[논문리뷰] AGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Honglin Guo, Qi Zhang, Yu Zhang, Weijie Li, Rui Zheng, Zhikai Lei, Qiyuan Peng, Zhiheng Xi, Tao Gui, Qi Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Archive-grounded reasoning: 모델이 학습된 파라미터 지식이 아닌, 주어진 고정된 문서 아카이브 내에서 정보를 찾고 추론하여 답변을 도출하는 능력입니다.
- Agentic exploration: 대규모 문서 데이터셋에서 모델이 스스로 탐색 전략을 계획하고, 여러 파일에 걸쳐 분산된 증거를 통합하여 복잡한 문제를 해결하는 과정입니다.
- Multi-hop Question Answering: 단순히 단일 문서 내에서 정보를 찾는 것이 아니라, 여러 문서에 흩어진 파편적 정보를 연결하고 단계를 거쳐야만 답을 얻을 수 있는 작업 형태입니다.
- Verifiable evaluation: 정성적인 평가 대신, 고유한 Numeric Answer를 사전에 정의하여 별도의 인간 개입 없이 결정론적으로 성능을 자동 측정하는 평가 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 LLM 기반 에이전트가 기업 내부의 방대한 문서 아카이브에서 실질적인 지식 업무를 수행하는 데 필요한 Archive-grounded reasoning 능력을 평가하기 위해 Agora를 제안한다. 기존의 Multi-hop QA 벤치마크는 주로 Wikipedia와 같은 동질적인 환경에 국한되어 있으며, 문서 큐레이션 및 탐색 능력을 평가하는 에이전트 벤치마크는 주로 오픈 웹 환경을 다루어 실무적인 기업 환경의 복잡성을 충분히 반영하지 못한다 [Table 1]. 따라서 저자들은 데이터가 흩어져 있고 단위나 시간 관점이 불일치하는 등, 현실적인 기업 환경에서 에이전트가 탐색, 추론, 검증을 완벽히 수행하는지를 측정하고자 한다 [Figure 2].
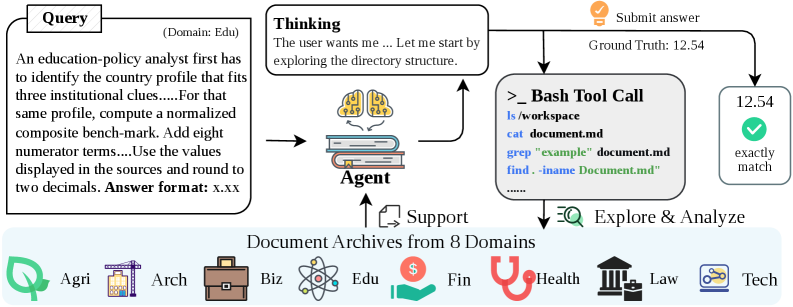
Figure 2 — Agora 작업 환경 및 에이전트 워크플로우
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 8개 전문 도메인에 걸쳐 9,664개의 실제 문서와 372M Tokens로 구성된 Agora 벤치마크를 구축하고, 이를 통해 에이전트의 성능을 엄격히 평가한다. 벤치마크 구축 과정은 데이터 수집 및 전처리, Agentic pipeline을 활용한 과제 합성, 난이도 필터링 및 인간 검증을 포함한 3단계 프로세스를 거쳐 정교화된다 [Figure 3]. 성능 평가를 위해 8개의 모델을 mini-swe-agent 환경에 배치하여 테스트한 결과, 최고 성능을 기록한 Gemini-3.1-Pro조차 59.39%의 Accuracy를 달성하는 데 그쳤다 [Table 3]. 실험 결과, 모델들은 도메인별로 상당한 성능 편차를 보였으며, 특히 Frontier-tier 모델군과 하위 모델군 간의 성능 격차가 매우 큼이 확인되었다 [Figure 4]. 실패 모드 분석을 통해 대부분의 오류가 탐색 및 증거 추출 과정에서 발생하는 Incomplete Inspection 및 Evidence Misidentification에 집중되어 있음을 발견하였다 [Figure 5].
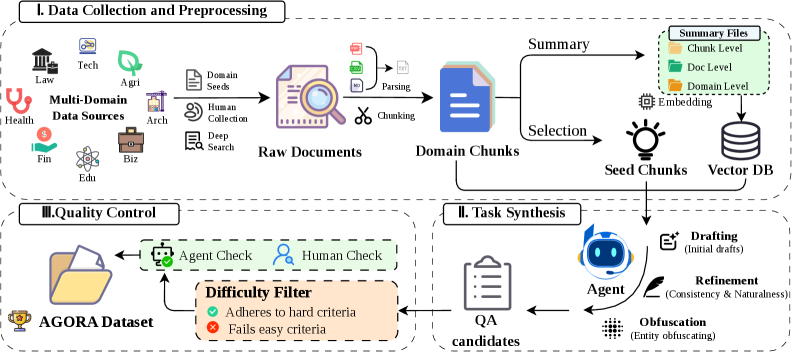
Figure 3 — Agora 벤치마크 구축 파이프라인
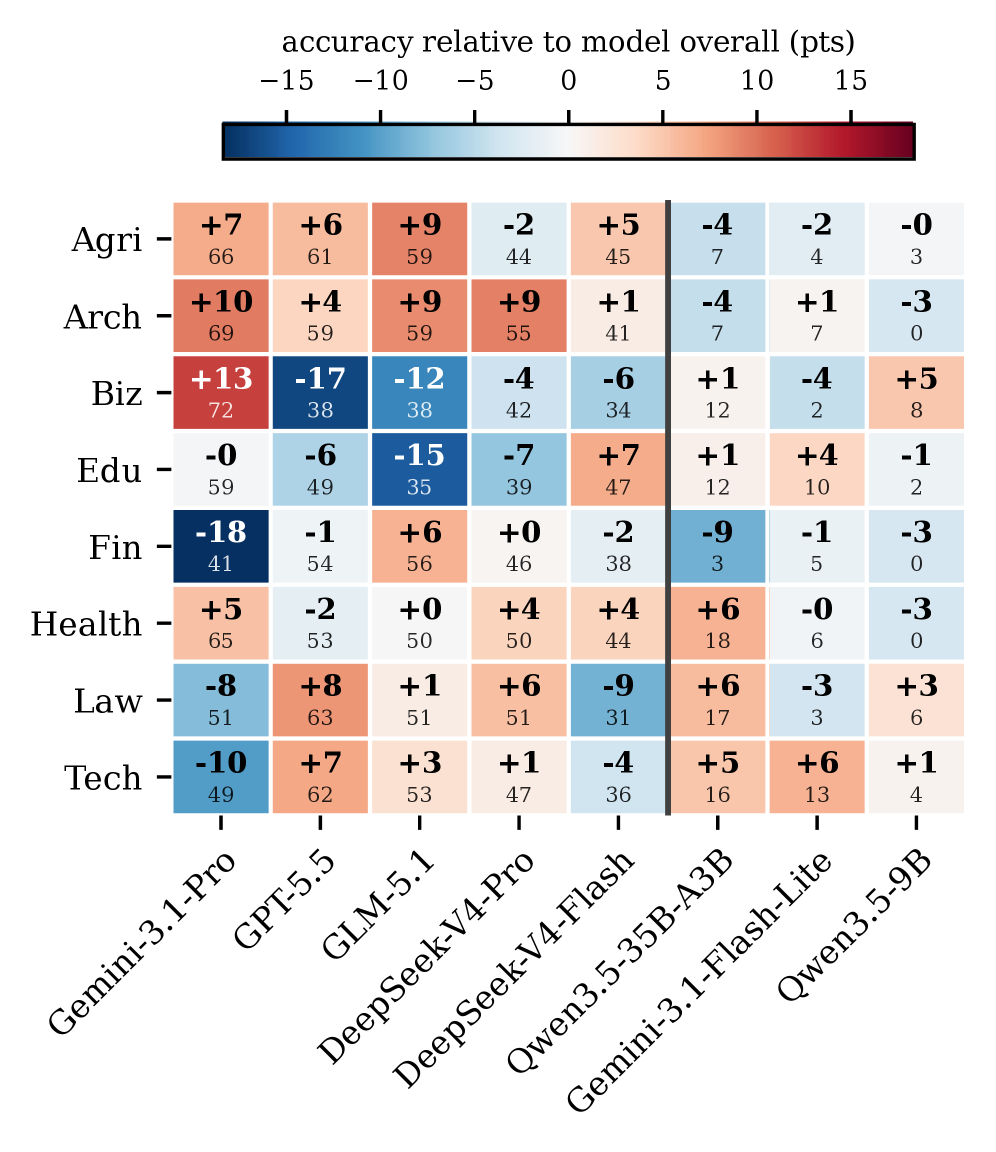
Figure 4 — 모델별 도메인 내 상대적 정확도(Residual)
4. Conclusion & Impact (결론 및 시사점)
본 논문은 기업 내 복잡한 문서 기반 업무를 수행하는 에이전트의 능력을 체계적으로 측정할 수 있는 Agora 벤치마크를 정립하였다. 연구 결과는 현재의 최첨단 모델들조차 실무적인 Archive-grounded reasoning 작업에서 상당한 한계를 보이고 있음을 시사한다. 이 벤치마크는 향후 모델들이 단순한 정보 검색을 넘어 실질적인 Agentic 업무 해결 능력을 갖추도록 독려하는 중요한 기준점이 될 것으로 기대된다. 또한, 단일 도메인 벤치마크로는 드러나지 않는 모델의 도메인별 편향과 성능 한계를 명확히 규명함으로써, 더욱 견고한 추론 능력을 가진 에이전트 개발에 기여할 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
- [논문리뷰] EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
- [논문리뷰] Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
- [논문리뷰] Video-BrowseComp: Benchmarking Agentic Video Research on Open Web
- [논문리뷰] VCode: a Multimodal Coding Benchmark with SVG as Symbolic Visual Representation
Review 의 다른글
- 이전글 [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- 현재글 : [논문리뷰] AGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
- 다음글 [논문리뷰] AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
댓글