[논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mind Lab, Song Cao, Vic Cao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PEFT (Parameter-Efficient Fine-Tuning): 대규모 사전 학습 모델의 파라미터 대부분을 고정한 채 소수의 파라미터만을 학습시켜 효율적으로 최적화하는 기법군입니다.
- LoRA (Low-Rank Adaptation): 가중치 행렬에 저랭크(low-rank) 행렬을 주입하여 학습 가능한 파라미터 수를 획기적으로 줄이는 대표적인 PEFT 기법입니다.
- Scale Up/Down/Out: 본 논문이 제시한 PEFT의 3대 확장 축으로, 각각 강한 공유 기반 모델 활용(Scale Up), 적응형 상태의 경량화(Scale Down), 지속적인 개인별 모델의 대규모 운용(Scale Out)을 의미합니다.
- MinT (Managed Infrastructure): 대규모 학습 및 서빙을 지원하는 인프라 솔루션으로, 수백만 개의 어댑터를 관리, 실행, 복구하기 위한 시스템 프레임워크입니다.
- δ-mem (Delta Memory): 고정된 가중치 대신 토큰별 학습 가능한 온라인 메모리 상태를 유지하여 히스토리 기반의 미세 조정을 수행하는 stateful adapter입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 범용적인 기초 모델을 넘어 수백만 명의 개인별 요구사항을 지속적으로 반영할 수 있는 '개인화된 모델(Personal Models)'의 확장성 문제를 해결하고자 합니다. 기존의 방식은 모델을 개별적으로 전체 파인튜닝하거나 프롬프트에 의존하여 장기적인 사용자 연속성을 보장하지 못하며, 대규모 모델을 다수의 사용자에 적용하기에는 연산 비용과 메모리 제약이 매우 큽니다. 저자들은 PEFT가 단순한 비용 절감 수단을 넘어, 고정된 대규모 기반 모델 위에 개인별 행동 특성을 저장하는 지속적인 '상태(state)'로서 기능해야 한다고 주장합니다. 이러한 구조를 뒷받침하기 위해 저자들은 3가지 확장 축(Scale Up, Scale Down, Scale Out)의 유기적 통합이 필요함을 역설합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 대규모 모델의 잠재력을 최대한 활용하면서도 개인화 학습의 비용을 최소화하는 3단계 아키텍처를 제안합니다. 우선, Scale Up을 위해 Trillion-scale MoE 기반 모델에 LoRA를 적용한 강화학습(RL)을 수행하며, 이때 발생할 수 있는 학습-추론 간 불일치(Training-Inference Mismatch)를 Router Replay(R3) 기법으로 해결합니다. Scale Down 단계에서는 OLoRA-tail과 같은 기법을 통해 어댑터 초기화를 최적화하여 Rank가 매우 낮은 상황에서도 학습 안정성을 확보합니다. 마지막으로 Scale Out을 구현하는 MinT 인프라를 통해 수백만 개의 어댑터를 체계적으로 관리하며, δ-mem을 사용하여 상태 기반의 개인화 기억 기능을 제공합니다. 핵심 실험 결과, OLoRA-tail은 Rank 1 상황에서도 LoRA 대비 성능 저하 없이 학습 안정성을 높였으며, 모델 개수(k)를 늘림에 따라 모델 간 협업(Collaboration)을 통해 AIME24 정확도가 0.3644(k=1)에서 0.4867(k=198)까지 상승하는 집단 지성 효과를 확인하였습니다 [Figure 24]. 또한, MinT 시스템을 통해 Rank-32 어댑터는 전체 체크포인트 대비 30배 이상의 저장 공간 효율을 보여주며 효율적인 서빙을 가능하게 합니다 [Table 9].

Table 9 — 어댑터 기반 핸드오프가 전체 모델 체크포인트 대비 얼마나 효율적인지 보여주는 비교 테이블
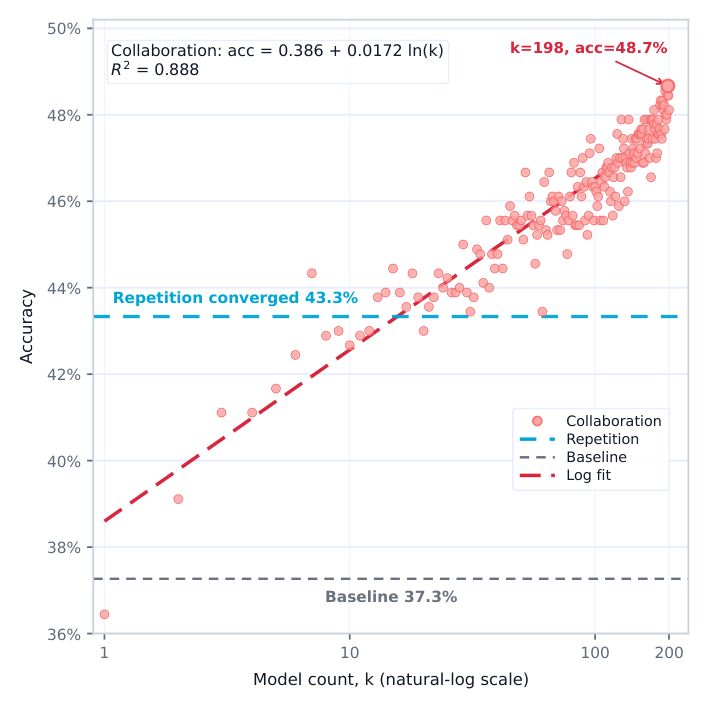
Figure 24 — 모델 개수가 증가함에 따라 집단 지성(Collaboration) 효과가 어떻게 성능 향상을 가져오는지 보여주는 그래프
4. Conclusion & Impact (결론 및 시사점)
본 연구는 PEFT가 단순히 파인튜닝의 저렴한 대안이 아니라, 대규모 기반 모델을 기반으로 수백만 개의 개인화된 모델을 지속적으로 관리하고 운용할 수 있는 핵심 시스템 구조임을 입증하였습니다. 이 연구는 AI 모델이 단일한 중앙 집권적 어시스턴트에서 사용자의 이력과 행동 양식을 반영하는 개인별 에이전트로 진화하는 방향성을 제시합니다. 특히 모델 인프라의 복잡성을 관리 가능한 수준으로 낮춘 것은 향후 거대 모델 기반의 개인화 서비스 생태계 구축에 중대한 이정표가 될 것입니다.
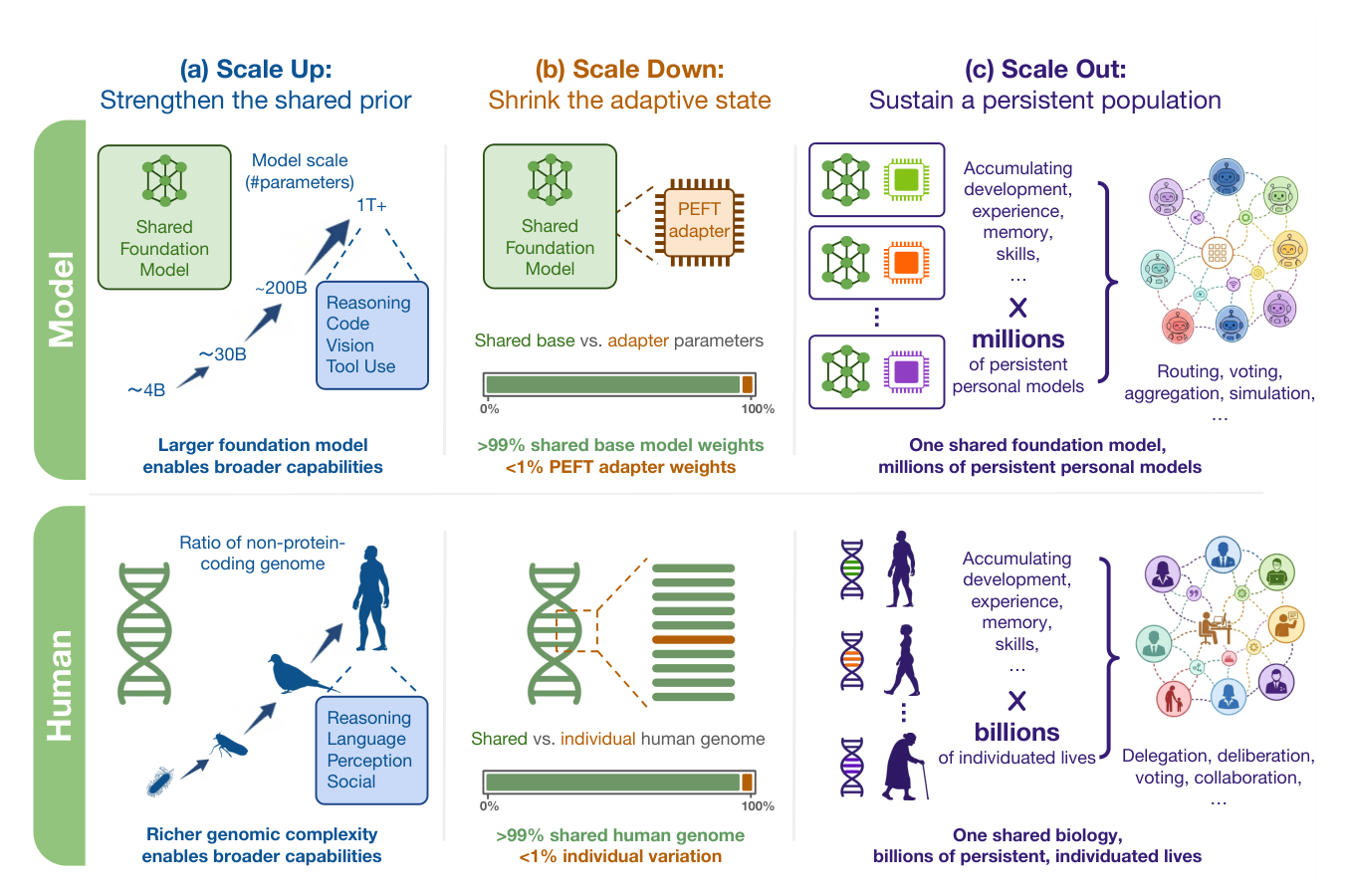
Figure 1 — PEFT 확장 3대 축인 Scale Up, Scale Down, Scale Out을 설명하는 핵심 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OpenThoughts-Agent: Data Recipes for Agentic Models
- [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- [논문리뷰] How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
- [논문리뷰] Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
- 현재글 : [논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- 다음글 [논문리뷰] OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
댓글