[논문리뷰] SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jianshu Zhang, Yijiang Li, Huifeixin Chen, Haoran Lu, Letian Xue, Bingyang Wang, Han Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- SpaceNum: VLM의 공간적 수치 이해도를 평가하기 위해 제안된 통합 프레임워크로, Dynamic Transition(공간 탐색)과 Static Layout(공간 추론) 환경을 모두 포함합니다.
- Num2Space & Space2Num: 공간 수치 이해를 측정하는 양방향 태스크입니다. Num2Space는 수치 입력으로부터 공간적 결과를 도출하고, Space2Num은 시각적 공간 구조로부터 적절한 수치를 추론하는 능력을 평가합니다.
- Metric Grounding: VLM이 생성하는 수치값(예: 회전 각도, 좌표)이 단순히 추측이 아니라, 실제 시각적 공간 특성과 물리적으로 연결되어 있는지 여부를 의미하는 핵심 지표입니다.
- Cognitive Map: 정적 공간 추론 환경에서 객체 간의 상대적 위치를 표현하는 내부 지도로, 공간적 관계를 구조화하여 추론 성능을 향상시키는 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VLM이 embodied 환경에서 생성하는 수치적 출력값(예: action magnitude, spatial coordinate)이 실제 공간 정보에 기반하고 있는지에 대해 의문을 제기합니다. 기존 연구들은 단순히 공간적 추론 성능만을 측정했을 뿐, 수치적 값 자체가 공간의 물리적 속성과 진정으로 연결(grounded)되어 있는지에 대한 체계적인 분석이 부족했습니다. 저자들은 이러한 한계를 극복하기 위해 SpaceNum을 통해 시각적 공간 구조와 언어적 수치 표현 간의 매핑을 정밀하게 평가하고자 합니다 [Figure 1]. 이 연구는 VLM이 공간 탐색과 추론 상황에서 단순히 통계적 확률에 의존하는지, 아니면 실질적인 공간 수치 이해를 갖추었는지를 밝히는 것을 목표로 합니다.
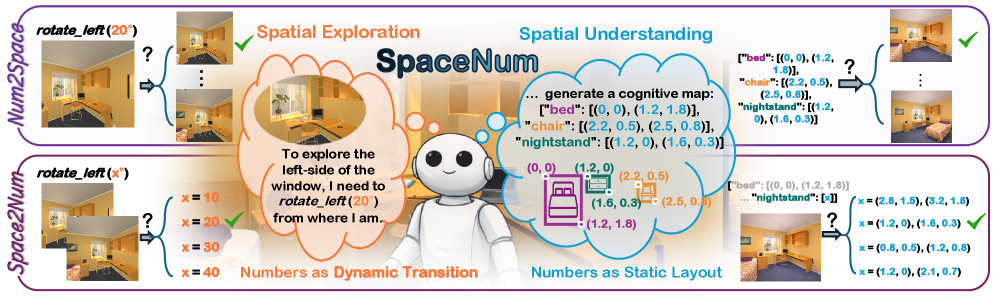
Figure 1 — SpaceNum의 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 18개의 최신 VLM 모델을 대상으로 두 가지 공간 시나리오에서 Num2Space 및 Space2Num 성능을 평가하는 프레임워크를 제안합니다. 실험 결과, 대부분의 모델이 Random Guess(평균 30.0%) 수준의 성능을 보이거나 그보다 낮은 성능을 기록하여 공간 수치에 대한 심층적 이해가 부족함이 확인되었습니다 [Table 2]. 특히 모델 크기가 커짐에 따라 Dynamic Transition 환경에서 오류의 크기(magnitude)는 점차 줄어드는 경향을 보이나, Static Layout에서는 위치와 크기 정보가 결합하여 발생하는 구조적 오류가 지배적임을 분석했습니다 [Figure 3]. 또한 Reasoning Trace 분석을 통해 모델들이 미세한 비교 대신 표면적인 공간 단서(coarse spatial cues)에 의존하고 있음을 밝혔으며, 시각적 정보 차단(blind test)을 통해 모델들이 Static Layout 상황에서 언어적 사전 지식에 더 의존함을 입증했습니다 [Figure 4]. 마지막으로, 레이아웃을 구조적인 시각적 추상화로 변환했을 때 공간 이해도가 크게 향상됨을 확인하였으며, 이를 기반으로 최적의 데이터 혼합 전략을 통해 공간 추론 능력을 부분적으로 전이(transfer)시킬 수 있음을 증명했습니다 [Figure 6, Figure 7].
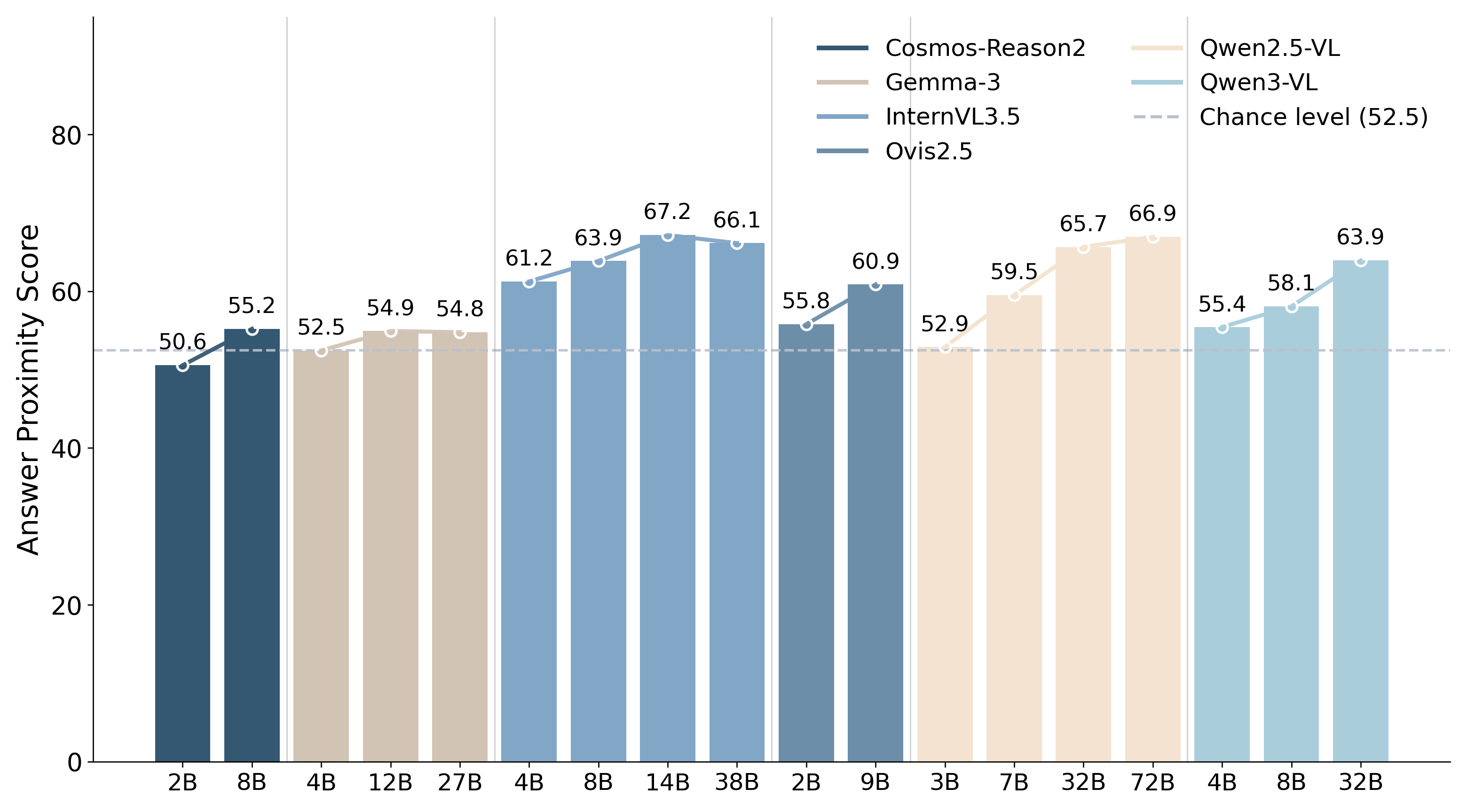
Figure 3 — 모델 오류의 구조적 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLM이 공간적 수치 표현을 생성할 때, 실제 물리적 공간에 대한 심층적인 grounding 보다는 shallow한 시각적/언어적 통계에 의존하고 있다는 결론을 도출합니다. 연구진이 제안한 SpaceNum은 향후 VLM의 물리적 임베디드 성능을 객관적으로 평가하는 표준 벤치마크로 활용될 수 있습니다. 본 연구의 결과는 모델의 공간적 추론 능력을 개선하기 위해 단순히 Reasoning Trace를 생성하는 것보다 시각적 정보를 구조적으로 추상화하고, 공간과 수치의 관계를 명확히 학습시키는 튜닝 전략이 필수적임을 시사합니다. 이는 향후 로봇 공학 및 embodied AI 분야에서 VLM의 실질적인 공간 제어 능력을 향상시키는 데 기여할 것으로 기대됩니다.
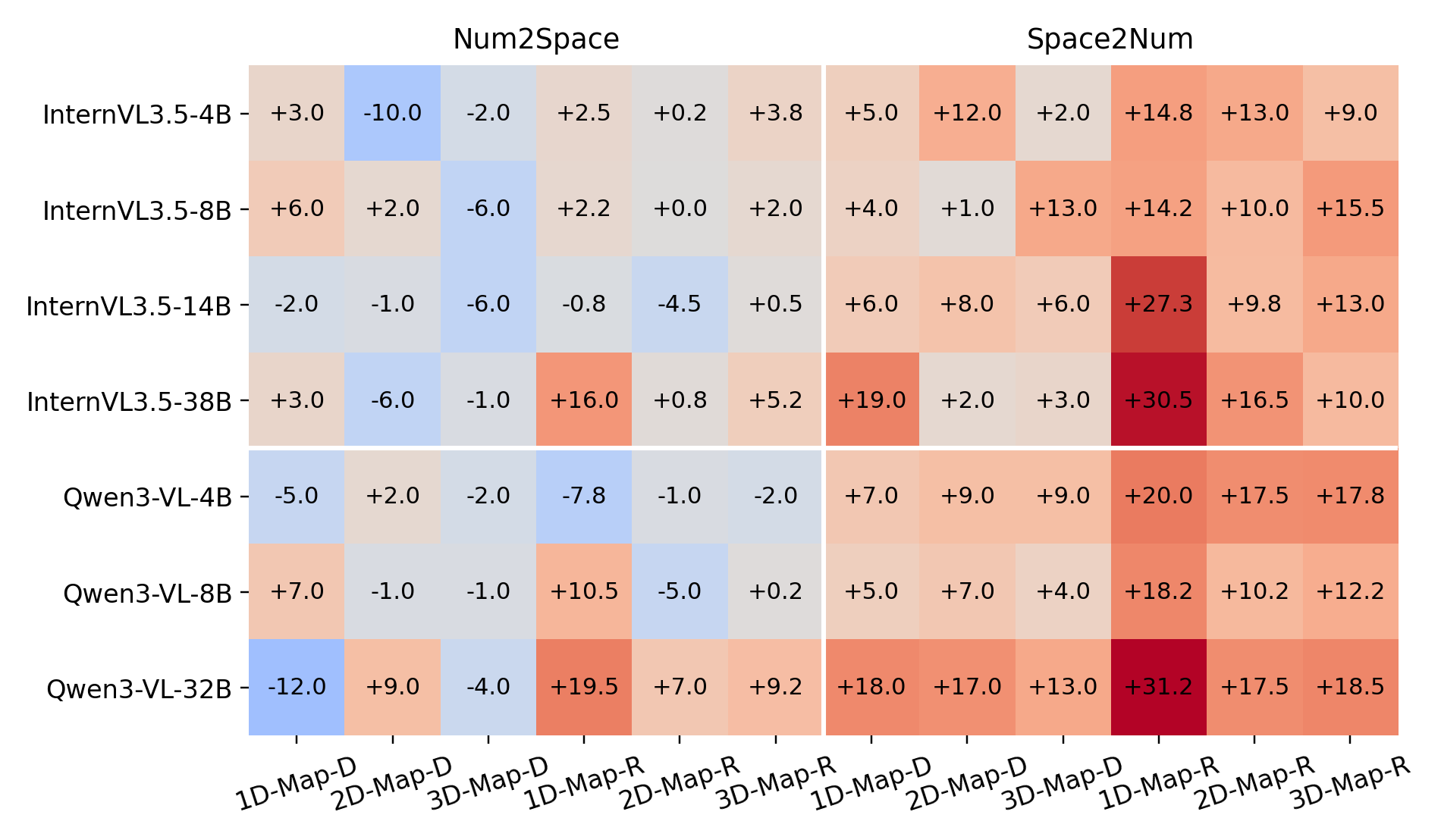
Figure 6 — 레이아웃 시각적 추상화 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
- [논문리뷰] Unlocking Dense Metric Depth Estimation in VLMs
- [논문리뷰] SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
- [논문리뷰] Make Geometry Matter for Spatial Reasoning
Review 의 다른글
- 이전글 [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- 현재글 : [논문리뷰] SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
- 다음글 [논문리뷰] SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
댓글