[논문리뷰] Thinking with Visual Grounding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junkai Zhang, Yihe Deng, Kai-Wei Chang, Wei Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visually Grounded Thinking: 자연어 추론 과정 중에 명시적인
Point또는Box좌표를 삽입하여 시각적 근거를 모델이 직접 지시하게 만드는 추론 방식입니다. - SAM3:
Segment Anything with Concepts모델로, 본 논문에서 시각적 객체에 대한 고품질 마스크를 추출하기 위해 에이전트의 핵심 도구로 활용됩니다. - Grounding-aware Reinforcement Learning: 모델이 생성한 시각적 참조(Grounding)와 실제 이미지 내 근거 간의 일치도를 측정하여 보상을 제공하는 RL 전략입니다.
- RLE (Run-Length Encoding): SAM3가 생성한 마스크 정보를 효율적으로 압축하여 데이터셋 내에서 객체의 위치를 표현하는 형식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLM(Vision-Language Model)의 추론 과정이 언어적 논리에는 치중되어 있으나, 정작 그 논리의 근거가 되는 이미지 내 특정 영역을 명시하지 않아 검증이 어렵다는 문제를 해결하고자 합니다. 기존 연구(Baseline)들은 자연어 형태의 사고 과정을 생성할 수는 있으나, 추론의 근거를 이미지 상의 객체와 물리적으로 연결하지 못하는 한계가 있습니다 [Figure 1]. 이러한 불투명성은 모델이 정답을 맞히더라도 추론 과정이 시각적 이해에 기반했는지 보장할 수 없게 만듭니다. 따라서 추론 단계와 이미지 영역을 명확히 연결하는 Visually Grounded Thinking 프레임워크가 필요합니다 [Figure 2].
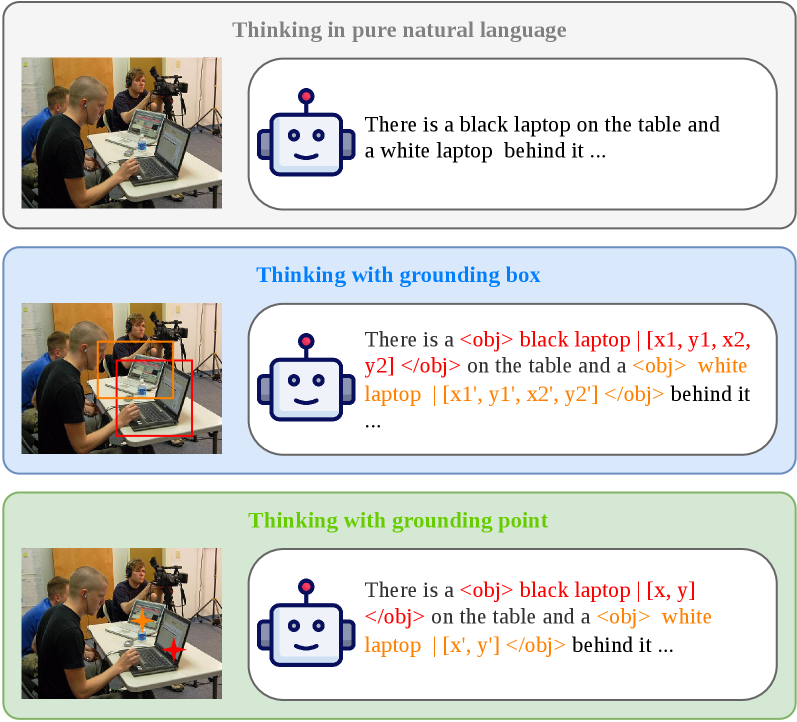
Figure 1 — 추론 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 대규모 데이터 합성 파이프라인을 구축하여 모델이 자연어 사고와 좌표 정보를 인터리빙하도록 학습시킵니다 [Figure 3]. 이 과정에서 SAM3 기반의 에이전트가 추론 과정에 필요한 객체를 추출하고 Box 또는 Point 형태의 시각적 근거를 생성합니다 [Figure 4]. 제안된 Grounding-aware RL은 생성된 참조 좌표가 정답 근거와 일치하는지를 평가하는 밀도 높은 보상(Dense Reward)을 제공합니다 [Figure 5]. 실험 결과, Gemma3-4B-IT 모델에 해당 기법을 적용했을 때 카운팅 및 공간 추론 성능이 대폭 향상되었습니다. 특히 공간 추론 벤치마크에서 4B 모델이 Gemma3-27B-IT와 대등하거나 더 우수한 성능을 기록했습니다. Point Grounding은 카운팅 작업에서, Box Grounding은 복잡한 공간 관계 이해에서 각각 강력한 성능 우위를 보임을 확인했습니다.
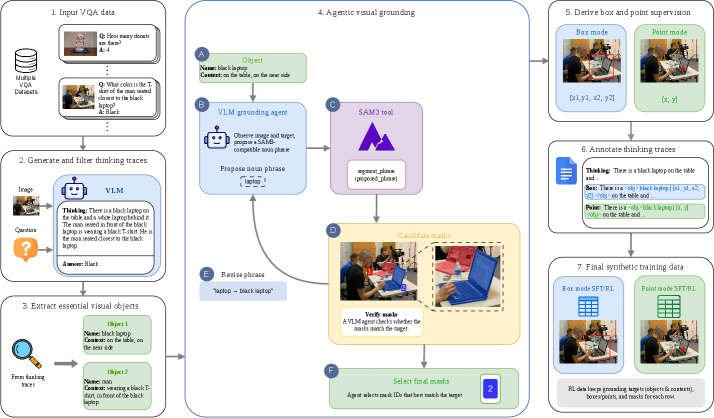
Figure 3 — 데이터 합성 파이프라인
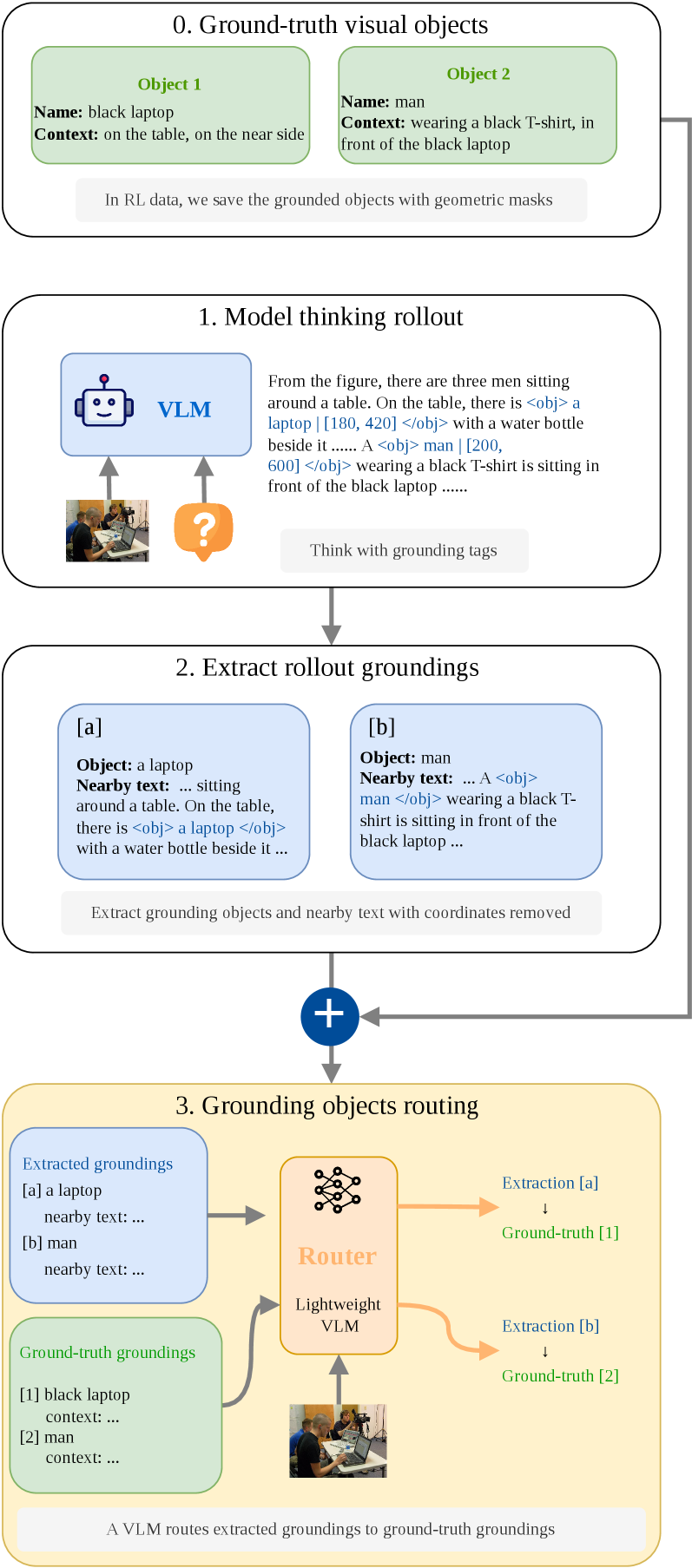
Figure 5 — 그라운딩 객체 라우터
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델의 중간 추론 과정을 시각적 증거와 명시적으로 결합하는 것이 VLM의 신뢰성과 성능을 높이는 핵심임을 입증했습니다. 제안된 Visually Grounded Thinking은 단순히 사고 과정을 길게 생성하는 것을 넘어, 검증 가능한 논리를 구축하는 방향을 제시합니다. 이러한 성과는 더 작은 파라미터 규모의 모델이 훨씬 거대한 모델의 성능을 상회할 수 있게 하며, 향후 시각적 이해와 추론이 결합된 에이전트 모델 연구에 중요한 기준점을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
- [논문리뷰] VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
- [논문리뷰] Visual Spatial Tuning
- [논문리뷰] Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- 현재글 : [논문리뷰] Thinking with Visual Grounding
- 다음글 [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
댓글