[논문리뷰] Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hongxing Li, Xiufeng Huang, Dingming Li, Wenjing Jiang, Zixuan Wang, Haolei Xu, Haolei Xu, Hanrong Zhang, Haiwen Hong, Longtao Huang, Hui Xue, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
1. Key Terms & Definitions (핵심 용어 및 정의)
- P2R (Perceive-to-Reason): fine-grained visual reasoning을 위한 통합 프레임워크로, 인식(perception)과 추론(reasoning) 단계를 명시적으로 분리하여 처리하는 방식입니다.
- Perceiver / Reasoner: P2R 프레임워크 내에서 각각 관련 시각적 증거를 식별하는 역할과 해당 증거를 바탕으로 최종 답안을 도출하는 역할을 수행하는 모델의 기능적 상태를 지칭합니다.
- PRA-GRPO (Perception-Reasoning Alternating GRPO): 최종 답안에 대한 감독 신호만을 사용하여 인식과 추론 단계를 번갈아 가며 최적화하는 role-aware 강화 학습 전략입니다.
- V-Star / HR-Bench: 고해상도 이미지 내의 미세한 시각적 정보를 파악하고 추론해야 하는 능력을 측정하는 대표적인 fine-grained visual reasoning 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VLM이 고해상도 이미지 내의 미세한 시각적 단서를 인식하고 추론하는 능력이 부족하다는 문제에 주목합니다 [Figure 1]. 기존 연구들은 단순히 이미지 영역을 반복적으로 크롭(crop)하거나 검색(search)하는 방식을 사용하는데, 이는 인식과 추론 과정을 명확히 구분하지 않아 최적화가 어렵고 연산 비용이 높다는 한계가 있습니다. 특히 이러한 방식들은 '어디를 볼지(perception)'와 '어떻게 추론할지(reasoning)'를 하나의 과정으로 묶어버림으로써 명확한 학습 신호 전달을 방해합니다. 따라서 저자들은 인식을 위한 단계와 추론을 위한 단계를 명시적으로 분리하는 새로운 접근 방식이 필요하다고 주장합니다.
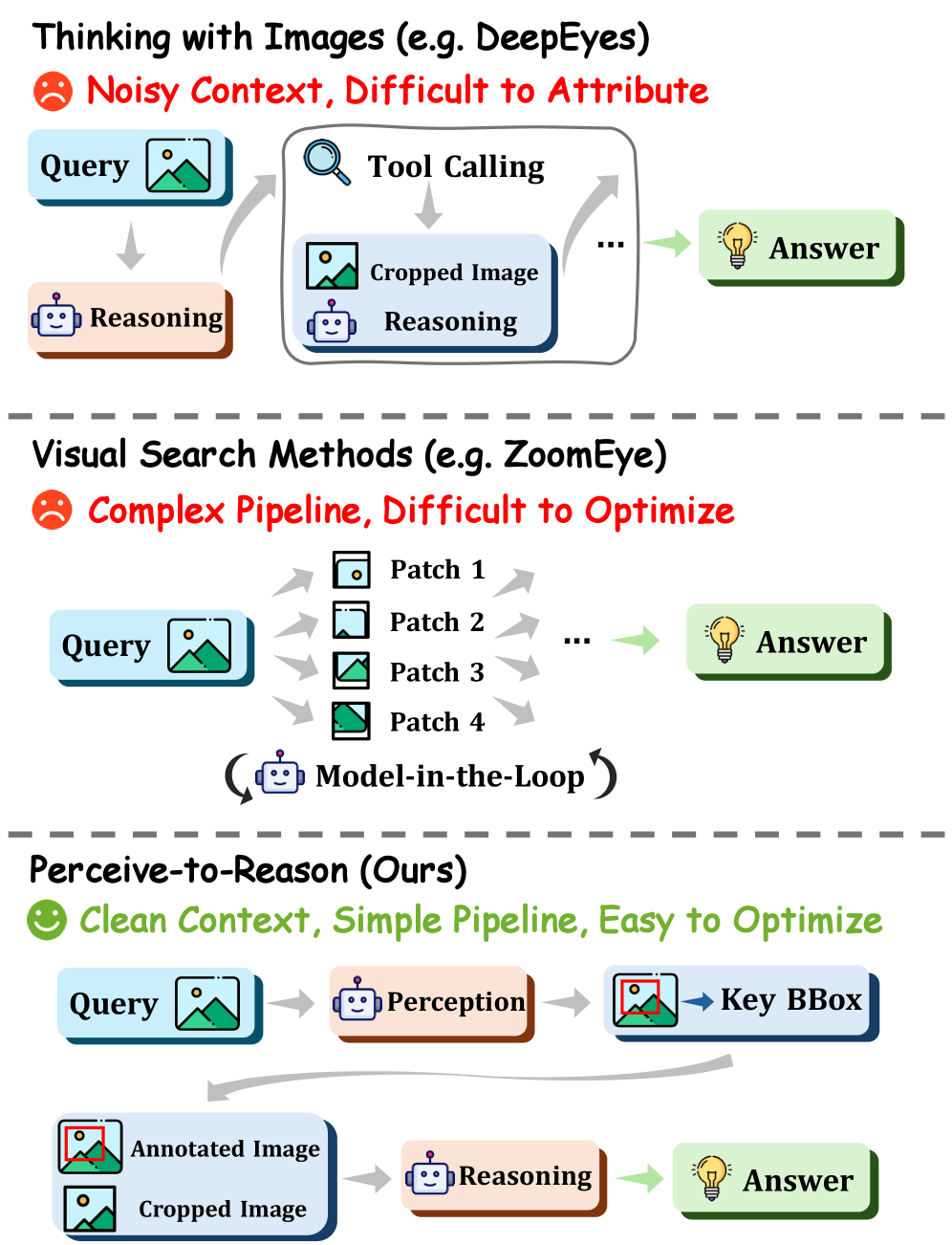
Figure 1 — P2R 프레임워크의 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 두 단계의 추론 과정(Perceive-to-Reason)과 이를 효과적으로 학습시키기 위한 PRA-GRPO 전략을 제안합니다 [Figure 2]. 인퍼런스 시, 모델은 먼저 Perceiver로서 질문과 관련된 시각적 증거를 로컬라이제이션(localization)한 후, Reasoner가 해당 증거를 바탕으로 답안을 생성합니다 [Figure 2]. 학습 과정에서는 PRA-GRPO를 통해 인식 중심 단계와 추론 중심 단계를 번갈아 수행하며, 최종 답안의 정확도만을 보상(reward)으로 사용하여 모델 파라미터를 업데이트합니다 [Figure 3]. 실험 결과, P2R-4B 모델은 V-Star 벤치마크에서 93.2%, HR-Bench-4K에서 81.9%, HR-Bench-8K에서 80.5%의 성능을 기록하며 베이스라인 모델 대비 대폭 향상된 결과를 보여주었습니다 [Table 1]. 또한, MME-RealWorld-Lite 벤치마크에서도 광범위한 성능 개선을 입증하며 일반적인 멀티모달 이해 능력을 증명하였습니다 [Table 2].
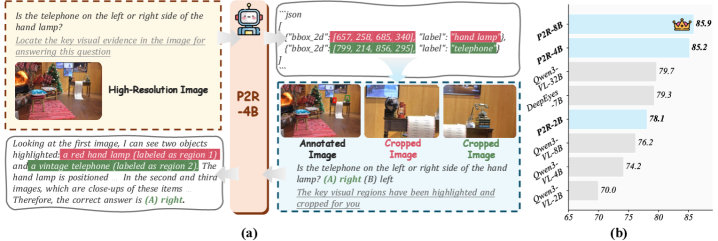
Figure 2 — P2R 추론 파이프라인 개요
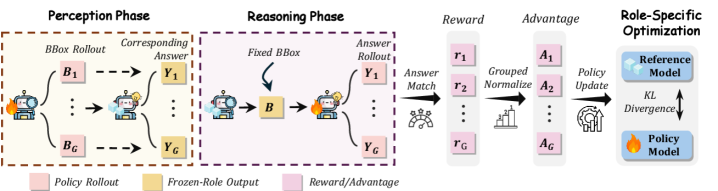
Figure 3 — PRA-GRPO 학습 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 시각적 인식과 논리적 추론을 명시적으로 분리하는 것이 fine-grained visual reasoning 성능 향상의 핵심임을 입증했습니다. 제안된 P2R 프레임워크와 PRA-GRPO 전략은 고가의 bounding box 주석 없이도 최종 답안 데이터만으로 효과적인 학습이 가능하다는 점에서 큰 학술적, 실용적 가치를 지닙니다. 이 연구는 향후 VLM이 복잡한 고해상도 시각 환경에서 보다 정교하고 신뢰성 있는 추론을 수행할 수 있도록 하는 강력한 방법론적 토대를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- [논문리뷰] VISTA: View-Consistent Self-Verified Training for GUI Grounding
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
Review 의 다른글
- 이전글 [논문리뷰] NoPA: Non-Parametric Online 3D Scene Graph Generation
- 현재글 : [논문리뷰] Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
- 다음글 [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
댓글