[논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yana Wei, Hongbo Peng, Yanlin Lai, Liang Zhao, Kangheng Lin, En Yu, Keyu Lv, Han Zhou, Yin Tang, Haodong Li, Mitt Huang, Hangyu Guo, Jianjian Sun, Zheng Ge, Xiangyu Zhang, Daxin Jiang, Vishal M. Patel
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Must-Right Rubrics: 모델이 반드시 정답을 맞혀야 하는 필수적인 시각적 사실을 정의한 평가 항목으로, 실패 시 즉시 0점으로 처리되는 Gate 역할을 합니다.
- Easy-Wrong Rubrics: 흔히 발생하는 hallucination, 누락, 혹은 오해를 타겟팅하여 모델의 세밀한 인식 능력을 변별하는 평가 항목입니다.
- Gated Scoring: Must-Right 항목을 통과해야만 Easy-Wrong 항목을 계산하는 비선형 평가 로직으로, 인간의 직관적인 오류 민감성을 모사합니다.
- Circular Peer-Review: 여러 MLLM이 독립적으로 생성한 설명을 상호 비평 및 검증하여 최종적인 'Golden Caption'을 도출하는 품질 관리 파이프라인입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 MLLM 벤치마크가 포화 상태에 이르렀음에도 불구하고, 실제 환경에서의 모델 성능은 여전히 취약하다는 '평가 역설(Evaluation Paradox)'을 해결하고자 합니다 [Figure 1]. 현재의 벤치마크는 holistic한 점수 산출 방식이나 선형적인 평균치를 사용함으로써, 모델의 치명적인 시각적 hallucination을 무시하고 전체 점수를 희석시키는 경향이 있습니다. 특히 기존 평가는 언어적 편향에 의존하여 모델이 진정한 시각적 grounding 없이도 높은 점수를 받을 수 있게 합니다. 저자들은 이러한 한계를 극복하기 위해 인간의 엄격한 시각적 인지 방식을 모사한 새로운 루브릭(rubric) 기반 평가 프레임워크를 제안합니다.
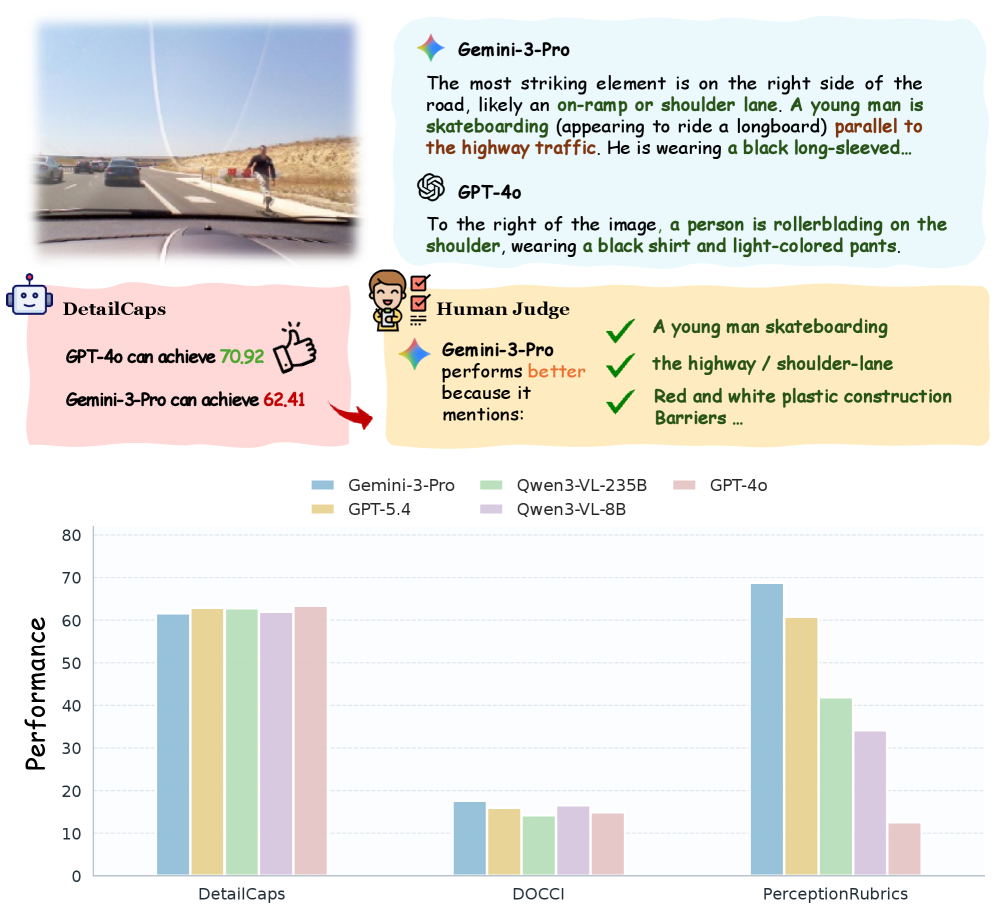
Figure 1 — PerceptionRubrics의 평가 동기
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 1,038개의 고밀도 정보를 포함한 이미지와 10,718개의 원자적 루브릭(atomic rubrics)으로 구성된 PerceptionRubrics를 구축하였습니다 [Table 1]. 제안하는 방법론은 Circular Peer-Review를 통해 고품질의 'Golden Caption'을 생성하고, 이를 기반으로 Must-Right 및 Easy-Wrong의 이중 루브릭 스트림을 설계합니다 [Figure 4]. 평가 지표는 Must-Right 항목을 통과하지 못할 경우 전체 점수를 0점으로 처리하는 엄격한 Gated Scoring 로직을 적용합니다. 실험 결과, 오픈소스 모델(예: Qwen3.5)과 독점 모델(예: Seed-2.0) 사이에는 여전히 약 8%의 인식 격차(perception deficit)가 존재함이 밝혀졌습니다. 또한, PerceptionRubrics는 기존 벤치마크(예: DOCCI) 대비 Vision Arena 등 인간 선호도 지표와 매우 높은 상관관계(Pearson 0.916)를 보이며 정렬 우위를 입증했습니다 [Figure 9].

Figure 4 — PerceptionRubrics 구축 파이프라인
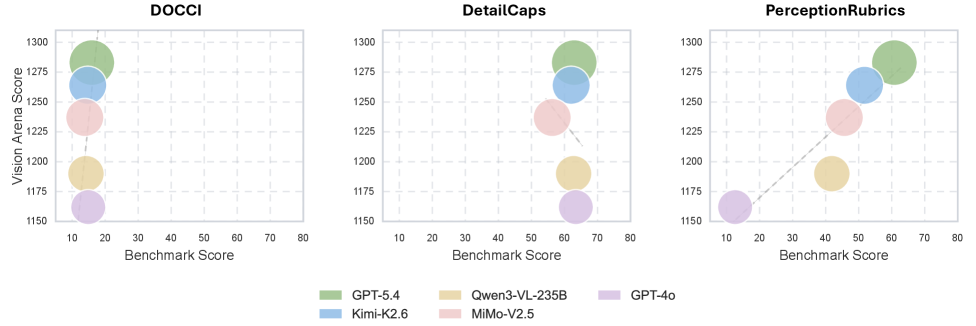
Figure 9 — 인간 선호도 정렬 결과 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 고정밀 시각적 인지 능력을 평가하기 위한 rubric 기반의 새로운 표준을 제시하며, 단순히 통계적 유사도가 아닌 엄격한 사실 기반의 평가로 패러다임을 전환합니다. 특히, Gated Scoring 기법은 모델의 hallucination을 효과적으로 가려내고 실제 사용자 경험과 일치하는 성능 지표를 제공합니다. 이 벤치마크는 향후 MLLM의 시각적 안정성을 검증하고 실용적인 에이전트 개발을 가속화하는 핵심 도구로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
- [논문리뷰] Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
- [논문리뷰] PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
- [논문리뷰] Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
- [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
Review 의 다른글
- 이전글 [논문리뷰] Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
- 현재글 : [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- 다음글 [논문리뷰] Personalization as Inverse Planning: Learning Latent Design Intents for Agentic Slide Generation via Structural Denoising
댓글