 이미지 내에 명시되지 않은 숨겨진 대상(target identity)을 식별하고 이를 시각적 인스턴스로 Grounding하는 새로운 연구 프레임워크입니다.
- WebEyes: Perception Deep Research를 평가하기 위해 구축된 객체 지향 벤치마크로, 외부 증거와 지식 집약적 쿼리, 정확한 box/mask 어노테이션을 포함하는 데이터셋입니다.
- Pixel-Searcher: 지식 집약적 쿼리를 분해하고 외부 증거를 수집한 뒤, 이를 통해 숨겨진 대상을 결정하고 시각적 인스턴스와 매핑하는 에이전트 기반의 Search-to-Pixel 워크플로우입니다.
- Search-based Grounding/Segmentation/VQA: 웹 검색을 통해 획득한 증거를 바탕으로 각각 바운딩 박스 예측, 마스크 생성, 영역 단위 답변 선택을 수행하는 WebEyes의 3가지 핵심 태스크 뷰입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 시각적 인지 모델이 이미지 내의 시각적 단서나 모델 내부의 Frozen Knowledge에만 의존하여 발생하는 한계점을 해결하고자 합니다. 실세계의 복잡한 쿼리는 종종 이미지에 없는 최신 정보나 외부 지식을 요구하는데, 기존 연구들은 이러한 Hidden Identity를 해결할 수 있는 능력이 부족합니다. 특히 개방형 환경에서 모델은 외부 증거를 통해 대상의 정체를 파악하고, 이를 이미지 내의 구체적인 객체와 연결해야 하는 고도의 복잡한 과제에 직면해 있습니다 [Figure 1]. 이러한 문제를 정량적으로 측정하기 위한 기존 벤치마크의 부재가 본 연구의 핵심적인 동기입니다.
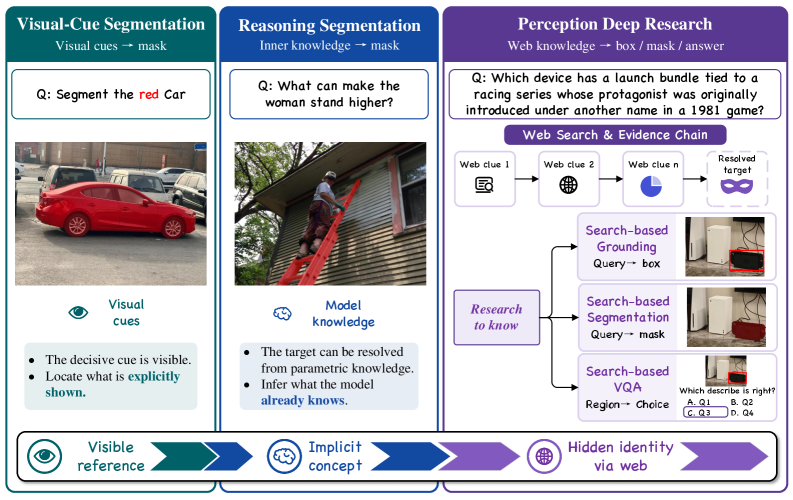
Figure 1 — Perception Deep Research 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 에이전트 기반의 Pixel-Searcher 워크플로우를 제안하며, 이는 지식 집약적 쿼리를 분석하고 외부 검색을 통해 타겟의 가설(hypothesis)을 정립한 후 시각적 툴을 사용하여 인스턴스를 Grounding합니다 [Figure 2, Figure 6]. 제안 방법론은 Search-based Grounding, Search-based Segmentation, Search-based VQA의 세 가지 단계로 구성된 WebEyes 벤치마크에서 평가되었습니다 [Figure 3]. 실험 결과, Pixel-Searcher는 기존의 오픈 소스 모델(예: Qwen3-VL-8B) 대비 모든 태스크에서 성능 향상을 달성하였습니다. 구체적으로, Search-based Grounding에서 IoU 지표가 26.81에서 34.17로, Search-based Segmentation의 경우 gIoU가 35.78에서 39.17로 크게 개선되었습니다 [Table 2, Table 3]. 추가적인 분석 결과, 시스템 실패의 약 75%는 검색 및 엔티티 결정 단계에서 발생하며, 마스크 생성 과정 자체의 병목은 매우 적음이 확인되었습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Perception Deep Research라는 새로운 연구 방향을 제시하고, 이를 체계적으로 평가할 수 있는 WebEyes 벤치마크와 Pixel-Searcher 워크플로우를 통해 해결책을 제공합니다. 이 연구는 모델이 외부 지식을 능동적으로 활용하여 시각적 정보를 정밀하게 Grounding하는 능력이 향상될 수 있음을 증명하였습니다. 해당 연구는 향후 멀티모달 인공지능이 실제 웹 환경에서 보다 복잡한 추론과 인지를 수행하는 데 필요한 기술적 토대를 마련할 것으로 기대됩니다.
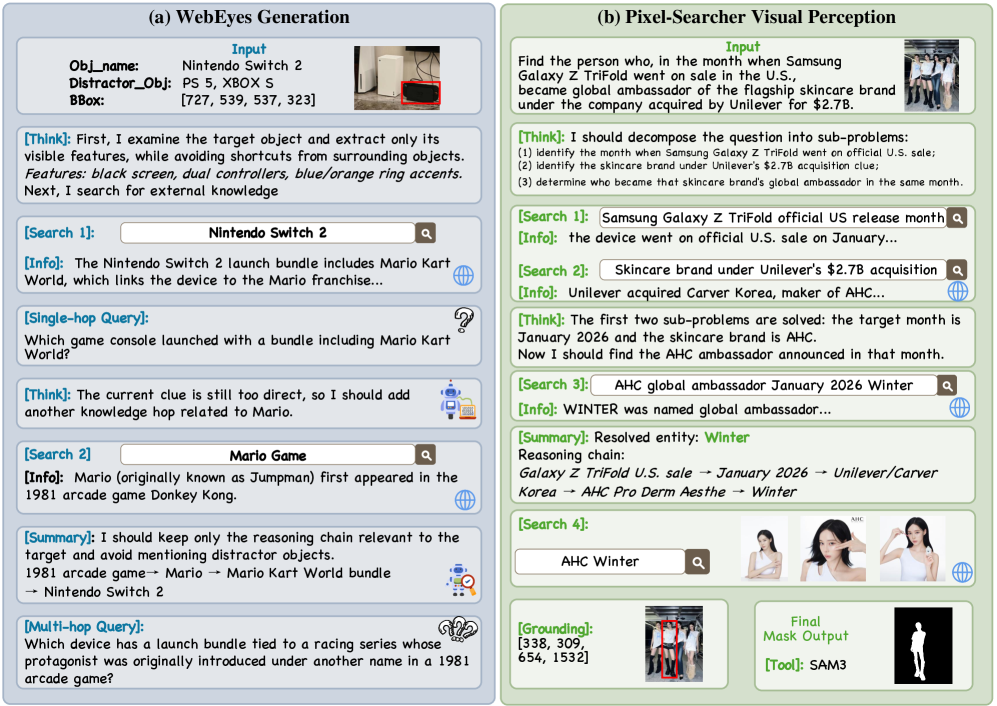
Figure 2 — WebEyes 및 Pixel-Searcher 개요
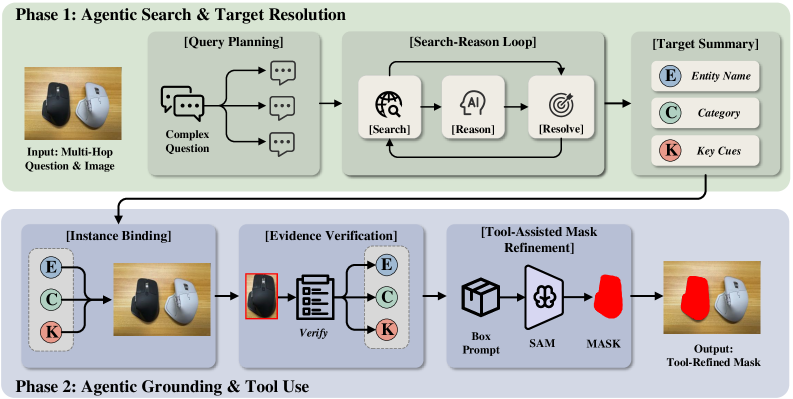
Figure 6 — Pixel-Searcher 워크플로우 상세
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
- [논문리뷰] Thinking with Visual Grounding
Review 의 다른글
- 이전글 [논문리뷰] Do not copy and paste! Rewriting strategies for code retrieval
- 현재글 : [논문리뷰] From Web to Pixels: Bringing Agentic Search into Visual Perception
- 다음글 [논문리뷰] Images in Sentences: Scaling Interleaved Instructions for Unified Visual Generation
댓글