[논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chenming Zhu, Jingli Lin, Yilin Long, Peizhou Cao, Tai Wang, Jiangmiao Pang, Xihui Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Astra: 시각적 공간 추론(Visual Spatial Reasoning)을 위해 World Simulator와 에이전트 정책을 통합한 프레임워크입니다.
- Astra-VL: Qwen3-VL을 기반으로 구축된 에이전트 모델로, 강화학습(RL)을 통해 적절한 시점에 시뮬레이터를 호출하고 관측 정보를 추론에 통합하도록 학습됩니다.
- Astra-WM: Bagel을 기반으로 한 World Simulator로, 카메라 움직임 명령에 따라 시각적으로 일관된 새로운 시점의 관측을 생성합니다.
- View Consistency Tuning: 생성된 이미지가 요청된 카메라 움직임을 따르고 장면의 레이아웃과 콘텐츠를 유지하도록 Astra-WM을 미세 조정하는 기술적 프로세스입니다.
- MMSI-Bench: 다중 시점 공간 추론 능력을 평가하기 위한 1,000개의 예제로 구성된 표준 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 VLM들은 관측된 이미지에 제한되어 있어 보이지 않는 레이아웃을 추론하거나 시점 변화에 따른 공간적 일관성을 유지하는 데 한계를 보입니다. 특히 제한적인 일인칭 관측 환경에서는 alternative viewpoint에서 장면을 파악해야 할 필요성이 크지만, 현 모델들은 이를 능동적으로 해결하지 못합니다. 저자들은 이러한 문제를 단순히 고정된 입력을 해석하는 수준에서 벗어나, 추론 과정 중 상상력(imagination)을 통해 능동적으로 시각적 증거를 획득하는 'thinking with imagination'의 관점에서 접근합니다 [Figure 1].

Figure 1 — Astra의 추론 과정 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
Astra는 시공간적 일관성을 갖춘 Astra-WM과 에이전트 정책인 Astra-VL을 상호 보완적으로 활용합니다. 저자들은 View Consistency Tuning을 통해 Astra-WM이 카메라 움직임 명령에 대해 신뢰할 수 있는 새로운 시점의 이미지를 생성하도록 개선했습니다 [Figure 2]. 또한 Astra-VL의 학습을 위해 두 단계로 구성된 World-simulator-in-the-loop 강화학습 커리큘럼을 제안하였습니다. 첫 번째 단계는 시뮬레이터와 상호작용하는 기술을 습득시키고, 두 번째 단계에서는 시뮬레이터 호출이 실제 추론 성능 개선에 기여할 때만 사용하도록 선택적 상상력을 최적화합니다. 실험 결과, Astra는 MMSI-Bench에서 Qwen3-VL 베이스라인의 성능을 29.8에서 38.8로 대폭 개선했으며, MindCube에서도 36.8에서 42.7로 향상된 성능을 기록했습니다 [Table 1]. 특히, 에이전트 방식의 도구 사용(Agentic Tool-Use)은 강제 도구 사용 대비 불필요한 이미지 생성을 줄이고 정확도를 높이는 데 탁월함을 보였습니다 [Figure 3].
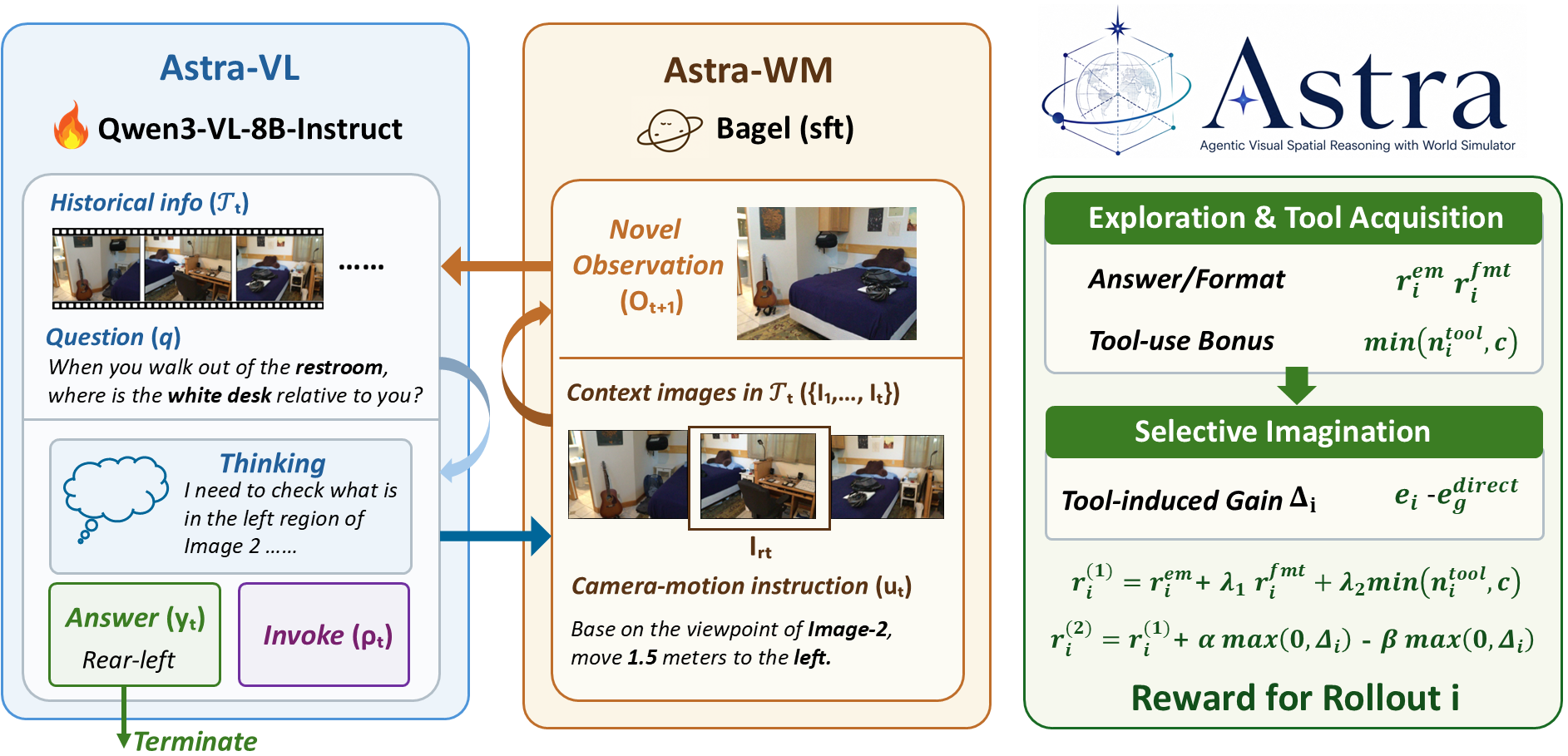
Figure 2 — Astra 모델 구조 및 학습 파이프라인
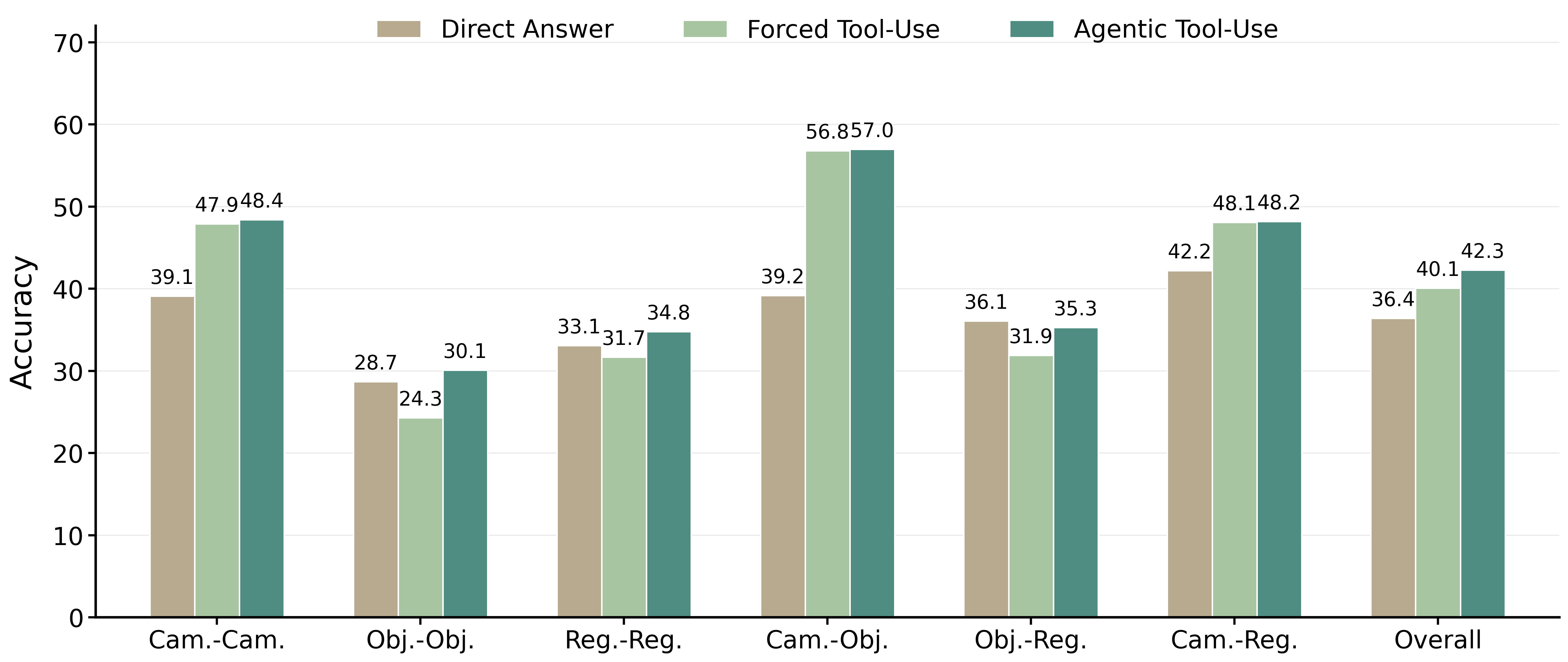
Figure 3 — MMSI-Bench 기반 워크플로우 모드 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 VLM의 공간적 추론 능력을 극대화하기 위해 단순히 시뮬레이터에 접근하는 것을 넘어, 능동적인 상상력과 에이전트 정책 학습이 필수적임을 입증했습니다. Astra 프레임워크는 공간적 신뢰성이 확보된 생성 모델과 상황에 따라 적절한 도구 사용을 결정하는 지능형 정책을 결합함으로써 차세대 공간 지능 에이전트의 설계 방향을 제시합니다. 이러한 접근은 로보틱스나 가상 환경 내 공간 분석 등 복잡한 시각적 상황 이해가 요구되는 산업 전반에 큰 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
- [논문리뷰] SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
- [논문리뷰] CodeV: Code with Images for Faithful Visual Reasoning via Tool-Aware Policy Optimization
- [논문리뷰] Visual Spatial Tuning
- [논문리뷰] Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
- 현재글 : [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- 다음글 [논문리뷰] Towards Human-Like Interactive Speech Recognition With Agentic Correction and Semantic Evaluation
댓글