[논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
링크: 논문 PDF로 바로 열기
메타데이터
저자: Prannay Hebbar, Yogendra Manawat, Samuel Verboomen, Alesia Ivanova, Selvam Palanimalai, Kunal Bhatia, Vignesh Baskaran, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SIA (Self Improving AI): Feedback-Agent가 Task-specific agent의 Harness(Scaffold)와 Model Weights를 모두 반복적으로 업데이트하여 성능을 최적화하는 통합 루프 프레임워크.
- Harness (Scaffold): 모델 가중치 외부에서 에이전트의 작동을 정의하는 요소로, System prompt, Tool-dispatch logic, Retry policy, Answer-extraction 코드 등을 포함함.
- Feedback-Agent: 이전 세대의 실행 Trajectory와 성능 지표를 분석하여, 다음 단계로 Harness update를 수행할지 아니면 Weight update를 수행할지 결정하는 메타 에이전트.
- Weight Updates: LoRA 등을 사용하여 특정 태스크의 피드백을 기반으로 모델 내부 가중치를 미세 조정함으로써, 프롬프트나 스캐폴드만으로는 도달할 수 없는 도메인 특화 지식을 내재화하는 과정.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 AI 자기 개선 연구가 Harness(scaffold) 개선과 Test-time training(weight updates)이라는 두 가지 고립된 사일로(silo)로 나뉘어 있는 한계를 해결하고자 한다 [Figure 2]. 기존의 Harness 업데이트 연구는 모델의 가중치를 고정하여 도메인 특화 추론 능력을 극대화하는 데 한계가 있으며, Test-time training 연구는 복잡한 에이전트 환경의 구조적 적응성을 고려하지 못한다는 문제점이 있다. 따라서 저자들은 이 두 가지 레버를 통합하여 협력적으로 진화시키는 시스템이 각 독립적 방식의 성능 상한선을 돌파할 수 있음을 입증하고자 한다.
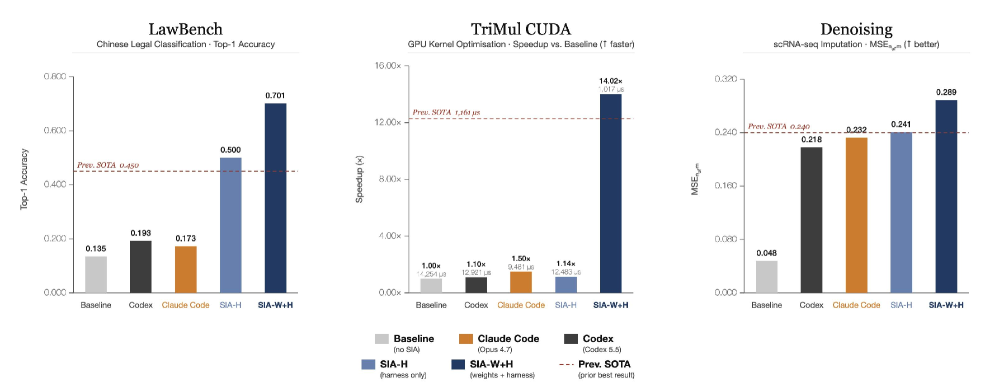
Figure 2 — SIA의 두 레버와 루프 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Feedback-Agent가 Harness update와 Weight update를 동적으로 교차 선택하는 순환 프레임워크인 SIA를 제안한다 [Figure 3]. Harness update 단계에서는 모델 가중치를 고정하고 스캐폴드를 재작성하여 시스템 수준의 구조적 개선을 도모하며, Weight update 단계에서는 PPO, GRPO 또는 Entropic advantage weighting 등의 기법을 선택적으로 적용하여 모델 가중치를 최적화한다 [Figure 2]. 실험 결과, SIA-W+H는 세 가지 도메인(법률 분류, CUDA 커널 최적화, 유전자 데이터 디노이징) 모두에서 Harness-only 방식보다 우수한 성능을 보였다. 특히 LawBench에서 이전 SOTA 대비 25.1% 향상된 정확도를 기록했으며, TriMul CUDA 커널 최적화에서는 12.4% 더 빠른 실행 속도(1,017 $\mu$s), 디노이징 작업에서는 20.4%의 성능 개선을 달성하였다 [Figure 4, Figure 5, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Harness 업데이트와 Weight 업데이트를 통합한 SIA 루프가 각각의 개별 방식이 가진 성능적 한계를 성공적으로 극복함을 증명하였다. 연구 결과는 Harness 업데이트가 에이전트의 탐색과 실행 방식을 효율화하고, Weight 업데이트가 도메인 특화 지식을 모델 내부에 직접 내재화함으로써 상호 보완적인 시너지를 냄을 시사한다. 이 연구는 AI 에이전트가 인간의 지속적인 개입 없이도 시스템 구조와 모델 매개변수를 동시에 개선하여 복잡한 태스크를 수행할 수 있는 자율적 자기 개선 루프의 가능성을 제시하였다.
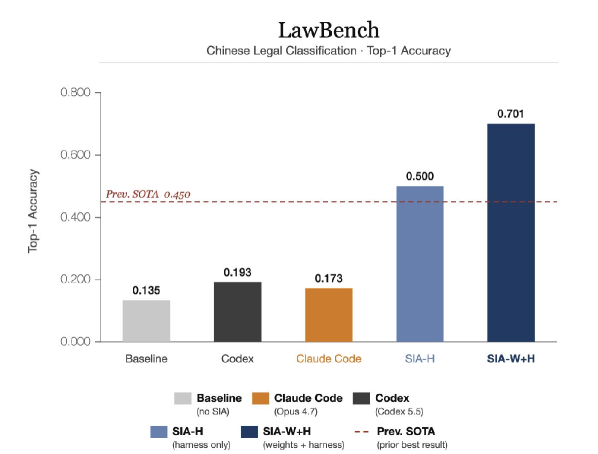
Figure 4 — LawBench 성능 비교 결과
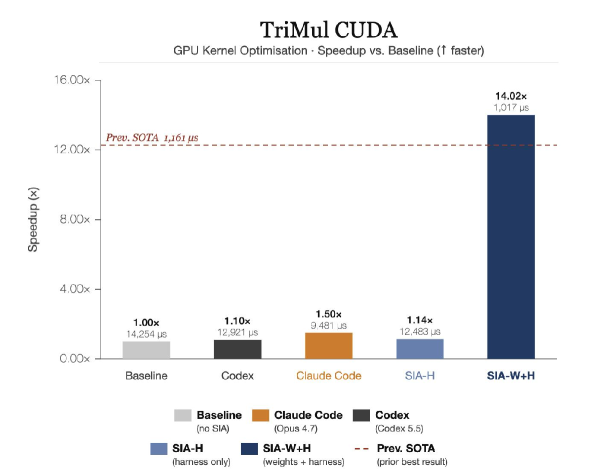
Figure 5 — TriMul CUDA 최적화 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
- [논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- [논문리뷰] ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
- [논문리뷰] TTCS: Test-Time Curriculum Synthesis for Self-Evolving
- [논문리뷰] Reinforcement Learning via Self-Distillation
Review 의 다른글
- 이전글 [논문리뷰] Robots Need More than VLA and World Models
- 현재글 : [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- 다음글 [논문리뷰] SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
댓글