[논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhongzhu Zhou, Qingyang Wu, Junxiong Wang, Mayank Mishra, Shuaiwen Leon Song, Ben Athiwaratkun, Chenfeng Xu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Gated DeltaNet (GDN): Softmax attention의 KV cache 문제를 해결하기 위해 도입된, 고정된 크기의 재귀적 상태(recurrent state)를 사용하는 효율적인 선형 어텐션 아키텍처입니다.
- Taylor-Calibrate: 사전에 학습된 Transformer의 어텐션 통계를 Taylor expansion 기반으로 분석하여 GDN의 재귀적 파라미터(decay, write gate, output gate)를 초기화하는 방법론입니다.
- Per-Layer Alignment: 사전에 계산된 파라미터로 초기화한 후, 각 레이어의 GDN 출력을 Teacher 모델의 레이어 출력과 일치시키기 위해 짧은 단계의 로컬 정렬을 수행하는 과정입니다.
- Projection Copying: 기존 Transformer의 Q, K, V, O 가중치를 새로운 하이브리드 학생 모델에 그대로 복사하는 보편적인 초기화 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 하이브리드 모델로의 전환 시 발생하는 부적절한 재귀적 파라미터 초기화 문제를 해결하고자 합니다. 기존 연구들은 Transformer의 가중치를 복사하는 데 집중하지만, 새롭게 도입되는 GDN의 동역학(decay, gate 등)을 고려하지 않아 초기 모델이 최적화되지 않은 상태에서 학습을 시작하게 됩니다 [Figure 1]. 이러한 초기화 오류는 Distillation 과정에서 불필요한 토큰 소비를 야기하며, 모델이 Teacher의 동작을 모방하는 대신 무작위 상태에서 시작하여 성능 복구에 어려움을 겪게 합니다 [Figure 1].
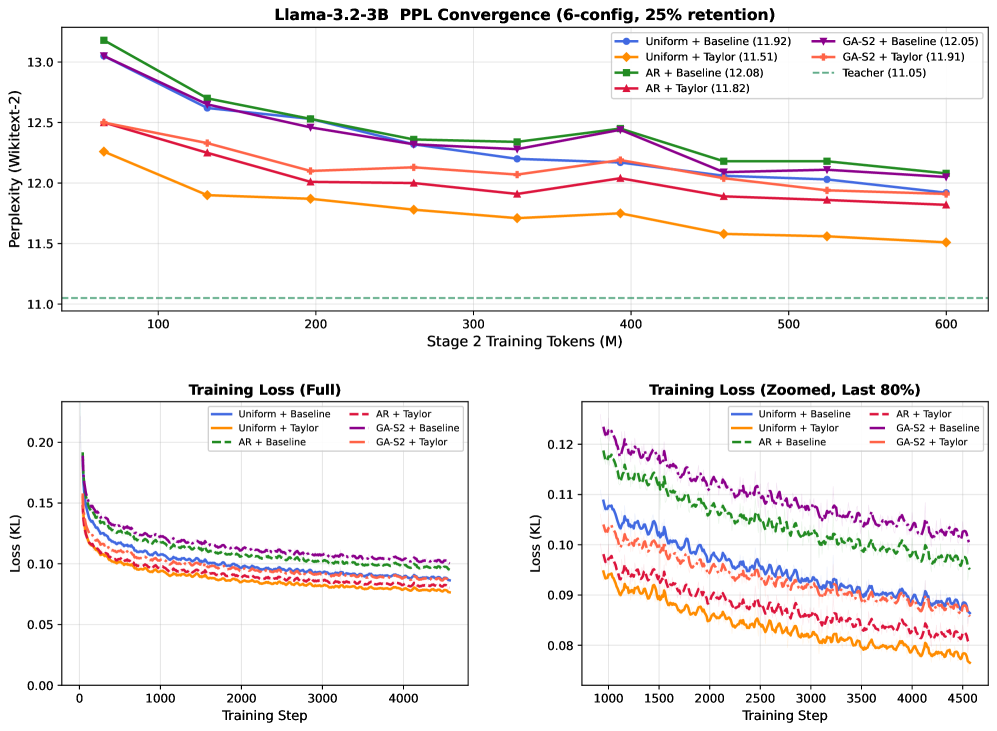
Figure 1 — 초기화 방식에 따른 성능 차이
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Teacher 모델의 어텐션 통계를 분석하여 GDN 파라미터를 결정하는 Taylor-Calibrate 기법을 제안합니다 [Figure 2]. 첫 번째 단계에서는 Taylor expansion을 통해 얻은 지표(평균 어텐션 거리, 엔트로피 등)를 사용하여 decaying factor와 gating 파라미터를 분석적으로 설정합니다 [Table 1]. 두 번째 단계에서는 Calibration 데이터를 사용하여 각 converted layer가 Teacher의 출력과 유사하도록 로컬 정렬을 수행합니다 [Figure 2]. 주요 실험 결과, Taylor-Calibrate는 naive 초기화 대비 제로샷(Zero-shot) 환경에서 PPL 성능을 최대 88배까지 개선하는 성과를 보였습니다. 또한, 동일한 목표 성능에 도달하기 위해 필요한 학습 토큰 수를 기존 방식 대비 4.9배에서 9.2배까지 단축시키는 높은 효율성을 달성했습니다 [Figure 5].
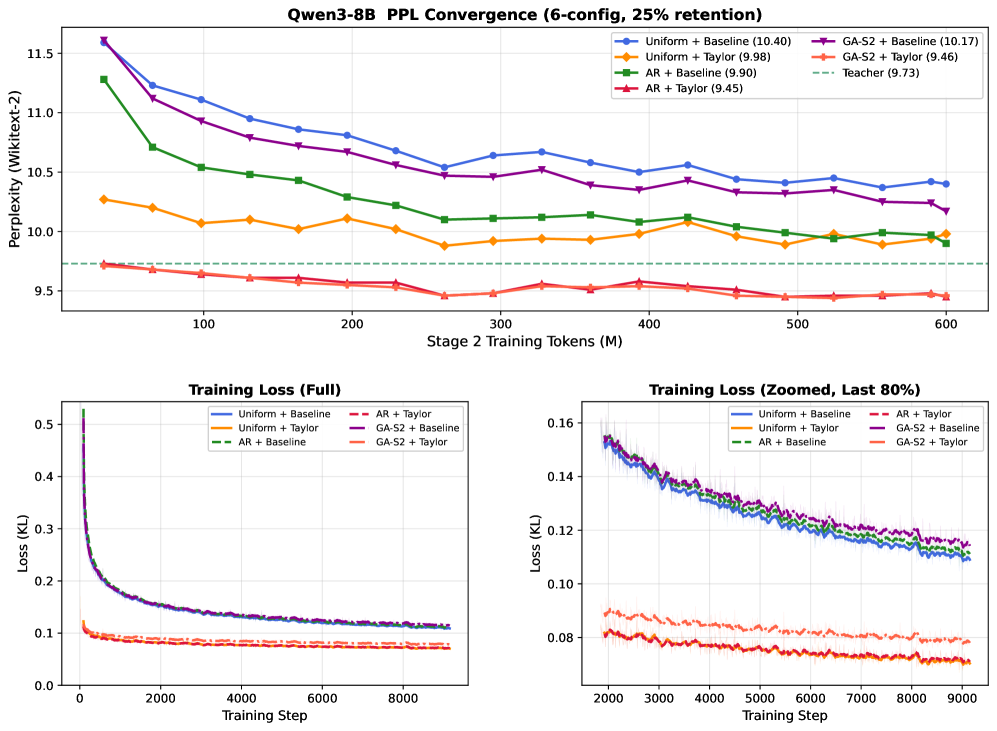
Figure 2 — Taylor-Calibrate 전체 파이프라인
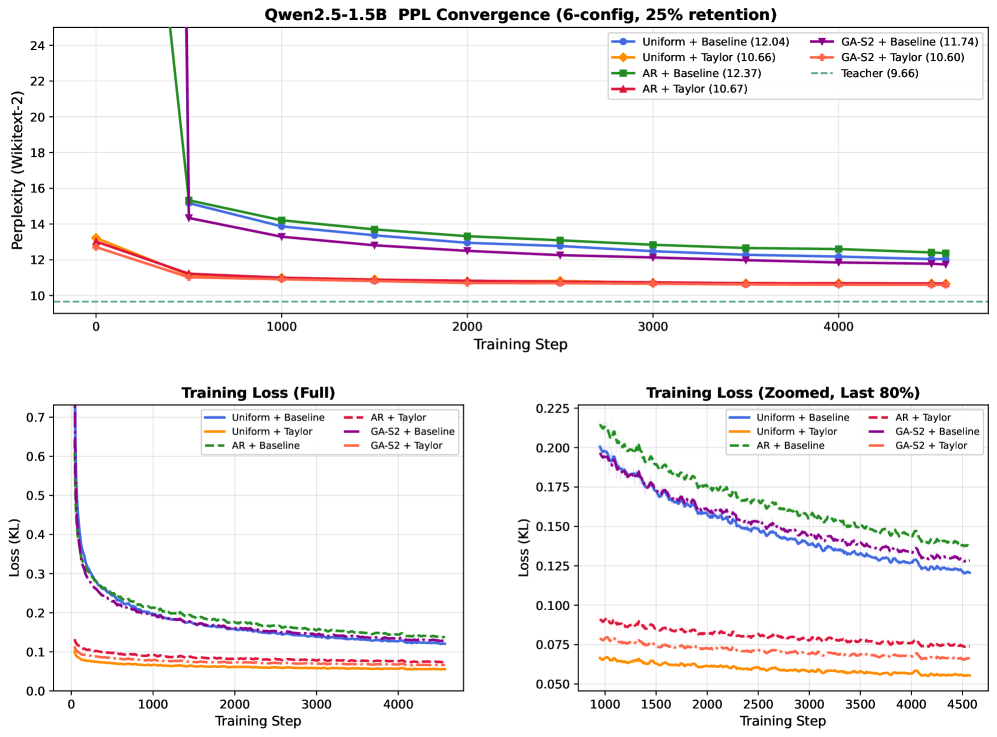
Figure 5 — 학습 토큰 효율성 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 하이브리드 선형 어텐션 모델로의 효율적인 전환을 위해 단순한 가중치 복사가 아닌 재귀적 동역학의 초기화가 필수적임을 입증했습니다. 제안된 Taylor-Calibrate는 구조적 전환 비용을 획기적으로 낮추어 대규모 모델을 보다 빠르게 효율적인 추론 아키텍처로 변환 가능하게 합니다. 이는 학계와 산업계에서 거대 언어 모델의 추론 효율성을 최적화하는 데 중요한 실무적 가이드라인을 제공합니다. 향후 연구에서는 본 Calibration 프레임워크를 다른 선형 어텐션 모델 계열로 확장하는 방향을 모색할 수 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
- [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] A Stationary (and Therefore Compatible) Representation is All You Need
Review 의 다른글
- 이전글 [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
- 현재글 : [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- 다음글 [논문리뷰] Thinking with Visual Grounding
댓글