[논문리뷰] OpenThoughts-Agent: Data Recipes for Agentic Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Negin Raoof, Richard Zhuang, Marianna Nezhurina, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Models: 단순히 질문에 답하는 것을 넘어 도구(Tool)를 사용하고 복잡한 장기적 추론(Long-horizon reasoning)을 수행하여 실제 컴퓨터 환경에서 작업을 수행하는 AI 모델.
- SFT Data Pipeline: 모델의 에이전트 역량을 강화하기 위해 (Task, Trajectory) 데이터를 수집, 생성, 필터링 및 혼합하는 일련의 자동화된 프로세스.
- Terminal-Bench 2.0: 소프트웨어 엔지니어링, 보안, 시스템 관리 등 다양한 도메인의 에이전트 역량을 평가하기 위해 설계된 벤치마크.
- RLOO (Reinforcement Learning with Leave-One-Out): 에이전트의 보상 최적화를 위해 사용된 강화학습 알고리즘으로, 특정 에피소드의 보상을 추정할 때 나머지 에피소드들의 평균을 기반으로 분산을 줄이는 기법.
- Compute-Controlled Ablation: 컴퓨팅 자원을 고정하거나 동일한 토큰 예산을 사용하여 데이터 전략 간의 실질적인 성능 차이를 공정하게 비교하는 실험 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 에이전트용 모델을 학습시키기 위한 데이터 큐레이션(Data Curation) 방법론이 공개적으로 거의 알려져 있지 않은 문제를 해결하고자 한다. 기존 연구들은 대개 특정 벤치마크 하나에만 집중하거나 학습 데이터에 대한 구체적인 정보를 제공하지 않아, 다양한 에이전트 작업에서 범용적으로 우수한 성능을 내는 모델을 학습시키는 방법이 불분명하다. 이를 위해 저자들은 에이전트 학습을 위한 포괄적인 데이터 파이프라인을 설계하고 체계적인 100회 이상의 ablation 실험을 수행한다 [Figure 2]. 본 연구는 데이터 소스의 다양성과 품질이 에이전트의 실질적인 도구 사용 및 추론 능력에 미치는 영향을 규명하는 데 목적이 있다.
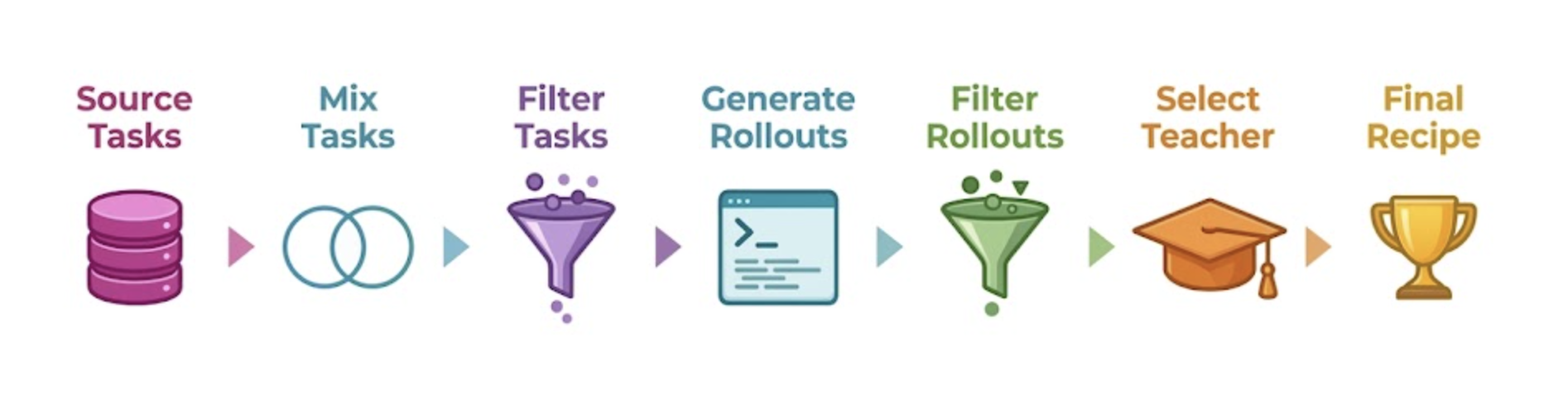
Figure 2 — 6단계 SFT 데이터 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 6단계의 SFT(Supervised Fine-Tuning) 데이터 파이프라인을 통해 OpenThoughts-Agent 데이터셋을 구축한다. 핵심 방법론으로 데이터 혼합(Mixing) 전략에서 상위 4개 데이터 소스를 결합하는 것이 단일 소스보다 범용성이 뛰어남을 확인하였으며, 5턴 이상의 에이전트 궤적을 보존하는 필터링 기법이 모델의 성능 향상에 크게 기여함을 입증했다 [Table 1]. 또한, 단순히 데이터를 늘리는 것보다 synthetic task augmentation을 통해 태스크 다양성을 확보하는 것이 학습 데이터 스케일링에서 훨씬 효과적임을 확인하였다 [Figure 3]. 최종적으로 Qwen3-32B 모델을 100K 데이터셋으로 파인튜닝한 모델은 7개 에이전트 벤치마크에서 평균 44.8%의 정확도를 기록하며, 기존 오픈소스 모델인 Nemotron-Terminal-32B(40.9%)를 상회하는 SotA 성능을 달성하였다. 추가적으로 8B 모델 규모에서 수행한 RL 실험을 통해, 특정 소스(pymethods2test)가 에이전트의 탐색 정책을 더 효율적으로 학습시킴을 보였다.
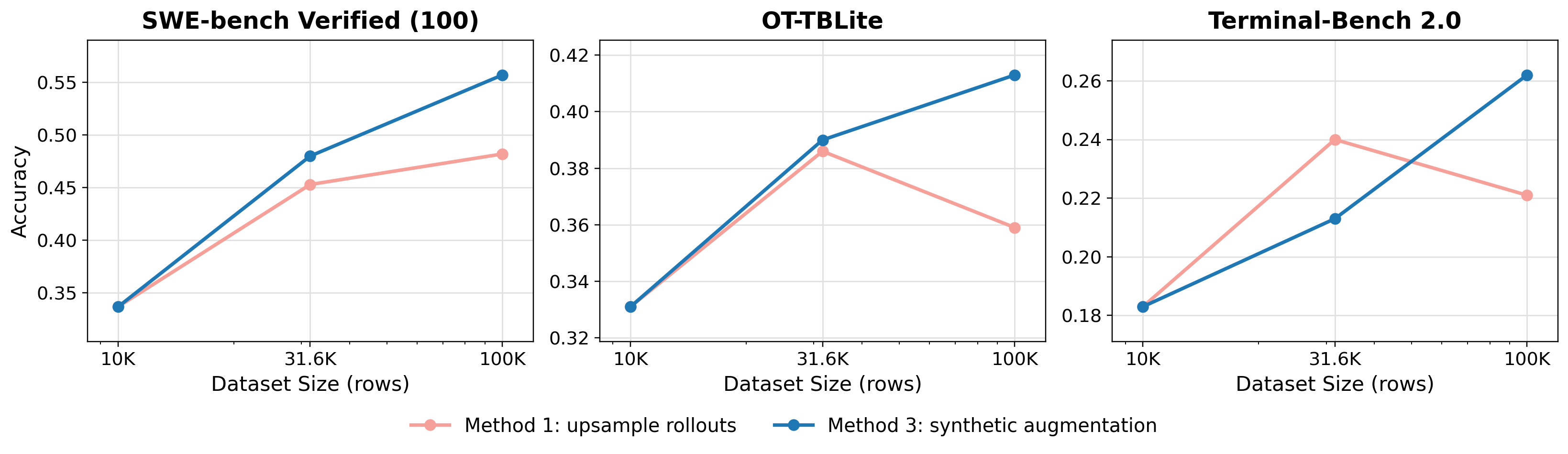
Figure 3 — 데이터 스케일링 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 에이전트 모델의 학습을 위한 데이터 큐레이션 전략을 체계화하고 공개함으로써 오픈 AI 생태계에 중요한 이정표를 제시한다. 실험을 통해 에이전트의 성능이 데이터 파이프라인의 설계, 특히 데이터 혼합과 태스크 증강 기법에 결정적으로 의존함을 증명하였다. 이 결과는 향후 연구자들이 더 효율적인 에이전트 모델을 개발하는 데 필요한 공학적 가이드라인을 제공할 것이다. 또한, 제안된 데이터셋과 파이프라인은 복잡한 환경에서 범용적으로 작동하는 에이전트 연구를 가속화하는 핵심 기반이 될 것으로 기대된다.
Figure 4 — 최종 100K SFT 데이터 흐름
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] How Post-Training Shapes Biological Reasoning Models
- [논문리뷰] FastContext: Training Efficient Repository Explorer for Coding Agents
- [논문리뷰] SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
- [논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- [논문리뷰] DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
Review 의 다른글
- 이전글 [논문리뷰] NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
- 현재글 : [논문리뷰] OpenThoughts-Agent: Data Recipes for Agentic Models
- 다음글 [논문리뷰] QG-MIL: A Gated Transformer Aggregator for Domain-Agnostic Multiple Instance Learning in Medical Imaging
댓글