[논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: WonJun Moon, Jae-Pil Heo
1. Key Terms & Definitions (핵심 용어 및 정의)
- VOCL (Video Object-Centric Learning): 영상을 구성하는 객체들을 개별 슬롯(Slot) 단위로 분해하여 구조화된 표현을 학습하는 프레임워크입니다.
- Encoder-Decoder Bias Misalignment: 인코더의 주의 맵(Attention Map)이 경계는 날카롭지만 노이즈가 많고, 디코더의 객체 맵(Object Map)이 경계는 모호하지만 공간적으로 일관적인 특성을 보이는 구조적 불일치를 의미합니다.
- Selective Alignment Principle: 양측 모듈의 모든 정보를 단순히 정렬하는 대신, 각 모듈이 신뢰할 수 있는 특정 영역(경계 또는 내부)만을 선택적으로 증류(Distillation)하는 방법론입니다.
- Transitive Pseudo-Label Merging: 시공간적 활성화 일관성을 바탕으로 중복된 슬롯들을 그룹화하여, over-fragmentation 문제를 완화하고 일관된 객체 표현을 유지하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VOCL 연구에서 encoder와 decoder 사이의 구조적 비대칭성으로 인해 발생하는 학습 불안정성과 정보 정렬의 비효율성을 해결합니다. 기존의 SRL(Slot Refinement Learning) 등은 모든 시공간 패치에 대해 Dense Contrastive Alignment를 수행하는데, 이는 구조적 결함을 가진 영역까지 강제로 정렬시켜 오류를 전파하는 부작용을 낳습니다 [Figure 1]. 또한, 모든 패치 간 유사도를 계산하는 과정에서 발생하는 이차 복잡도($\mathcal{O}((T \cdot H \cdot W)^2)$)는 고해상도 영상이나 긴 시퀀스 학습에 있어 심각한 확장성 제한을 초래합니다. 저자들은 이러한 indiscriminate alignment가 각 모듈의 고유한 약점을 강화한다고 지적하며, 신뢰할 수 있는 영역만을 필터링하여 정렬하는 새로운 전략이 필요함을 강조합니다.
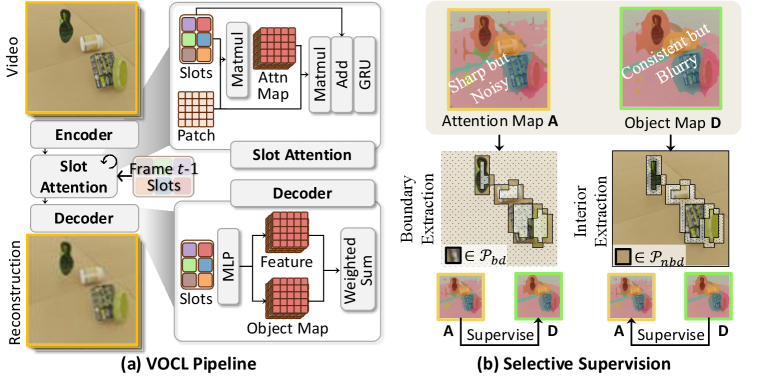
Figure 1 — SSync의 전체 흐름과 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SSync(Selective Synergistic Learning)를 통해 encoder의 경계 날카로움과 decoder의 내부 일관성을 상호 증류하는 선택적 정렬 프레임워크를 제안합니다 [Figure 1]. SSync는 시공간적 활성화를 기반으로 경계 영역과 내부 영역을 구분하여, 경계에서는 인코더 기반의 Pseudo-label로 디코더를 지도하고, 내부 영역에서는 디코더 기반의 Pseudo-label로 인코더를 노이즈 제거하는 비대칭 교차 증류를 수행합니다 [Figure 2]. 또한, Transitive Pseudo-Label Merging을 도입하여 중복된 슬롯들을 연결 요소(Connected Components) 그래프로 식별하고 하나로 통합함으로써, 과도한 파편화(Over-fragmentation) 문제를 효과적으로 제어합니다. 실험 결과, SSync는 MOVi-C 및 MOVi-E 벤치마크에서 FG-ARI 및 mBO 지표 기준 최신 연구들을 상회하는 성능을 달성하였습니다 [Table 2]. 특히 SRL 대비 메모리 효율성을 비약적으로 개선하여, 동일 환경에서 배치 사이즈를 더 크게 운용하거나 OOM 문제 없이 학습이 가능함을 입증하였습니다 [Table 5].
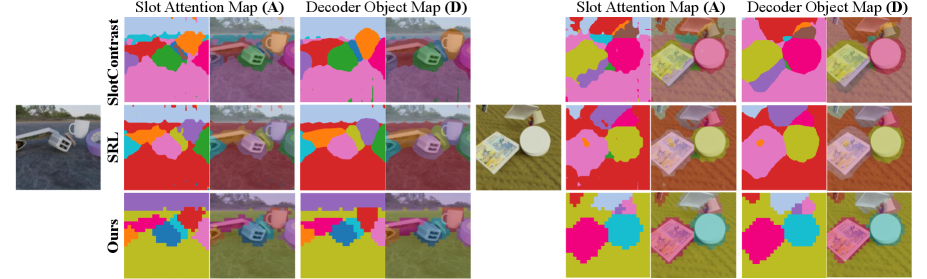
Figure 2 — Attention 및 Object Map 시각화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 선택적 정렬 원칙과 전이적 병합 기법을 통해 VOCL에서의 encoder-decoder 불일치 문제를 해결하였습니다. SSync는 별도의 복잡한 아키텍처 추가 없이 기존 슬롯 기반 모델에 즉시 적용 가능한 Plug-and-Play 모듈로서 높은 실용성을 가집니다. 이 연구는 객체 중심 학습에서 정보 전달의 효율성과 신뢰성을 동시에 확보함으로써, 향후 구조화된 영상 이해 및 객체 편집 기술 발전에 중요한 기여를 할 것으로 기대됩니다.

Figure 3 — MOVi-C에서의 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning Image-based Tree Crown Segmentation from Enhanced Lidar-based Pseudo-labels
- [논문리뷰] VideoMaMa: Mask-Guided Video Matting via Generative Prior
- [논문리뷰] Boosting Unsupervised Video Instance Segmentation with Automatic Quality-Guided Self-Training
- [논문리뷰] Pseudo2Real: Task Arithmetic for Pseudo-Label Correction in Automatic Speech Recognition
- [논문리뷰] D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
Review 의 다른글
- 이전글 [논문리뷰] S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
- 현재글 : [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
- 다음글 [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
댓글