[논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruifeng Yuan, Chaohao Yuan, David Dai, Yu Rong, Hong Cheng, Hou Pong Chan, Chenghao Xiao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Retriever-aware Query Formulation: 특정 Retriever의 특성(예: dense vs. sparse)에 맞게 쿼리를 생성하여 검색 효율을 극대화하는 전략입니다.
- Structural Drift: 정보의 의도(Semantic)는 유사하더라도, Retriever가 선호하는 쿼리 표기 방식(Keyword-based vs. Natural language)이 서로 달라 발생하는 전략적 불일치를 의미합니다.
- GRPO (Group Relative Policy Optimization): Value-function critic 없이 그룹 내 보상 비교를 통해 안정적인 학습을 가능하게 하는 강화학습 알고리즘입니다.
- Branching Rollout: 다단계 검색 과정에서 중간 단계의 보상 분산을 줄이기 위해 여러 분기(branch)를 생성하여 학습 신호를 정교화하는 기법입니다.
- RE-MMD (Retrieval Environment Maximum Mean Discrepancy): 서로 다른 검색 환경 간의 쿼리 전략 차이를 측정하기 위해 도입된 통계적 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다양한 Retriever 환경에서 LLM이 범용적인 쿼리 방식만을 사용하는 것이 비효율적이라는 문제 의식에서 출발합니다. 기존의 많은 RAG 연구들은 특정 검색 엔진(예: Google)만을 상정한 단일한 Tool-call 방식으로 최적화되어 있어, 사내 문서나 특정 도메인 데이터베이스와 같은 다양한 로컬 Retriever 환경에 대한 적응력이 부족합니다. 저자들은 서로 다른 Retriever가 쿼리 스타일에 대해 근본적으로 다른 요구사항(예: 긴 서술형 문장 vs. 짧은 키워드 집합)을 가짐을 발견하였습니다. 따라서 본 연구는 LLM이 강화학습(RL)을 통해 Retriever의 특성을 학습하고 그에 맞는 최적의 쿼리 전략을 개발할 수 있는지 분석하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM 기반의 Query Rewriter 정책을 GRPO를 사용하여 최적화하는 Retriever-aware 프레임워크를 제안합니다. 다단계 검색 상황에서의 학습 불안정성을 해결하기 위해, 중간 단계의 보상을 효과적으로 할당하는 Branching Rollout 기법을 도입하였습니다 [Figure 5]. 실험 결과, 모델이 Retriever별로 서로 다른 '방언(Dialect)'을 성공적으로 학습함을 확인하였으며, 이는 RAGBench와 BEIR 데이터셋을 통해 검증되었습니다 [Table 1], [Table 2]. 특히, 14B 파라미터 규모의 모델은 인간 전문가가 고안한 전략을 능가하는 독창적인 Statement-style 쿼리 전략을 스스로 발견하여 nDCG@10 수치를 크게 향상시켰습니다 [Figure 2]. 정량적으로는 Contriever 환경에서 기존 대비 평균적인 검색 성능이 유의미하게 상승하였으며, 도메인 특화 데이터셋인 FinAgentBench에서도 일관된 성능 개선을 보여주었습니다 [Table 3]. 이러한 결과는 검색 환경의 특성에 맞춘 전략적 코드 스위칭(Code-switching)이 RAG 시스템의 검색 품질을 결정짓는 핵심 요인임을 시사합니다.
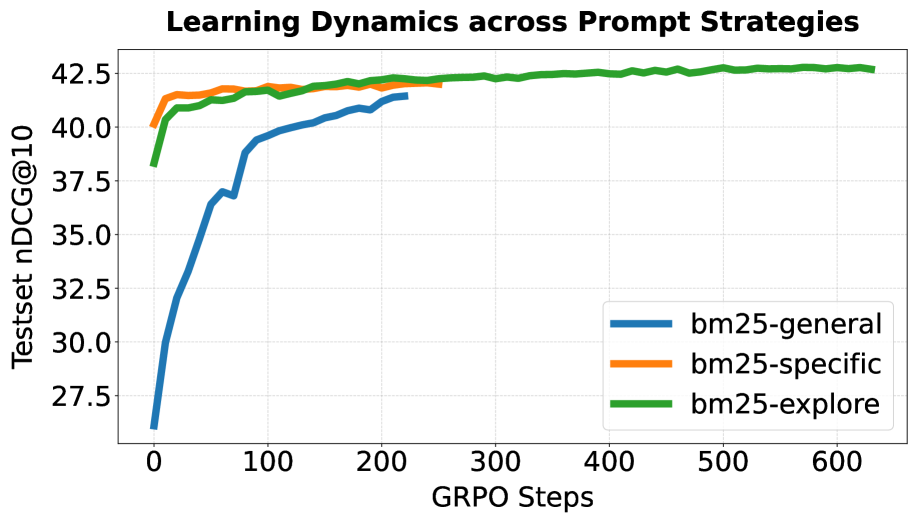
Figure 2 — 모델의 쿼리 전략 발견 과정
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM의 쿼리 생성 능력이 Retriever의 특성과 밀접하게 상호작용해야 한다는 점을 체계적으로 증명하였습니다. 연구 결과, Retriever 간의 성능 차이는 검색 의도의 차이(Semantic)가 아닌 쿼리 형식의 차이(Structural)에서 기인한다는 'Structural Drift' 현상을 규명하였습니다. 이는 향후 RAG 시스템 구축 시 단순히 모델 성능을 키우는 것뿐만 아니라, 시스템이 사용하는 Retriever 환경에 맞는 맞춤형 쿼리 최적화가 필수적임을 시사합니다. 본 연구에서 제안된 Branching Rollout과 Retriever-aware RL 프레임워크는 보다 안정적이고 지능적인 Agentic RAG 시스템을 구축하려는 학계 및 산업계 실무자들에게 강력한 가이드라인을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unified Personalized Reward Model for Vision Generation
- [논문리뷰] Scaling Open-Ended Reasoning to Predict the Future
- [논문리뷰] Multi-hop Reasoning via Early Knowledge Alignment
- [논문리뷰] TTRV: Test-Time Reinforcement Learning for Vision Language Models
- [논문리뷰] Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation
Review 의 다른글
- 이전글 [논문리뷰] Thinking with Visual Grounding
- 현재글 : [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- 다음글 없음
댓글