[논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yue Zhang, Zun Wang, Han Lin, Yonatan Bitton, Idan Szpektor, Mohit Bansal
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- SpatialUncertain: 3D 시뮬레이션 환경을 기반으로 구성된, VLMs의 관측 불확실성(Observational Uncertainty)을 평가하기 위해 설계된 제어된 평가 프레임워크입니다.
- Occlusion: 타겟 정보가 가려져 모델이 완전한 정보를 얻을 수 없는 상태를 유도하는 실험적 제약 조건입니다.
- Perspective Ambiguity: 카메라 위치를 이동시켜 기하학적 정보가 왜곡되거나 오해의 소지가 있는 시각적 단서를 제공하는 실험적 설정입니다.
- ViewSel (View Selection): 모델이 주어진 여러 시점 중 가장 신뢰할 수 있는 정보를 제공하는 최적의 관측 시점을 선택할 수 있는지 평가하는 작업입니다.
- Abstention: 모델이 충분한 시각적 근거를 확보하지 못했거나 관측이 신뢰할 수 없다고 판단될 때, 무리하게 답변하지 않고 "Cannot determine"을 선택하는 능력입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 spatial reasoning 벤치마크들이 시각적 관측이 항상 충분하고 신뢰 가능하다는 비현실적인 가정에 의존하고 있다는 점을 지적합니다. 3D 현실 세계에서는 occlusion이나 perspective ambiguity로 인해 관측 데이터가 누락되거나 왜곡될 수 있으며, 이러한 상황에서 모델이 답변을 회피하거나 추가적인 정보를 탐색하는 능력이 필수적입니다 [Figure 1]. 그러나 기존 연구들은 주로 답변의 정확도에만 집중하여, 모델이 스스로의 인지적 한계를 인지하고 행동하는지(i.e., uncertainty awareness)를 평가하지 못하는 한계가 있습니다. 이에 저자들은 모델이 불확실한 시각적 근거를 인식하고, 신뢰할 수 있는 정보를 찾기 위해 어떻게 행동해야 하는지를 체계적으로 진단하기 위해 본 연구를 수행하였습니다.
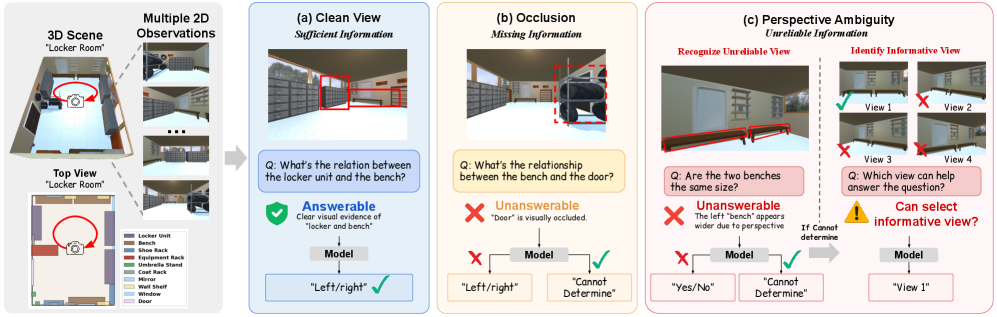
Figure 1 — 3D 세계의 관측 조건
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 AI2-THOR 기반의 3D 환경을 활용하여, 동일한 spatial question이 관측 조건에 따라 답변 가능(answerable) 상태에서 답변 불가능(unanswerable) 상태로 전환되도록 설계된 SpatialUncertain 프레임워크를 제안합니다 [Figure 2]. 실험 결과, GPT-4o, GPT-5.4, Gemini-3.0-Flash를 포함한 8개의 최신 VLM들은 시각적 증거가 불충분함에도 불구하고 높은 자신감으로 답변을 생성하는 경향을 보이며, occlusion 상황에서는 정확도가 약 30%, perspective ambiguity 상황에서는 10% 미만으로 급락하는 failure mode를 확인했습니다 [Table 1]. 특히, 시각적 입력 정보가 결여되었을 때는 모델의 abstention을 돕기도 하지만, perspective ambiguity와 같이 왜곡된 정보를 제공할 경우 오히려 모델의 올바른 판단을 방해하여 abstention 능력을 저하시키는 것으로 나타났습니다. 또한, structured prompting만으로는 abstention 성능 향상과 답변 정확도 간의 trade-off를 해결하지 못했으나, 다양한 모호성 조건을 포함한 데이터로 fine-tuning을 수행한 모델은 이러한 trade-off 없이 더 견고한 observational uncertainty 성능을 확보할 수 있음을 입증했습니다.
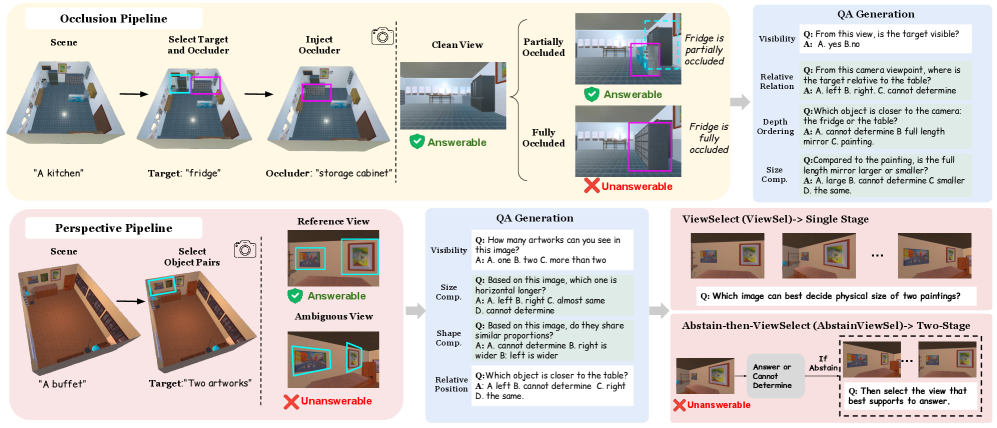
Figure 2 — SpatialUncertain 프레임워크
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 최신 VLM들이 spatial reasoning 과정에서 관측의 신뢰성을 판단하고 불확실성을 적절히 표현하는 데 근본적인 한계를 가지고 있음을 밝혀냈습니다. 제안된 SpatialUncertain 프레임워크를 통해 모델들이 신뢰할 수 없는 정보 앞에서 과도한 자신감을 보이는 failure mode를 규명하였으며, 이는 embodied agent나 로봇 공학과 같은 안전이 중요한 분야에서 위험한 결과를 초래할 수 있음을 시사합니다. 향후 연구는 단순히 답변 정확도를 높이는 것을 넘어, 모델 스스로 정보의 부족을 인지하고 추가적인 관측을 능동적으로 모색하는 uncertainty-aware한 모델링으로 전환되어야 함을 강력히 촉구합니다.
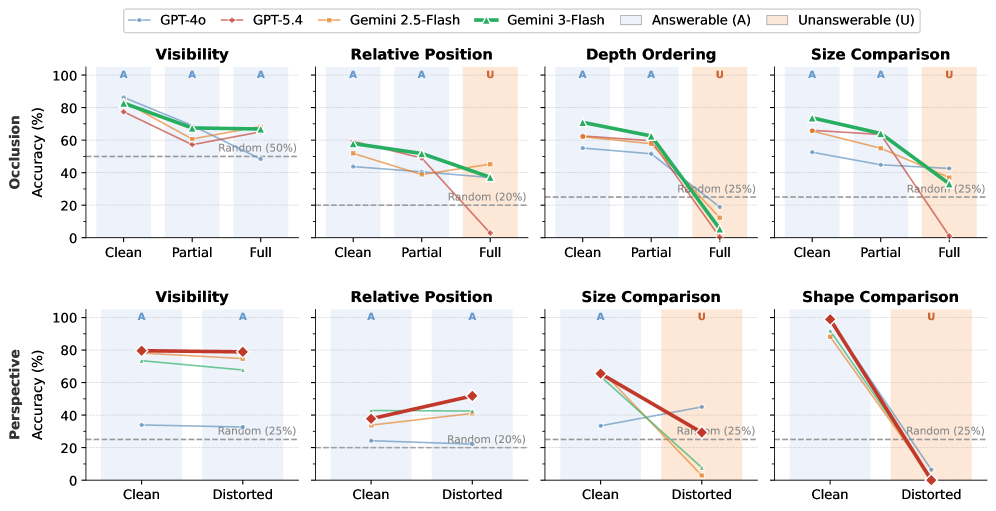
Figure 5 — 모델 유형별 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] Unlocking Dense Metric Depth Estimation in VLMs
Review 의 다른글
- 이전글 [논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
- 현재글 : [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
- 다음글 [논문리뷰] SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones?
댓글