[논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
링크: 논문 PDF로 바로 열기
메타데이터
저자: Huaisong Zhang, Hao Yu, Yuxuan Zhang, Jiahe Wang, Xinrui Chen, Haoxiang Cao, Feng Lu, Wendong Zhang, Changqian Yu, Chun Yuan
1. Key Terms & Definitions (핵심 용어 및 정의)
- SDG (Structured Defect Grounding): T2I 모델의 결함을
(location, type, reason, importance)라는 4개의 요소로 구성된 튜플 형태로 정형화하여 예측하는 인스턴스 단위의 진단 프레임워크입니다. - SDG-30K: 현대적인 4개의 T2I 모델로부터 생성된 30,096개의 이미지를 포함하며, 박스 기반의 결함(artifact 및 misalignment) 정보가 주석 처리된 대규모 데이터셋입니다.
- BoxFlow-GRPO: SDG가 예측한 구조적 결함 정보를 바탕으로, 결함의 중요도(importance)에 따라 차등적인 공간 가중치를 부여한 보상 맵을 생성하여 diffusion 모델을 정렬(alignment)하는 학습 기법입니다.
- SDG Detector: VLM(주로 Qwen3-VL-4B-Instruct 기반)을 활용하여 이미지와 프롬프트로부터 추론 과정(CoT)을 거친 후 정형화된 결함 세트를 출력하도록 학습된 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 T2I 모델이 생성하는 이미지의 국소적이고 미묘한 결함을 효과적으로 진단하고 해결하지 못하는 기존 scalar 기반 평가 방식의 한계를 해결하고자 합니다. 기존의 heatmap 기반 dense feedback 방식은 픽셀 필드 회귀(pixel-field regression)에 의존하여 가변적인 결함의 개수나 의미적 이유를 개별 인스턴스에 할당하는 데 어려움을 겪습니다 [Figure 1]. 이러한 representation bottleneck을 극복하기 위해, 저자들은 결함 진단을 구조화된 세트 예측 문제로 재정의하는 SDG 프레임워크를 제안합니다.

Figure 1 — 기존 피드백 방식과 SDG 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VLM 기반의 SDG detector를 활용하여 결함을 구조적 튜플로 진단하고, 이를 BoxFlow-GRPO를 통해 확산 모델의 공간적 정렬에 활용하는 통합 프레임워크를 제안합니다 [Figure 2]. SDG detector는 SFT와 GRPO를 통해 2단계 학습을 진행하며, 특히 BoxFlow-GRPO는 결함의 중요도(importance score)를 반영하여 적응형 공간 보상을 계산함으로써 모델의 학습을 유도합니다. 실험 결과, SDG detector는 제로샷 설정에서 기존 최첨단 VLM들 대비 우수한 결함 인지 성능을 보였습니다 [Table 2]. 구체적으로 SDG(GRPO) 방식은 아티팩트와 정렬 오류(misalignment) 식별에서 인간 수준에 근접한 BoxF1@0.5 수치를 기록하였습니다. 또한, BoxFlow-GRPO를 적용한 모델은 다양한 벤치마크 지표에서 사진적 사실성을 유지하면서도, 결함 감소 효과가 탁월함을 입증하였습니다 [Table 5].
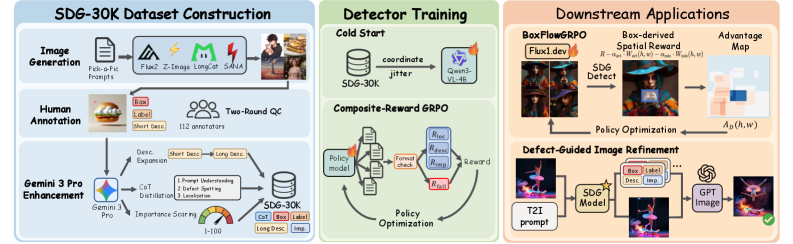
Figure 2 — SDG 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 연구는 결함 진단을 인스턴스 단위의 구조화된 예측으로 전환함으로써 T2I 모델의 평가와 정렬을 위한 새로운 인터페이스를 제시합니다. 제안된 SDG와 BoxFlow-GRPO는 기존의 heatmap 기반 접근법보다 정밀한 공간적 제어를 가능하게 하며, 실제 생성 모델의 품질 개선을 위한 actionable한 피드백을 제공합니다. 이 연구는 생성형 AI의 평가 및 모델 정렬 방법론에 있어 더 정교한 진단 도구의 필요성을 시사하며, 관련 연구 분야의 기준을 한 단계 높이는 데 기여할 것으로 기대됩니다.

Figure 4 — 정성적 결과 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
- [논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
- [논문리뷰] TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward
- [논문리뷰] Enhancing Spatial Understanding in Image Generation via Reward Modeling
- [논문리뷰] GeoAgent: Learning to Geolocate Everywhere with Reinforced Geographic Characteristics
Review 의 다른글
- 이전글 [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- 현재글 : [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- 다음글 없음
댓글