[논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zicheng Zhang, Haoran Li, Jiaxing Wang, Guoqiang Gong, Anqi Li, Yudong Hu, Ting Xiong, Yurong Gao, Junxing Hu, Zhida Jiang, Yifeng Zhang, Pengzhang Liu, Qixia Jiang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Scaling Factor ($\alpha$): LoRA 아키텍처에서 저랭크(Low-rank) 가중치 업데이트의 크기를 조절하는 하이퍼파라미터로, 본 논문에서는 최적화 과정의 핵심 동력으로 정의됨.
- Signal-Drift Framework: LoRA의 최적화 동역학을 작업 관련 신호(Task-aligned signal)와 bilinear 아키텍처에서 기인한 구조적 드리프트(Structural drift)로 분해하여 분석하는 이론적 프레임워크.
- Spectral Suppression: LoRA의 저랭크 파라미터화가 Hessian 행렬의 스펙트럼을 압축하여 최적화 환경(Landscape)을 평탄하게 만드는 현상.
- LoRA-$\alpha$: 저자들이 제안하는 최소주의적 프레임워크로, $\alpha$를 원칙적인(Principled) 범위로 복원하고 표준적인 FFT(Full Fine-Tuning) learning rate를 사용하게 함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LoRA 학습 시 하이퍼파라미터인 scaling factor $\alpha$의 역할이 체계적으로 연구되지 않았으며, 단순히 learning rate($\eta$)의 보조적 수단으로만 간주되어 온 점을 지적합니다. 기존 연구들은 LoRA가 FFT보다 훨씬 큰 learning rate를 필요로 한다는 점을 관찰했으나, 이러한 현상이 $\alpha$의 부적절한 스케일링에서 기인한다는 사실을 간과했습니다. 저자들은 기존의 랭크 기반 휴리스틱(예: $\alpha=r$)이 LoRA의 최적화 잠재력을 제대로 활용하지 못하게 제한하고 있다고 분석합니다. 따라서 본 연구는 $\alpha$가 단순히 step size를 조절하는 $\eta$의 대안이 아니라, 최적화 환경 자체를 재구조화하는 핵심 요소임을 밝히고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Signal-Drift framework를 통해 $\alpha$가 작업 신호(Signal)를 증폭시키는 반면, $\eta$는 신호와 비효율적인 드리프트(Drift)를 동시에 증폭시킨다는 원리적 차이를 규명합니다. 제안된 LoRA-$\alpha$ 프로토콜은 $\alpha$를 $\alpha_{\text{base}} = C\sqrt{r}$ ($C \gg 1$)와 같은 서브리니어(Sublinear) 법칙에 따라 대폭 확장하여, standard FFT learning rate를 그대로 사용하면서도 더 깊은 수렴을 유도합니다. 실험 결과, **LoRA-$\alpha$**는 GLUE, Llama-2/3, MMEB 등 다양한 벤치마크에서 기존 LoRA 및 최신 기법들(RsLoRA, PiSSA, LoRAM 등) 대비 일관되게 우수한 성능을 기록했습니다. 특히, 12B 규모의 Flux.1 모델 및 reasoning 기반 RL 작업(Table 5)에서 **LoRA-$\alpha$**는 learning rate 튜닝의 필요성을 제거함과 동시에 학습 안정성과 최종 성능을 대폭 향상시켰습니다. 이 과정에서 **LoRA-$\alpha$**는 standard LoRA 대비 더 낮은 손실 함수 값(NLL)에 도달하며, 고랭크(Higher rank) 환경일수록 그 우위가 더욱 두드러짐을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 $\alpha$를 단순히 튜닝 노브로 치부하던 기존 관행을 뒤집고, 이것이 LoRA 최적화의 핵심 동력임을 이론적·실증적으로 입증합니다. 제안된 LoRA-$\alpha$ 프레임워크는 복잡한 하이퍼파라미터 탐색 과정을 간소화하고, 모든 모델과 태스크에 걸쳐 FFT 수준의 효율적인 학습을 가능하게 한다는 점에서 실용적 가치가 매우 큽니다. 본 연구의 결과는 향후 PEFT 방법론 설계 시 스케일링 법칙과 최적화 동역학을 고려하는 방향으로 학계 및 산업계의 관점을 전환할 것으로 기대됩니다.
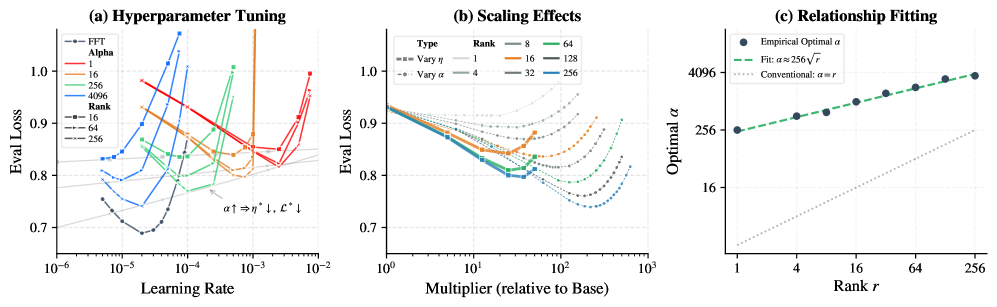
Figure 1 — LoRA 하이퍼파라미터 분석
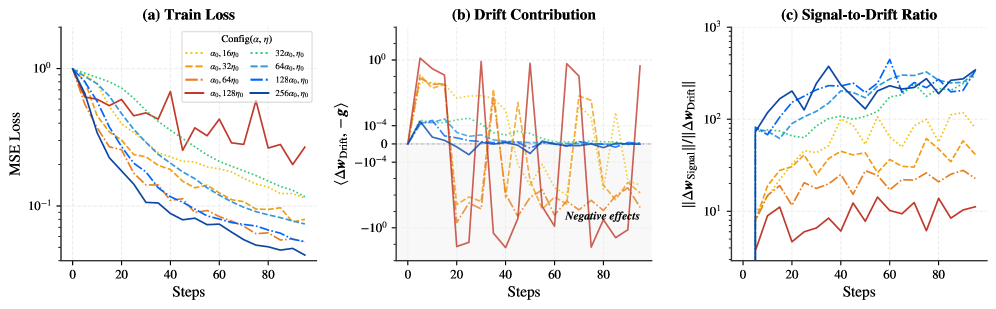
Figure 2 — 비대칭적 최적화 동역학

Figure 3 — 이미지 생성 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
- [논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- [논문리뷰] LayerRoute: Input-Conditioned Adaptive Layer Skipping via LoRA Fine-Tuning for Agentic Language Models
Review 의 다른글
- 이전글 [논문리뷰] The Arbiter Agent: Continually Monitoring Multi-Agent Conversations to Detect Emergent Misalignment
- 현재글 : [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
- 다음글 [논문리뷰] VISTA: View-Consistent Self-Verified Training for GUI Grounding
댓글