[논문리뷰] VISTA: View-Consistent Self-Verified Training for GUI Grounding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xinyu Qiu, Yunzhu Zhang, Heng Jia, Shuheng Shen, Changhua Meng, Linchao Zhu et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GUI Grounding: 자연어 instruction을 기반으로 스크린샷 내의 정확한 인터페이스 요소(버튼, 아이콘 등)를 찾아 클릭 좌표를 출력하는 작업입니다.
- GRPO (Group Relative Policy Optimization): 여러 개의 rollout을 하나의 그룹으로 묶어 상대적인 이득(advantage)을 계산하고 이를 통해 정책을 최적화하는 강화학습 기법입니다.
- View-Consistent Group Rollout: 고정된 스크린샷 대신, 동일한 target을 포함하는 다양한 crop 뷰들을 생성하여 비교 그룹을 구성함으로써, 기하학적 변화에 강건한 학습을 유도하는 방법론입니다.
- Self-Verified Cross-View Anchor: 모델이 생성한 rollout 중 성공적인 사례가 있을 때만 oracle 좌표를 보조 신호로 활성화하여, 불필요한 과적합이나 데이터 왜곡 없이 학습을 안정화하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 GRPO를 활용한 GUI Grounding 학습에서 발생하는 보상 퇴화(reward degeneracy) 문제를 해결하는 데 집중합니다. 고정된 단일 스크린샷 환경에서 학습할 경우, 모델의 결과물이 모두 실패하거나 모두 성공하는 경우가 빈번하여 그룹 내 상대적 이득(advantage)이 사라지는 현상이 발생합니다 [Figure 1]. 이러한 'All-zero' 또는 'All-one' 퇴화는 학습 신호를 무력화하며, 특히 작은 요소가 밀집된 GUI 인터페이스에서 정교한 좌표 예측을 어렵게 만듭니다. 저자들은 단순한 보상 설계의 변화를 넘어, 기하학적으로 변형된 semantically equivalent한 입력들을 통해 비교 그룹의 다양성을 확보해야 할 필요성을 제기합니다.
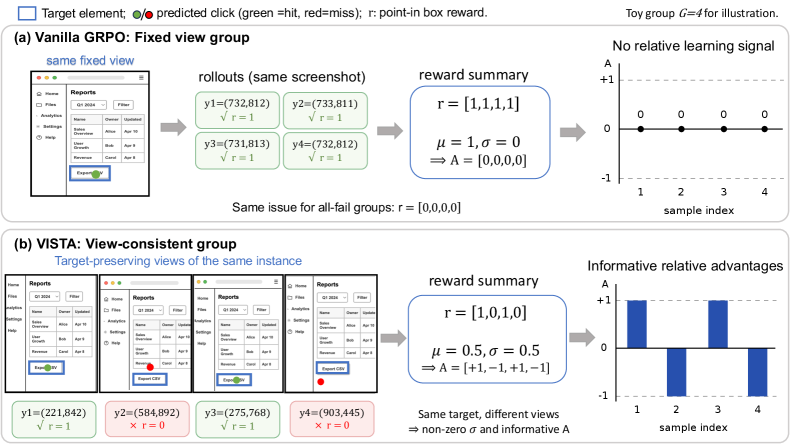
Figure 1 — VISTA의 동기: 그룹 구성 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VISTA (View-Consistent Self-Verified Training) 프레임워크를 제안하여 View-Consistent Group Rollout과 Self-Verified Cross-View Anchoring을 통합합니다 [Figure 2]. View-Consistent Group Rollout은 target을 유지하는 다수의 crop 이미지를 생성하고, 이들 간의 성과를 비교하여 모델의 위치 추론 능력을 강화합니다. Self-Verified Cross-View Anchor는 모델이 스스로 최대 보상을 얻은 그룹에 한해서만 oracle 데이터를 반영함으로써, 강제적인 imitation learning으로의 변질을 방지하고 학습의 안정성을 유지합니다 [Figure 2]. 실험 결과, VISTA는 ScreenSpot-Pro 벤치마크에서 Qwen3-VL-4B/8B/30B-A3B 모델 기준으로 기존 대비 상당한 정확도 향상을 달성했습니다. 구체적으로 ScreenSpot-Pro에서 4B/8B/30B-A3B 모델은 각각 63.4/65.8/67.0의 정확도를 기록하며 기존 성능인 55.5/52.7/53.7을 대폭 상회했습니다 [Table 1]. 또한, 학습 과정에서 퇴화 그룹 비율을 낮추고, Informative group 비율을 약 5% 미만에서 20% 수준으로 크게 개선하는 정량적 성과를 입증했습니다 [Figure 3].
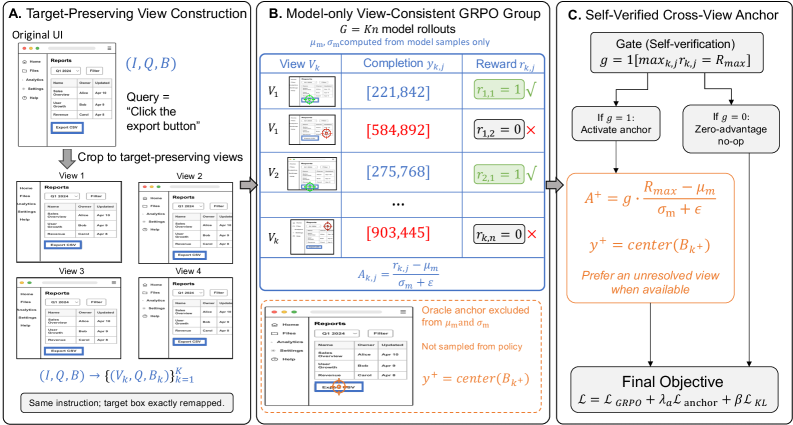
Figure 2 — VISTA의 전체 프레임워크 아키텍처
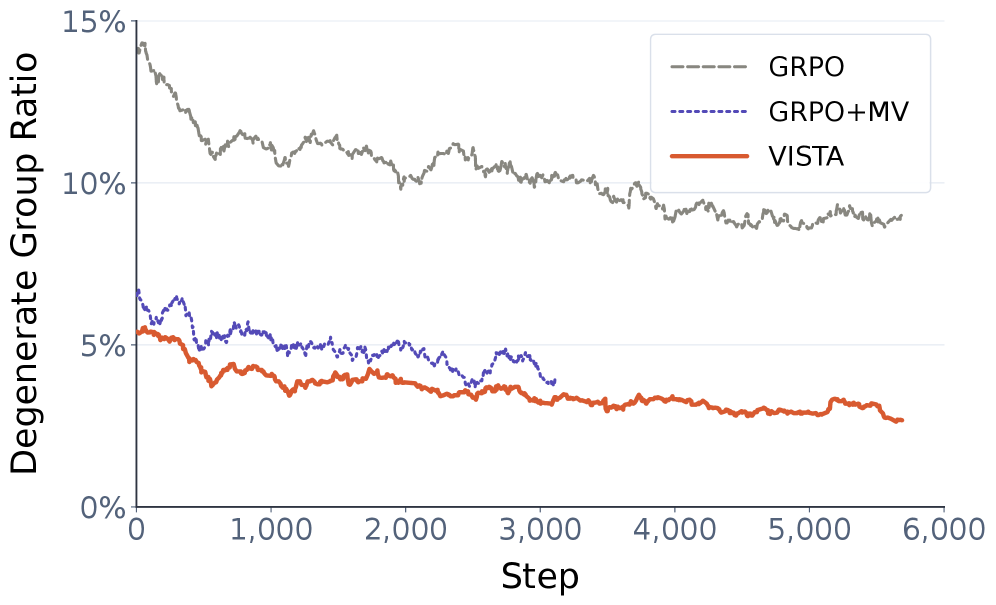
Figure 3 — 학습 중 Informative group 비율 변화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 GUI Grounding 환경에서 GRPO의 효율성을 극대화하기 위한 새로운 프레임워크인 VISTA를 성공적으로 제시했습니다. VISTA는 데이터 증강을 넘어 뷰 기반의 그룹 구성과 조건부 보조 신호 주입을 통해 RL 학습의 신뢰성과 강건성을 입증했습니다. 이 기법은 향후 다양한 VLM 기반 에이전트 모델의 강화학습 파이프라인에서 필수적인 기술적 토대가 될 것으로 예상됩니다. 특히, 고해상도 인터페이스 내에서의 미세한 타겟팅 문제를 해결함으로써 실제 사용자 환경에서의 에이전트 신뢰도를 높이는 데 크게 기여할 것입니다.
Part 2: 중요 Figure 정보

Figure 1 — VISTA의 동기: 그룹 구성 방식 비교

Figure 2 — VISTA의 전체 프레임워크 아키텍처

Figure 3 — 학습 중 Informative group 비율 변화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- [논문리뷰] Learning User Simulators with Turing Rewards
- [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- [논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Review 의 다른글
- 이전글 [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
- 현재글 : [논문리뷰] VISTA: View-Consistent Self-Verified Training for GUI Grounding
- 다음글 [논문리뷰] WaveDiT: Distribution-Aware Wavelet Flow Matching for Efficient 3D Brain MRI Synthesis
댓글